若HDFS集群中只配置了一个NameNode,那么当该NameNode所在的节点宕机,则整个HDFS就不能进行文件的上传和下载。
若YARN集群中只配置了一个ResourceManager,那么当该ResourceManager所在的节点宕机,则整个YARN就不能进行任务的计算。
*Hadoop依赖Zookeeper进行各个模块的HA配置,其中状态为Active的节点对外提供服务,而状态为StandBy的节点则只负责数据的同步,在必要时提供快速故障转移。
2.HDFS HA集群
2.1 模型
当有两个NameNode时,提供哪个NameNode地址给客户端?
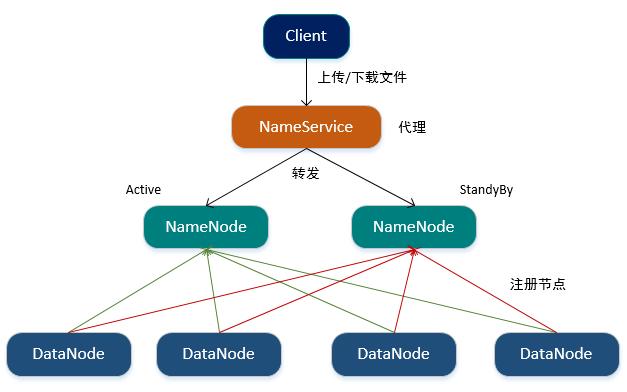
1.Hadoop提供了NameService进程,其是NameNode的代理,维护NameNode列表并存储NameNode的状态,客户端直接访问的是NameService,NameService会将请求转发给当前状态为Active的NameNode。
2.当启动HDFS时,DataNode将同时向两个NameNode进行注册。
怎样发现NameNode无法提供服务以及如何进行NameNode间状态的切换?
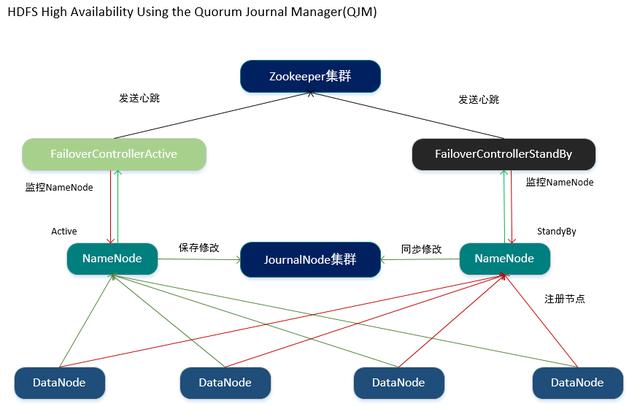
1.Hadoop提供了FailoverControllerActive和FailoverControllerStandBy两个进程用于NameNode的生命监控。
2.FailoverControllerActive和FailoverControllerStandBy会分别监控对应状态的NameNode,若NameNode无异常则定期向Zookeeper集群发送心跳,若在一定时间内Zookeeper集群没收到FailoverControllerActive发送的心跳,则认为此时状态为Active的NameNode已经无法对外提供服务,因此将状态为StandBy的NameNode切换为Active状态。
NameNode之间的数据如何进行同步和共享?
1.Hadoop提供了JournalNode用于存放NameNode中的编辑日志。
2.当激活的NameNode执行任何名称空间上的修改时,它将修改的记录保存到JournalNode集群中,备用的NameNode能够实时监控JournalNode集群中日志的变化,当监控到日志发生改变时会将其同步到本地。
*当状态为Active的NameNode无法对外提供服务时,Zookeeper将会自动的将处于StandBy状态的NameNode切换成Active。
2.2 HDFS HA高可用集群搭建
1.配置HDFS(hdfs-site.xml)
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
192.168.1.80:8020
dfs.namenode.rpc-address.mycluster.nn2
192.168.1.81:8020
dfs.namenode.http-address.mycluster.nn1
192.168.1.80:50070
dfs.namenode.http-address.mycluster.nn2
192.168.1.81:50070
dfs.namenode.shared.edits.dir
qjournal://192.168.1.80:8485;192.168.1.81:8485;192.168.1.82:8485/mycluster
dfs.journalnode.edits.dir
/usr/hadoop/hadoop-2.9.0/journalnode
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
ha.zookeeper.quorum
192.168.1.80:2181,192.168.1.81:2181,192.168.1.82:2181
dfs.replication
3
dfs.permissions.enabled
false
dfs.hosts.exclude
/usr/hadoop/hadoop-2.9.0/etc/hadoop/hdfs.exclude *指定NameNode的RPC通讯地址是为了接收FailoverControllerActive和FailoverControllerStandBy以及DataNode发送的心跳。
2.配置Hadoop公共属性(core-site.xml)
hadoop.tmp.dir
/usr/hadoop/hadoop-2.9.0/data
fs.defaultFS
hdfs://mycluster
fs.trash.interval
1440
*在HDFS HA集群中,StandBy的NameNode会对namespace进行checkpoint操作,因此就不需要在HA集群中运行SecondaryNameNode、CheckpintNode、BackupNode。
2.启动HDFS HA高可用集群
1.分别启动JournalNode



