此文专门研究这篇文章
http://www.brendangregg.com/perf.html
它就是个perf大杂烩,信息量太大,慢慢看吧,以下是目录

要点
- 编译要支持frame pointer,-fno-omit-frame-pointer,否则从perf看到的栈是不完整的; 使用-O参数会omit frame pointer;对于kernel,可以用
CONFIG_FRAME_POINTER=y - 一种解决no frame pointer的方法是添加--call-graph dwarf选项,不过需要perf支持
- 如果处理器支持LBR(last branch record),可以采用它来获取有限层的栈桢
- -p选项在某些3.x内核上工作不正常,只有先统计所有的CPU(-a),再过滤出PID
perf用三种方式进行instrument:
- counting
- sampling: 事件数据写入kernel buffer,然后perf去读它,再写入perf.data,由report/script进行consume;有开销,频率越大,开销越大文件也越大;4.4内核支持用户编写BPF来嵌入,从而可以过滤数据以减少开销
- bpf: 用户自定义程序,运行在linxu 4.4+ kernel space,可以作过滤和总结之用
事件源
可用perf list来查看所有支持的事件
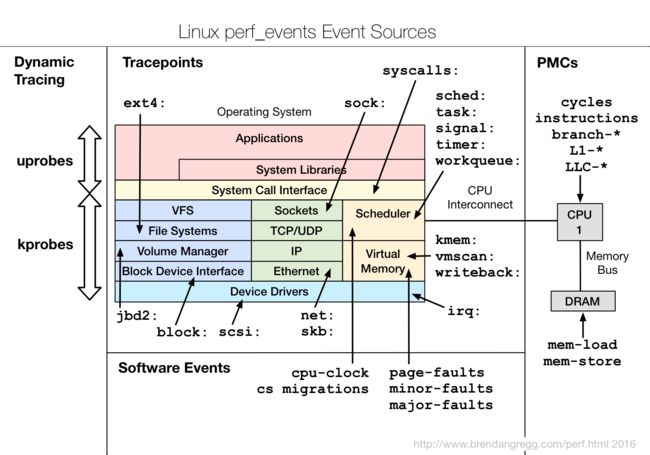
- static kernel tracepoints是硬编码进kernel的,它们方便于higher-level的分析,如tcp event, disk io, filesystem io, sched, syscall;
- USDT: 是指定用户级的静态tracing;
- dynamic tracing: 它可以trace everything,但是接口不稳定,kernel一打patch它很可能就不能用了;所以尽量先用static tracing;dynamic tracing的一个好处在于:它可以实时trace一个live system而不用重启任何程序。当结束会话后,需要把插入的instrumentation instructions给移除;开销与事件频率、工作量有关
例子
cpu Counting
pert stat
- -p:指定pid
- -I:指定interval
- -e 'sched:*': 指定特定事件
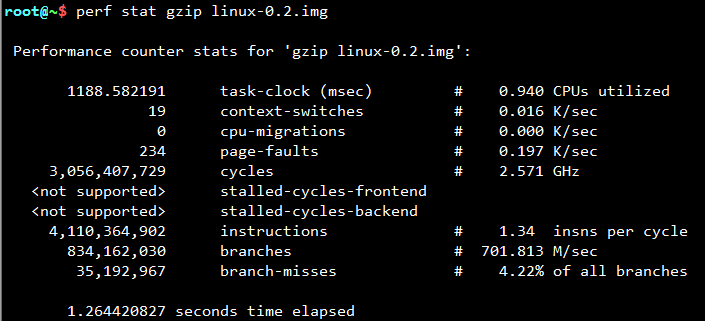
IPC(instructions per cycle),高代表指令吞吐量大,低代表stalled cycle多;
