1.摘要
本文使用Python,对某航空公司的客户数据采用K-Means聚类算法,建立价值评估模型,对客户进行分组,以便于后续使用更有针对性的营销策略。
2.项目背景
根据航空公司已积累的数据,以2012-4-1至2014-3-31时间段作为观察窗口期,对客户进行价值识别,并对不同客户类别进行特征分析和价值比较。
3.数据说明
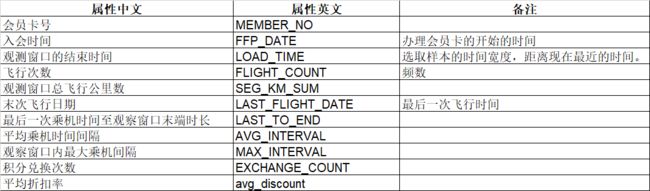
原始数据集共包含62988个客户数据,44个不同特征,包括会员卡号,入会时间,观测窗口内飞行次数,观测窗口总飞行公里数等。
表1为部分重要特征的说明。
4.数据处理
首先导入分析过程中会用到的第三方工具包。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
4.1数据探索
读取数据,并观察数据情况。
datafile = './air_data.csv'
data = pd.read_csv(datafile,encoding='utf-8')
data.info()

通过describe(),value_counts()等,可以发现
- 1.多列数据存在缺失值,特别是客户信息相关列。
- 2.存在票价为0,而飞行里程大于0的异常数据。
因问题数据所占比例小,可直接删除处理。
4.2数据清洗
丢弃少量异常数据
data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_1'].notnull()]
4.3属性规约
首先要说明一下,在识别客户价值方面,应用最广泛的模型是通过3个指标:
R(Recency,消费时间间隔)
F(Frequency,消费频率)
M(Monetary,消费金额)
来进行客户细分,简称RFM模型。
而对航空公司而言,航空票价受到运输距离,舱位等级等多种因素影响,同样消费金额的不同顾客有着不同的价值。例如,短航线,高等级舱位票的客户,价值要高于长航线,低等级舱位票的客户。所以,这里我们用飞行里程(M)和折扣系数平均值(D)来代替消费金额。另外,考虑到会员入会时间长短也会影响客户价值,所以在模型中增加客户关系时长L。
- Length:客户关系长度,入会时间距观测窗口结束的月数
- Recency:消费时间间隔,最近一次乘坐公司飞机距离窗口结束的月数
- Frequency:消费频率,在观测窗口内乘坐公司飞机的次数
- Mileage:飞行里程,在观测窗口内累计的飞行里程
- Discount:折扣系数平均值,在观测窗口内乘坐舱位所对应的折扣系数的平均值
留下与这五个指标相关的属性,删除其他属性。
data = data[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM',
'avg_discount']]
4.4数据变换
将剩下的属性,转换成我们所需的五个指标。
#数据变换
data['LOAD_TIME'] = pd.to_datetime(data['LOAD_TIME'])
data['FFP_DATE'] = pd.to_datetime(data['FFP_DATE'])
data['Length'] = (data['LOAD_TIME'] - data['FFP_DATE']).dt.days /12
data['Recency'] = data['LAST_TO_END']
data['Frequency'] = data['FLIGHT_COUNT']
data['Mileage'] = data['SEG_KM_SUM']
data['Discount'] = data['avg_discount']
#去除其他属性
data = data[['Length','Recency','Frequency','Mileage','Discount']]
data.describe()
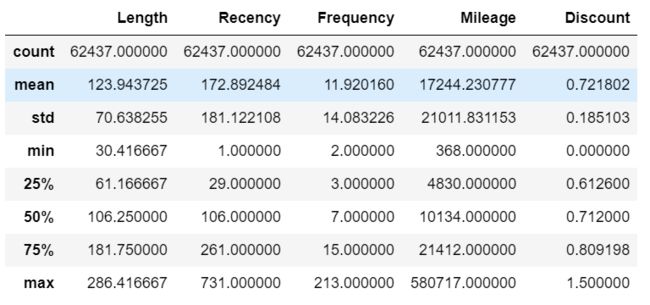
由上图可以看到,五个属性间的数据的取值范围存在较大差异,所以对数据进行标准差标准化。
data = (data - data.mean())/(data.std())
5.模型构建
采用K-Means聚类算法对客户进行分群。
首先用Elbow Method确定K值。
#肘部法,在1-10之间寻找合适K值
from sklearn.cluster import KMeans
d =[]
for i in range(1,11):
model = KMeans(n_clusters = i,)
model.fit(data)
d.append(model.inertia_)
#作折线图
