前言
参数化是自动化测试脚本的一种常用技巧。简单来说,参数化的一般用法就是将脚本中的某些输入使用参数来代替,比如登录传参、post、delete、put等请求传参,在脚本运行时指定参数的取值范围和规则;
这样,脚本在运行时就可以根据需要选取不同的参数值作为输入。这种方式通常被称为数据驱动测试(Data Driven Test),参数的取值范围被称为数据池(Data Pool)。
jmeter的test plan中,支持如下4种参数化方式:
CSV Data Set Config:CSV数据控件(常用)
函数助手:_CSVRead
User Defined Variables:用户定义的变量
User Variables:用户参数
本文列举post传参请求的参数化,系统:mac,jmeter版本:3.3
首先新建一个测试脚本,可以自己手动编写(或者通过工具(badboy)录制),推荐手动编写
界面如下:
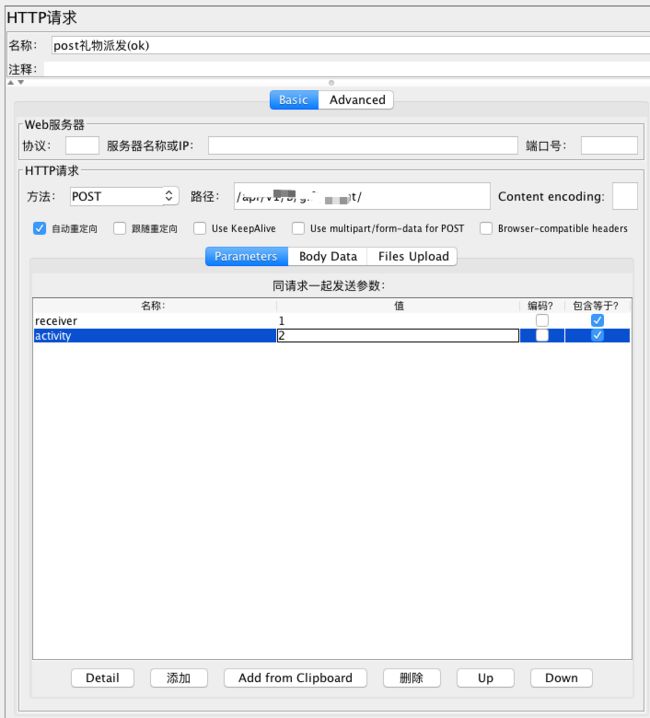
这里可以对参数id、name进行参数化,将用户名密码写入txt文档,保存为.dat格式,编码类型选择UTF-8;
因为配置元件——CSV Data Set Config对参数化的格式要求比较严格,用户名密码一一对应,之间用半角英文逗号隔开
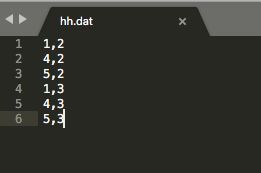
然后将保存的.dat文件放入计算机中,这里我放入路径为:/Users/xxxxxx/apache-jmeter-3.3/test/data
下面具体介绍参数化常用的的四种方法:
一、配置元件——CSV Data Set Config
点击线程组→配置元件→ CSV Data Set Config:
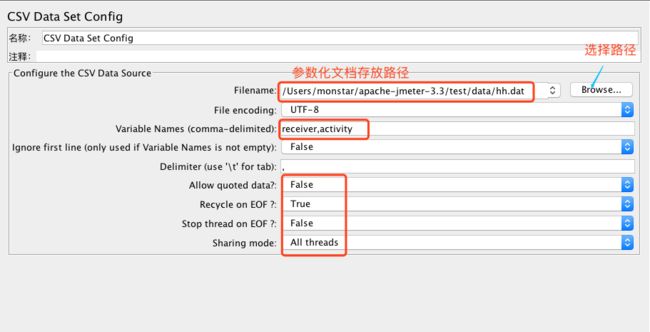
说明:
Filename:.dat文件名,保存参数化数据的文件目录,可选择相对或者绝对路径(建议填写相对路径,避免脚本迁移时需要修改路径);
File encoding:UTF-8,.dat文件的编码格式,在保存时保存编码格式为UTF-8即可;
Variable Names(comma-delimited):对对应参数文件每列的变量名,类似excel文件的文件头,起到标示作用,同时也是后续引用的标识符,建议采用有意义的英文标示;
(如:有几列参数,在这里面就写几个参数名称,每个名称中间用分隔符分割,这里的 user,pwd,可以被利用变量名来引用:user,user,{pwd};
Delimitet:参数文件分隔符,用来在“Variable Names”中分隔参数,与参数文件中的分隔符保持一致即可;
Allow quote data:是否允许引用数据,默认false,选项选为“true”的时候对全角字符的处理出现乱码 ;
Recycle on EOF?:是否循环读取参数文件内容;因为CSV Data Set Config一次读入一行,分割后存入若干变量中交给一个线程,如果线程数超过文本的记录行数,那么可以选择从头再次读入;
△ Ture:为true时,当已读取完参数文件内的测试用例数据,还需继续获取用例数据时,此时会循环读取参数文件数据(即:读取文件到结尾时,再重头读取文件);
△False:为false时,若已至文件末尾,则不再继续读取测试数据;通常在“线程组线程数* 线程组循环次数>参数文件行数”时,选用false(即:读取文件到结尾时,停止读取文件);
Stop thread on EOF?:当Recycle on EOF为False时(读取文件到结尾),停止进程,当Recycle on EOF为True时,此项无意义;
△若为ture,则在读取到参数文件行末尾时,终止参数文件读取线程;
△若为false,此时线程继续读取,但会请求错误,因此时读取的数据为EOF;
Sharing mode:共享模式,即参数文件的作用域,有以下几种方式:
△All threads:当前测试计划中的所有线程中的所有的线程都有效,默认;
△Current thread group:当前线程组中的线程有效;
△Current thread:当前线程有效;
完成之后,将刚才生成的参数写入参数对应的值里面:

设置线程组循环次数:

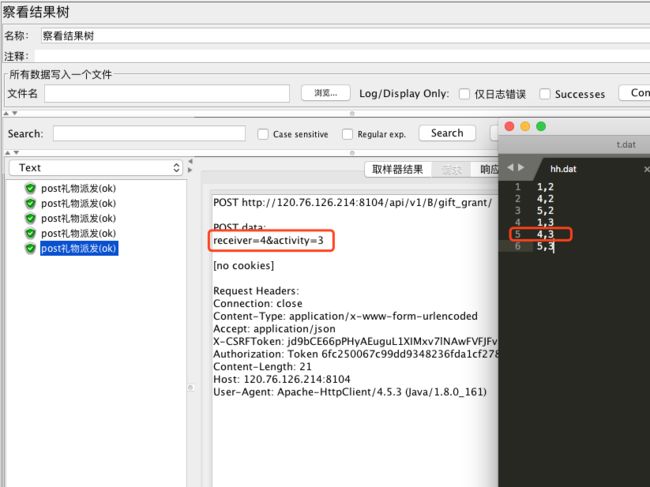
运行,可以看到每次运行依次往下取值:
二、函数助手:_CSVRead(参数化功能较弱)
点击jmeter的界面,功能栏选项→ 函数助手对话框→ _CSVRead

CSV file to get values from | *alias:CSV文件取值路径,这里写入参数化文档存放路径
CSV文件列号| next|*alias:文件起始列号:CSV文件列号是从0开始的,第一列为0,第二列为1,以此类推。。。
函数字符串:即生成的参数化后的参数,可以直接在登陆请求中的参数中引用,第一列为用户名,函数字段号为0,第二列为密码,函数字段号为1,以此类推进行修改使用即可

设置线程数,注意:这里如果仍按方法一里设置循环次数,执行时始终只取第一个数据,所以要设置线程数

执行脚本,察看结果树,可以看到请求的参数都是参数化后的数据

三、配置元件——User Defined Variables
点击线程组添加配置元件→ User Defined Variables(用户定义的变量):
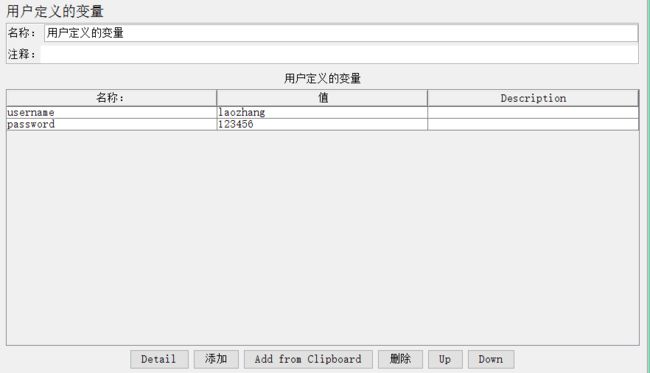
如上图所示,在该参数组中已经定义了两个参数,通过界面下方的添加、删除按钮可以向参数列表增加和删除参数,Up和Down可以上下移动参数的位置;
值可以直接输入,也可通过函数__CSVRead从文件中读取,还可以通过前缀加随机数和方法获取。
比如用户名为user_0到user_100的用户,那么用户名可设置名user_${__Random(0,100,)}

但是这种每次执行的多个线程所替换的参数一样,因为先获取到随机参数,再执行多个HTTP请求。
PS:User Defined Variables中定义的参数值在test plan执行过程中不能发生取值的改变,因此一般仅将test plan中不需要随迭代发生改变的参数(只取一次的参数)
设置在此处;例如:被测应用的host和port值。
四、前置处理器——User Variables
点击线程组添加前置处理器——User Variables(用户参数):
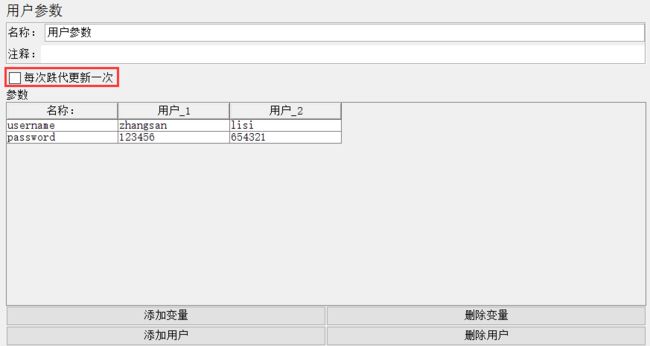
如上图所示,在该参数组中已经设置了两个参数,username和password分别有2组不同的取值,通过页面下方的四个按钮,可以增加删除参数的可能取值。
PS:User Variables中设置的参数可以在test plan执行过程中发生变化。
以上就是jmeter参数化的四种方式,其中:
1、函数助手_CSVRead的参数化功能相比CSV Data Set Config较弱;
2、CSV Data Set Config适用于参数取值范围较大的时候使用,该方法具有更大的灵活性;
3、User Defined Variables一般用于test plan中不需要随请求迭代的参数设置;
4、User Variables适用于参数取值范围很小的时候使用;
PS:相比于loadrunner来说,jmeter参数化有以下不同:
1.jmeter参数文件第一行没有列名称
2.参数文件的编码,尽量保存为UTF-8(编码问题在使用CSV Data Set Config参数化时要求的比较严格)
3.Jmeter的参数化没有LoadRunner做的出色,它是依赖于线程设置的(只有CSV Data Set Config参数化方法才有)