2.格式化第一个NameNode并启动

3.第二个NameNode同步第一个NameNode的信息
4.启动第二个NameNode

5.启动Zookeeper集群
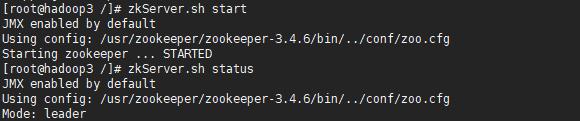
6.格式化Zookeeper
*当格式化ZK后,ZK中将会多了hadoop-ha节点。
7.重启HDFS集群
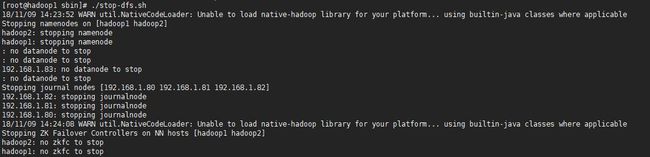
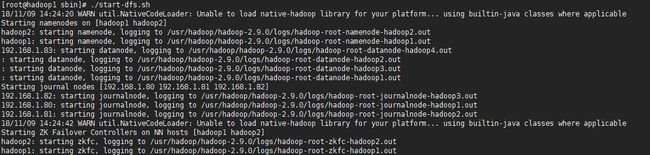
当HDFS HA集群启动完毕后,可以分别访问NameNode管理页面查看当前NameNode的状态
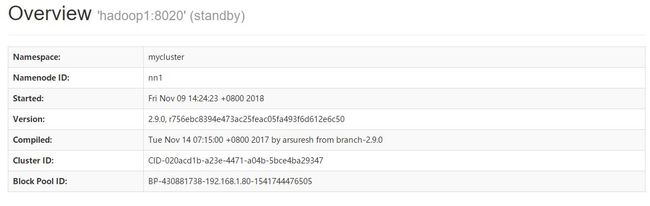
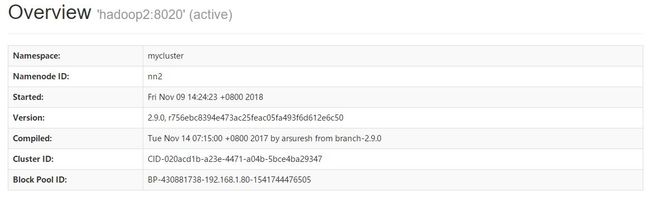
*可以查看到主机名为hadoop1的NamNode其状态为StandBy,而主机名为hadoop2的NameNode其状态为Active。
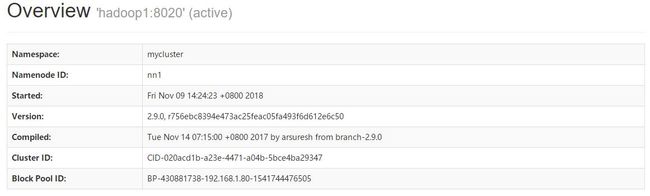
8.模拟NameNode宕机,手动杀死进程。

