当学习Java的NIO和IO时,有个问题会跳入脑海当中:什么时候该用IO,什么时候用NIO?
下面的章节中笔者会试着分享一些线索,包括两者之间的区别,使用场景以及他们是如何影响代码设计的。
NIO和IO之间的主要差异
下面这个表格概括了NIO和IO的主要差异。我们会针对每个差异进行解释。
| 项目 | IO | NIO |
|---|---|---|
| 面向 | Stream oriented | Buffer oriented |
| 是否阻塞 | Blocking IO | Non blocking IO |
| 选择器 | Selectors |
Stream Oriented vs. Buffer Oriented 面向流和面向缓冲区
第一个重大差异是IO是面向流的,而NIO是面向缓存区的。这句话是什么意思呢?
Java IO面向流意思是我们每次从流当中读取一个或多个字节。怎么处理读取到的字节是我们自己的事情。他们不会再任何地方缓存。再有就是我们不能在流数据中向前后移动。如果需要向前后移动读取位置,那么我们需要首先为它创建一个缓存区。
Java NIO是面向缓冲区的,这有些细微差异。数据是被读取到缓存当中以便后续加工。我们可以在缓存中向向后移动。这个特性给我们处理数据提供了更大的弹性空间。当然我们任然需要在使用数据前检查缓存中是否包含我们需要的所有数据。另外需要确保在往缓存中写入数据时避免覆盖了已经写入但是还未被处理的数据。
Blocking vs. Non-blocking IO 阻塞和非阻塞
Java IO的各种流都是阻塞的。这意味着一个线程一旦调用了read(),write()方法,那么该线程就被阻塞住了,知道读取到数据或者数据完整写入了。在此期间线程不能做其他任何事情。
Java NIO的非阻塞模式使得线程可以通过channel来读数据,并且是返回当前已有的数据,或者什么都不返回如果当前没有数据可读的话。这样一来线程不会被阻塞住,它可以继续向下执行。
通常线程在调用非阻塞操作后,会通知处理其他channel上的IO操作。因此一个线程可以管理多个channel的输入输出。
Selectors 多路复用选择器
Java NIO的selector允许一个单一线程监听多个channel输入。我们可以注册多个channel到selector上,然后然后用一个线程来挑出一个处于可读或者可写状态的channel。selector机制使得单线程管理过个channel变得容易。
NIO和IO是如何影响程序设计的
开发中选择NIO或者IO会在多方面影响程序设计:
1 、使用NIO、IO的API调用类
2 、数据处理
3 、处理数据需要的线程数
API调用
显而易见使用NIO的API接口和使用IO时是不同的。不同于直接冲InputStream读取字节,我们的数据需要先写入到buffer中,然后再从buffer中处理它们。
数据处理
数据的处理方式也随着是NIO或IO而异。 在IO设计中,我们从InputStream或者Reader中读取字节。假设我们现在需要处理一个按行排列的文本数据,如下:
Name: Anna
Age: 25E
mail: [email protected]
Phone: 1234567890
这个处理文本行的过程大概是这样的:
InputStream input = ... ; // get the InputStream from the client socket
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
String nameLine = reader.readLine();
String ageLine = reader.readLine();