要了解以上术语,需要学习cpu microarchitecture,文档可参考《Intel 64 and IA-32 Architectures Software Developer's Manual Volume 3B: System Programming Guide, Part 2 》和《BIOS and Kernel Developer's Guide (BKDG) For AMD Family 10h Processors》;
硬件事件大多依赖于处理器模型, 在虚拟机环境下很多事件不适用
关于raw counter,是需要自己通过查看intel/amd手册来自行指定
stat命令的有些选项如--repeat, --sync, --pre, and --post非常适合用于自动化测试和微benchmark
Timed profiling(sampling)
perf record -F 99 -a -g -- sleep 10
- -e cycles:k: 指定on-CPU kernel instructions
比如以上命令就是以频率99 Hertz (-F 99), 对整个系统CPU (-a, for all CPUs), 带上栈桢 (-g, for call graphs), 持续10s

99hz是为了避免和系统中一些周期性任务相冲突,且要与系统时钟(100hz on linux)错开;可以选用更大的频率值如997以采集短暂的burst,但是开销也会大;
如果使用perf report --stdio,可以将perf record结果(下面这个结果是来自上面那个perf record命令,包括java程序,所以会complain在/tmp下找不到perf.map)显示在终端:
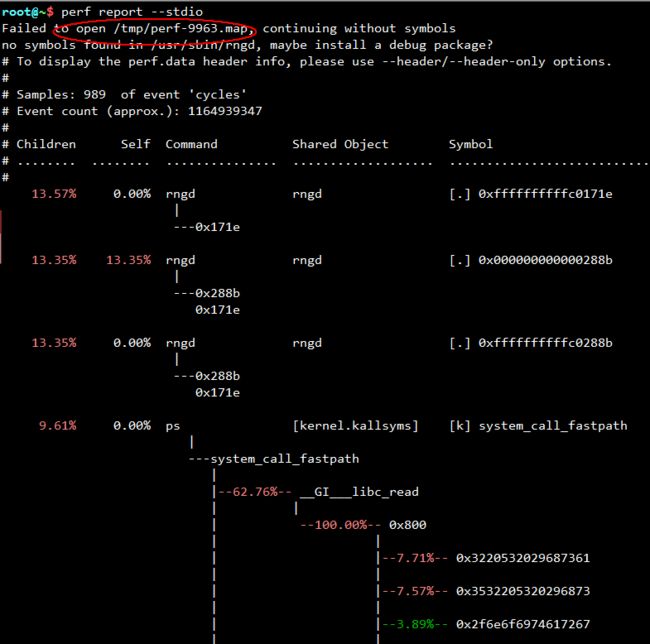
默认,左边的百分数是相对值,比如62.76%是相对于9.61%的,如果要用绝对比例,可以用-g(report的-g)
event profiling
这是由硬件触发的事件的profiling; 收集所有事件会造成太大开销,所以往往用-c来限制每多少次采集一次;
由于在硬件中断的读IP寄存器之间存储延迟,会导致采集出现偏差,用:p modifier可解决
静态kernel tracing
形式上是perf record + -e 【前面profiling也举了-e的例子,它与静态tracing是什么区别?】
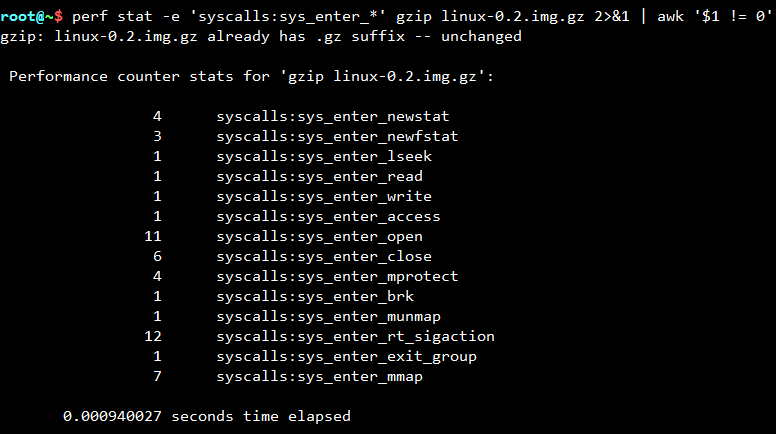
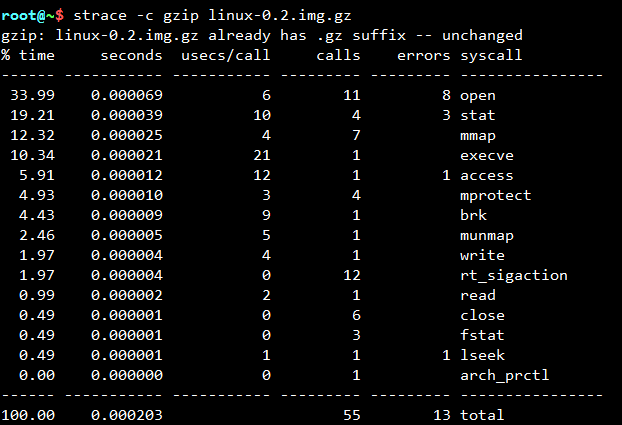
上述结果显示,有11次open调用,各有一次write,read调用
用strace -c也可达到相当效果,但开销比perf大:
比如用
perf record -e sched:sched_process_exec -a可跟踪调用exec()的调用
sched:sched_process_fork可trace fork()
perf record -e syscalls:sys_enter_connect -a可分析connect()