此时访问NameNode管理页面,可见主机名为hadoop1的NameNode其状态从原本的StandBy切换成Active。
2.3 JAVA操作HDFS HA集群
*由于在HDFS HA集群中存在两个NameNode,且服务端暴露的是NameService,因此在通过JAVA连接HDFS HA集群时需要使用Configuration实例进行相关的配置。
/**
* @Auther: ZHUANGHAOTANG
* @Date: 2018/11/6 11:49
* @Description:
*/
public class HDFSUtils {
/**
* HDFS NamenNode URL
*/
private static final String NAMENODE_URL = "hdfs://mycluster:8020";
/**
* 配置项
*/
private static Configuration conf = null;
static {
conf = new Configuration();
//指定默认连接的NameNode,使用NameService的名称
conf.set("fs.defaultFS", "hdfs://mycluster");
//指定NameService的名称
conf.set("dfs.nameservices", "mycluster");
//指定NameService下的NameNode列表
conf.set("dfs.ha.namenodes.mycluster", "nn1,nn2");
//分别指定NameNode的RPC通讯地址
conf.set("dfs.namenode.rpc-address.mycluster.nn1", "hadoop1:8020");
conf.set("dfs.namenode.rpc-address.mycluster.nn2", "hadoop2:8020");
//配置NameNode失败自动切换的方式
conf.set("dfs.client.failover.proxy.provider.mycluster", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
}
/**
* 创建目录
*/
public static void mkdir(String dir) throws Exception {
if (StringUtils.isBlank(dir)) {
throw new Exception("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
if (!fs.exists(new Path(dir))) {
fs.mkdirs(new Path(dir));
}
fs.close();
}
/**
* 删除目录或文件
*/
public static void delete(String dir) throws Exception {
if (StringUtils.isBlank(dir)) {
throw new Exception("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
fs.delete(new Path(dir), true);
fs.close();
}
/**
* 遍历指定路径下的目录和文件
*/
public static List
listAll(String dir) throws Exception { List
names = new ArrayList<>(); if (StringUtils.isBlank(dir)) {
throw new Exception("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(dir), conf);
FileStatus[] files = fs.listStatus(new Path(dir));
for (int i = 0, len = files.length; i < len; i++) {
if (files[i].isFile()) { //文件
names.add(files[i].getPath().toString());
} else if (files[i].isDirectory()) { //目录
names.add(files[i].getPath().toString());
} else if (files[i].isSymlink()) { //软或硬链接
names.add(files[i].getPath().toString());
}
}
fs.close();
return names;
}
/**
* 上传当前服务器的文件到HDFS中
*/
public static void uploadLocalFileToHDFS(String localFile, String hdfsFile) throws Exception {
if (StringUtils.isBlank(localFile) || StringUtils.isBlank(hdfsFile)) {
throw new Exception("Parameter Is NULL");
}
hdfsFile = NAMENODE_URL + hdfsFile;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
Path src = new Path(localFile);
Path dst = new Path(hdfsFile);
fs.copyFromLocalFile(src, dst);
fs.close();
}
/**
* 通过流上传文件
*/
public static void uploadFile(String hdfsPath, InputStream inputStream) throws Exception {
if (StringUtils.isBlank(hdfsPath)) {
throw new Exception("Parameter Is NULL");
}
hdfsPath = NAMENODE_URL + hdfsPath;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
FSDataOutputStream os = fs.create(new Path(hdfsPath));
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
byte[] data = new byte[1024];
while (bufferedInputStream.read(data) != -1) {
os.write(data);
}
os.close();
fs.close();
}
/**
* 从HDFS中下载文件
*/
public static byte[] readFile(String hdfsFile) throws Exception {
if (StringUtils.isBlank(hdfsFile)) {
throw new Exception("Parameter Is NULL");
}
hdfsFile = NAMENODE_URL + hdfsFile;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
Path path = new Path(hdfsFile);
if (fs.exists(path)) {
FSDataInputStream is = fs.open(path);
FileStatus stat = fs.getFileStatus(path);
byte[] data = new byte[(int) stat.getLen()];
is.readFully(0, data);
is.close();
fs.close();
return data;
} else {
throw new Exception("File Not Found In HDFS");
}
}
}
2.YARN HA集群
2.1 模型
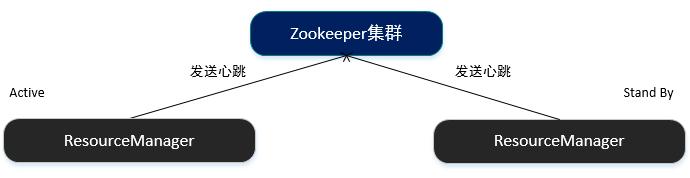
*启动两个ResourceManager后分别向Zookeeper注册,通过Zookeeper管理他们的状态,一旦状态为Active的ResourceManager无法正常提供服务,Zookeeper将会立即将状态为StandBy的ResourceManager切换为Active。
2.2 YARN HA高可用集群搭建
1.配置YARN(yarn-site.xml)
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation。retain-seconds
864000
yarn.nodemanager.resource.memory-mb
8192
yarn.nodemanager.resource.cpu-vcores
8
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
192.168.1.80
yarn.resourcemanager.hostname.rm2
192.168.1.81
yarn.resourcemanager.webapp.address.rm1
192.168.1.80:8088
yarn.resourcemanager.webapp.address.rm2
192.168.1.81:8088
yarn.resourcemanager.zk-address
192.168.1.80:2181,192.168.1.81:2181,192.168.1.82:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk-state-store.parent-path
/rmstore
yarn.nodemanager.recovery.enabled
true
yarn.nodemanager.recovery.dir
/usr/hadoop/hadoop-2.9.0/data/rsnodemanager
yarn.nodemanager.address
0.0.0.0:45454
ResourceManager Restart使用的存储方式(实现类)
1.ResourceManager运行时的数据保存在ZK中:org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
2.ResourceManager运行时的数据保存在HDFS中:org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
3.ResourceManager运行时的数据保存在本地:org.apache.hadoop.yarn.server.resourcemanager.recovery.LeveldbRMStateStore
*使用不同的存储方式将需要额外的配置项,可参考官网,http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerRestart.html
2.启动YARN HA高可用集群
1.在ResourceManager所在节点中启动YARN集群

2.手动启动另一个ResourceManager
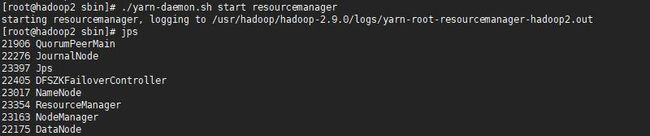
*当启动YARN HA集群后,可以分别访问ResourceManager管理页面,http://192.168.1.80:8088、http://192.168.1.81:8088。
访问状态为StandBy的ResourceManager时,会将请求重定向到状态为Active的ResourceManager的管理页面。
3.模拟ResourceManager宕机,手动杀死进程

*Zookeeper在一定时间内无法接收到状态为Active的ResourceManager发送的心跳时,将会立即将状态为StandBy的ResourceManager切换为Active。