摘要: TensorFlow Lite+OpenCV实现移动端水印的检测与去除 闲鱼技术:镇雷 概要: 本篇文章介绍了TensorFlow Lite与OpenCV配合使用的一个应用场景,并详细介绍了其中用到的SSD模型从训练到端上使用的整个链路流程。
TensorFlow Lite+OpenCV实现移动端水印的检测与去除
概要:
本篇文章介绍了TensorFlow Lite与OpenCV配合使用的一个应用场景,并详细介绍了其中用到的SSD模型从训练到端上使用的整个链路流程。在APP中的使用场景为,用户在发布图片时,在端上实现水印的检测和定位,并提供去水印的功能。
具体步骤有:
1,使用TensorFlow Object Detection API进行SSD模型的训练
2,模型的优化和转换,模型在端上的解析使用(本篇主要使用iOS端的C++代码作为示例)
3,将输出locations值通过NMS(非极大值抑制)算法得到最优的框
4,使用OpenCV去除水印
使用的库及工具:
1、TensorFlow v:1.8r +
2、TensorFlowLite v:0.0.2 +
3、OpenCV
4、labelImg

SSD检测并定位水印
SSD简介
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越)。SSD具有如下主要特点:
1,从YOLO中继承了将detection转化为regression的思路,同时一次即可完成网络训练
2,基于Faster RCNN中的anchor,提出了相似的prior box
3,加入基于特征金字塔(Pyramidal Feature Hierarchy)的检测方式,相当于半个FPN思路
TensorFlow Object Detection API提供了多种目标检测的网络结构预训练的权重,全部是用COCO数据集进行训练,各个模型的精度和计算所需时间如下:

我们直接使用TensorFlow提供的模型重训练,可以专注于工程不用重新构建网络,本文选用模型为SSD-300 mobilenet-based
1.1 模型的训练
1,配置环境
1.1 下载TensorFlow Object Detection API代码库,Git地址:https://github.com/tensorflow/models.git
1.2 编译protobuf库,用来配置模型和训练参数,下载直接编译好的pb库(https://github.com/google/protobuf/releases ),解压压缩包后,添加环境变量:

1.3 将models和slim加入python环境变量:
2,数据准备
TensorFlow Object Detection API训练需要标注好的图像,推荐使用labelImg,是一个开源的图像标注工具,下载链接:https://github.com/tzutalin/labelImg。标注完样本之后会生成一个xml的标注文件,这些xml文件我们需要最终转换为训练用的TFRecord类型文件,GitHub上有个demo提供了很方便的转换脚本(https://github.com/datitran/raccoon_dataset)。我们把这些标注的xml文件,按训练集与验证集分别放置到两个目录下,通过下载的xml_to_csv.py脚本转换为csv结构数据。然后使用转换为TFRerord格式的脚本:generate_tfrecord.py把对应的csv格式转换成.record格式。
labelImg界面:
3,训练
打开下载后的coco数据集预训练模型的文件夹,把model.ckpt文件放置在待训练的目录,修改ssd_mobilenet_v1_pets.config文件中的两个地方:
1,num_classes:修改为自己的classes num
2,将所有PATH_TO_BE_CONFIGURED的地方修改为自己之前设置的路径
调用train.py开始训练:

pipeline_config_path是训练的配置文件路径
train_dir是训练输出的路径
1.2 模型的优化和转换
最后将训练得到的pb模型,使用官方的optimize_for_inference优化,再用toco转换为tflite模型(路径需要修改),参照官方GitHub更新的这个Issues:

1.3 tflite 端上执行ssd
我们在这个案例中使用的ssd_mobilenet.tflite模型,输入输出数据类型为float32。SSD中没有全连接层,可适应各种大小的图片,我们的这个模型取的shape是{1, 300, 300, 3}。
图片输入的代码如下:

输出的结构是包含Locations和Classes的数组,代码如下:

通过遍历输出,并使用sigmoid激活函数,得到score,保存大于0.8时的class与location的index
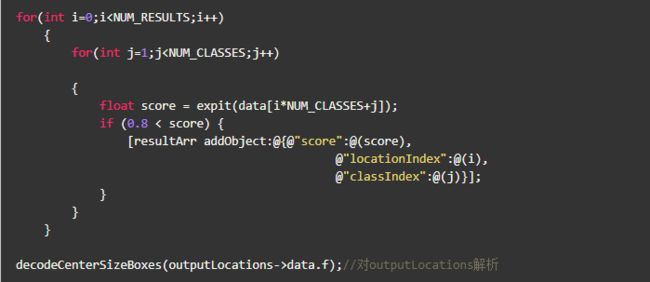
outputLocations解析:

通过上述方法处理,outputLocations->data.f 4个值一组表示输出的矩形框左上角和右下角坐标,然后遍历resultArr取score大于0.8时对应的classIndex与locationIndex,再通过如下代码得到框的坐标并输出识别出的类别与分数:

1.4 非极大值抑制(NMS)

解析之后,一个物体会得到了多个定位的框,如何确定哪一个是我们需要的最准确的框呢?我们就要用到非极大值抑制,来抑制那些冗余的框:抑制的过程是一个迭代-遍历-消除的过程。
1,将所有框的得分排序,选中最高分及其对应的框
2,遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。
3,从未处理的框中继续选一个得分最高的,重复上述过程。
处理之后:

OpenCV去水印
Opencv去水印有两种方法:
一种是直接用inpainter函数(处理质量较低,可以处理不透明水印),另一种是基于像素的反色中和(处理质量较高,只能处理半透明水印,未验证)
inpainter函数:
算法理论:基于Telea在2004年提出的基于快速行进的修复算法(FMM算法),先处理待修复区域边缘上的像素点,然后层层向内推进,直到修复完所有的像素点
处理方式:获取到黑底白色水印且相同位置的水印蒙版图(必须单通道灰度图),然后使用inpaint方法处理原始图像,因为SSD得到的定位大小很难完全精确,具体使用时可把mask水印区适当放大,因为这个方法的处理是从边缘往内执行,这样可以保证水印能完全被mask覆盖
通过水印位置和水印样式生成如下mask图(大小与原图保持一致)

处理之后:

基于像素的反色中和:
这种方法可以针对固定位置半透明水印做去除,算法原理是使用水印mask图,对加水印的图片做反向运算,计算出水印位置原来的颜色值。
总结
TensorFlow lite在4月份才做了对SSD的支持,目前文档比较缺乏,并且官方只提供了安卓实例,iOS的C++代码对输入输出的处理需要根据安卓demo的代码来推测,比如对结果中classes的解析以及对输出的框位置的解析,还有需要进行nms算法取最优等。还有一个问题就是由于TensorFlow更新比较快,TensorFlow Object Detection API中很多方法参数和路径各版本存在差异,需要注意。
在实际的应用中,水印的位置基本会比较固定,在图片的4个角或居中,所以在ssd检测过程中,后续可以考虑添加规则或者尝试使用注意力模型来增加四个角以及中间部分的处理权重,来提高效率和准确率。目前这个方法还存在一个问题,就是必须要提前知道水印的具体样式,并将包含这些水印的图片做训练,如果有新的水印就无法对其做出正确的识别和去除,后期我们会尝试通过GAN来直接修复图片的方式去水印,有做过相关尝试的欢迎一起探讨。
本文作者:闲鱼技术
阅读原文
本文为云栖社区原创内容,未经允许不得转载。