plt.plot(range(1,11),d,marker='o')
plt.xlabel('number of clusters')
plt.ylabel('SSE')
plt.show()
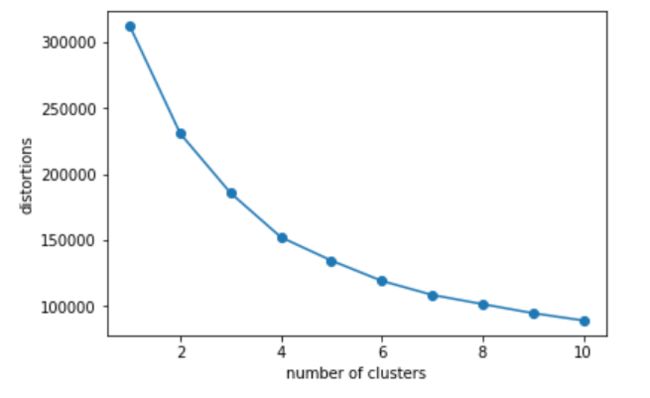
很可惜,从图上没能找到很明显的拐点。再结合对业务的理解,选择K分别取4,5,6时进行建模,来比较哪一个K值更合适。
以k=5为例:
#取k=5
k=5
model = KMeans(n_clusters = k)
model.fit(data)
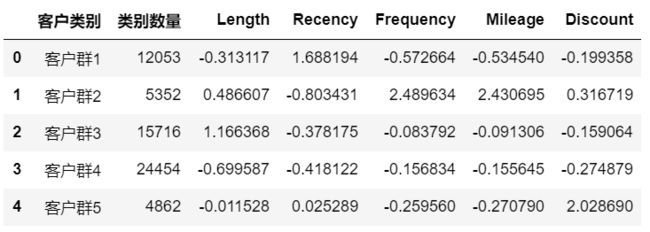
#查看聚类中心,聚类结果
r1 = pd.DataFrame(model.cluster_centers_)
r2 = pd.Series(model.labels_).value_counts()
r3 = pd.Series(['客户群1','客户群2','客户群3','客户群4','客户群5'])
r = pd.concat([r3,r2,r1],axis =1)
r.columns = [u'客户类别'] + [u'类别数量']+list(data.columns)
r
绘制聚类结果的雷达图,便于分析。
# 使中文在图中正常显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
#自定义雷达图函数
def radar_plot(r):
fig=plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, polar=True)
center_num = r.iloc[:,1:].values
feature = ['Length','Recency','Frequency','Mileage','Discount']
N =len(feature)
for i, v in enumerate(center_num):
angles=np.linspace(0, 2*np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭起来,需要下面的步骤
center = np.concatenate((v[1:],[v[1]]))
angles=np.concatenate((angles,[angles[0]]))
ax.plot(angles, center, 'o-', linewidth=2,
label = "客户群%d: %d人"% ((i+1),v[0]))
ax.fill(angles, center, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, feature, fontsize=15)
plt.title('客户群特征分析图', fontsize=20)
ax.grid(True)
plt.legend(loc='upper right', bbox_to_anchor=(1.4,1.0),ncol=1,
fancybox=True,shadow=True)
return plt
#k=5时的图
radar_plot(r);

同样的方法,分别作出k=4,和k=6时候的客户群特征分析图。
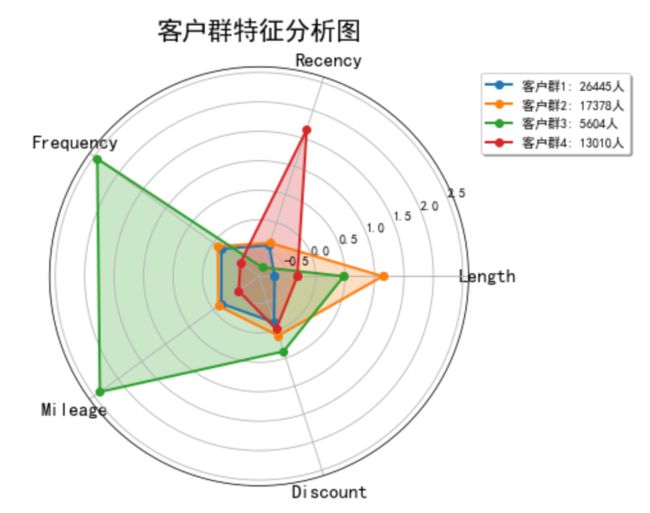
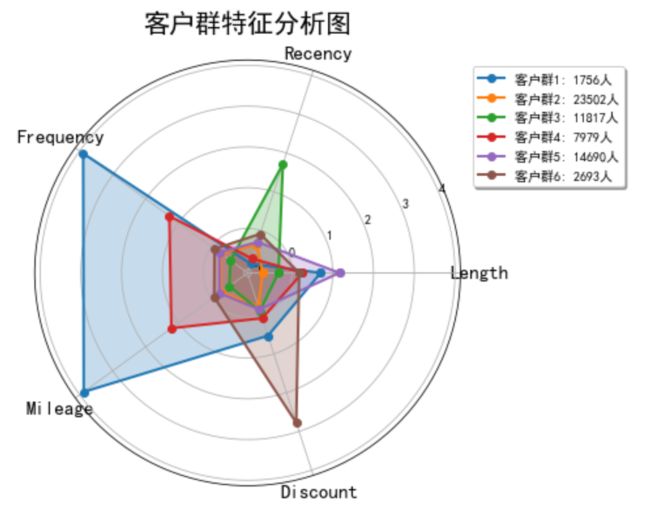
比较三种情况,可以发现:
当k=4,客户群特点不如k=5时鲜明,且客户群1被完全包含在客户群2中;
当k=6,客户群2被完全包含在其他客户群中,没有自身特点;
所以选定k=5。
6.客户价值分析
- 客户群1:12053人,Recency属性最高,其他属性都低,属于低价值的客户。
- 客户群2:5352人,Frequency,Mileage属性最高,Recency属性最低,具有高价值,属于重要保持客户。
- 客户群3:15716人,Length属性最高,Frequency,Mileage属性较高,是资深老客户,有较高价值,属于重要挽留客户。
- 客户群4:24454人,所有属性都比较低,价值略高于客户群1,属于一般客户。
- 客户群5:4862人,Discount属性最高,其他属性低,有较高消费能力,需要大力发展,挖掘潜力,属于重要发展客户。
综上,客户群价值排名客户群2>客户群5>客户群3>客户群4>客户群1
7.小结
根据分类结果,高价值的客户群2和客户群5人数较少,占总人数16%左右,这也很符合实际情况。需要对这二者加大投入,提高客户满意度,增加或保持他们的消费。