perf record -e 'skb:consume_skb' -ag可trace socket buffer
dynamic tracing
perf probe
有些选项需要kernel-debuginfo
-
trace tcp_sendmsg()
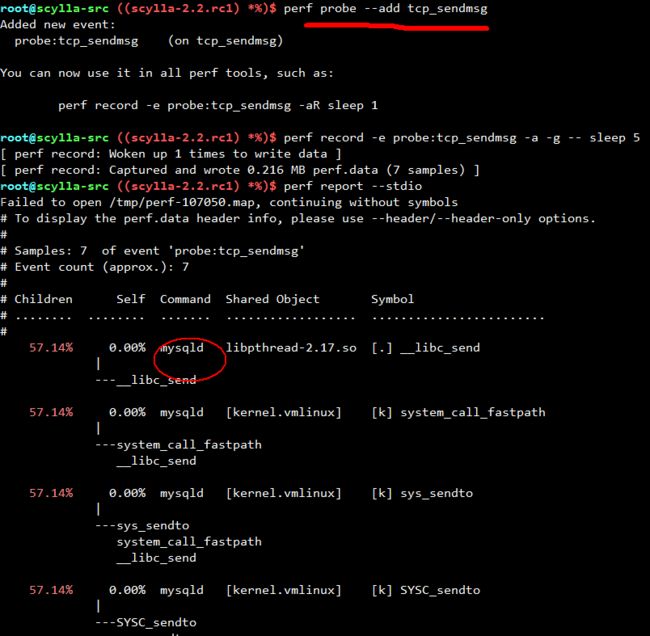 image.png
image.png
是mysqld占了tcp_sendmsg的大块部分
- trace函数内部的变量
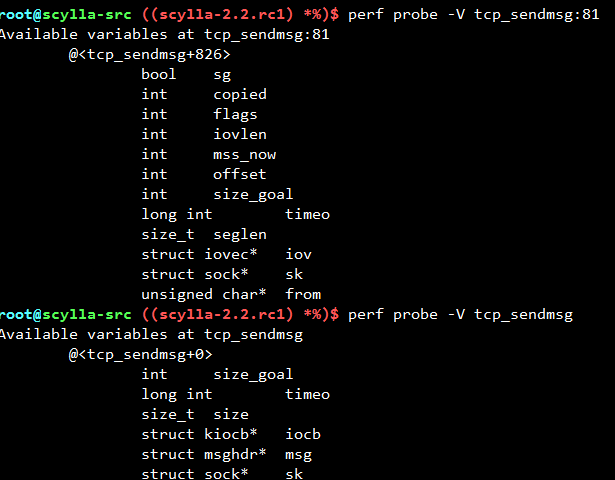
可以用probe -V列出可以显示哪些kernel 函数变量,比如对于tcp_sendmsg就有size变量,那么只要kernel编译时支持了DEBUG_INFO,就可以显示出每一次发生tcp_sendmsg时的size值; - trace源码某一行
用probe -L可以查看函数源码,
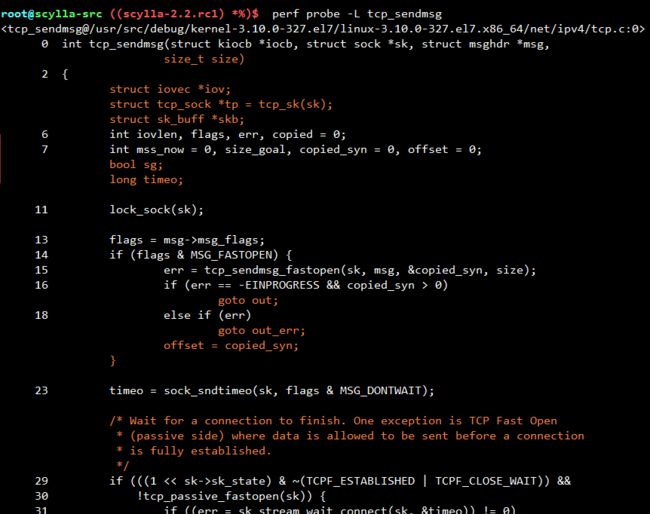 image.png
image.png
根据此源码,可以通过probe --add 'tcp_sendmsg:81 seglen',probe -e probe:tcp_sendmsg -a和perf script来检查在某一行某变量的变化;这功能碉堡了。。
另外,很显然指不指定行号,变量列表是不一样的,
-
trace malloc
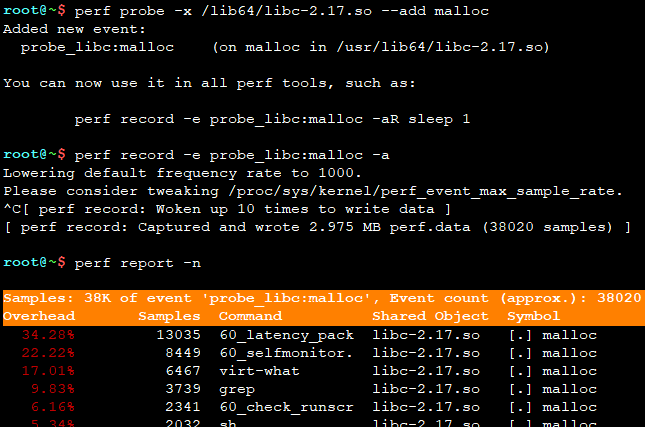 image.png
image.png
scheduler 分析
perf sched 支持多种子命令record, map, latency, replay, script
eBPF
从linux 4.4开始支持BPF,它使得perf tracing可以编程化
目前最方便使用的方式是bcc python接口(http://www.brendangregg.com/ebpf.html)
flame graph(另作分享)
文章地址:http://www.brendangregg.com/flamegraphs.html
github tools:https://github.com/brendangregg/FlameGraph
cpu flame graph: http://www.brendangregg.com/FlameGraphs/cpuflamegraphs
java in flames
heat maps(另作分享)
https://cacm.acm.org/magazines/2010/7/95062-visualizing-system-latency/fulltext
http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html