String emailLine = reader.readLine();
String phoneLine = reader.readLine();
请注意处理状态由程序执行多久决定。换句话说,一旦reader.readLine()方法返回,你就知道肯定文本行就已读完, readline()阻塞直到整行读完,这就是原因。你也知道此行包含名称;同样,第二个readline()调用返回的时候,你知道这行包含年龄等。
正如你可以看到,该处理程序仅在有新数据读入时运行,并知道每步的数据是什么。一旦正在运行的线程已处理过读入的某些数据,该线程不会再回退数据(大多如此)。下图也说明了这条原则:
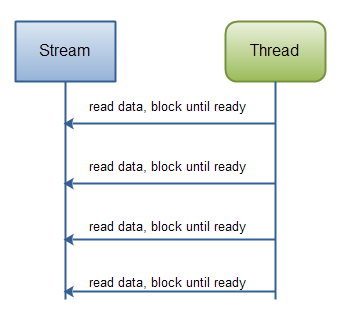
而一个NIO的实现会有所不同,下面是一个简单的例子:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
注意第二行,从通道读取字节到ByteBuffer。当这个方法调用返回时,你不知道你所需的所有数据是否在缓冲区内。你所知道的是,该缓冲区包含一些字节,这使得处理有点困难。
假设第一次 read(buffer)调用后,读入缓冲区的数据只有半行,例如,“Name:An”,你能处理数据吗?显然不能,需要等待,直到整行数据读入缓存,在此之前,对数据的任何处理毫无意义。
所以,你怎么知道是否该缓冲区包含足够的数据可以处理呢?好了,你不知道。发现的方法只能查看缓冲区中的数据。其结果是,在你知道所有数据都在缓冲区里之前,你必须检查几次缓冲区的数据。这不仅效率低下,而且可以使程序设计方案杂乱不堪。例如:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
while(! bufferFull(bytesRead) ) {
bytesRead = inChannel.read(buffer);
}
bufferFull()方法必须跟踪有多少数据读入缓冲区,并返回真或假,这取决于缓冲区是否已满。换句话说,如果缓冲区准备好被处理,那么表示缓冲区满了。
bufferFull()方法扫描缓冲区,但必须保持在bufferFull()方法被调用之前状态相同。如果没有,下一个读入缓冲区的数据可能无法读到正确的位置。这是不可能的,但却是需要注意的又一问题。
如果缓冲区已满,它可以被处理。如果它不满,并且在你的实际案例中有意义,你或许能处理其中的部分数据。但是许多情况下并非如此。下图展示了“缓冲区数据循环就绪”:
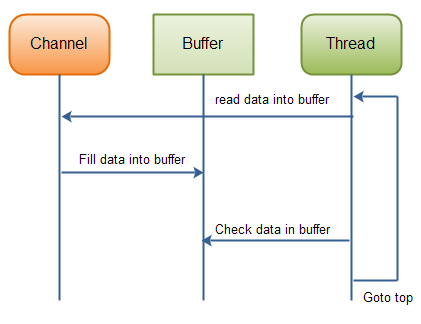
总结
NIO允许我们只用一条线程来管理多个通道(网络连接或文件),随之而来的代价是解析数据相对于阻塞流来说可能会变得更加的复杂。
如果你需要同时管理成千上万的链接,这些链接只发送少量数据,例如聊天服务器,用NIO来实现这个服务器是有优势的。类似的,如果你需要维持大量的链接,例如P2P网络,用单线程来管理这些 链接也是有优势的。这种单线程多连接的设计可以用下图描述:
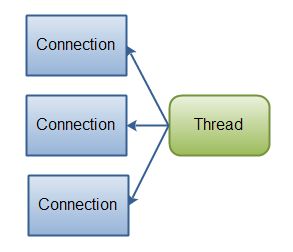 Java NIO: 单个线程管理多个连接
Java NIO: 单个线程管理多个连接
如果链接数不是很多,但是每个链接的占用较大带宽,每次都要发送大量数据,那么使用传统的IO设计服务器可能是最好的选择。下面是经典IO服务设计图:
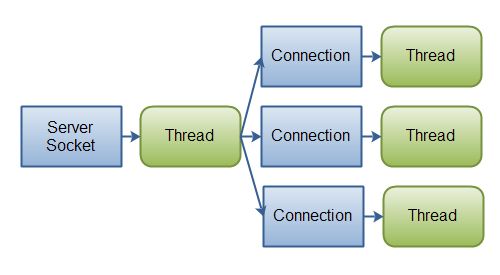 Java IO: 经典 IO 设计 - 一个线程处理一个连接
Java IO: 经典 IO 设计 - 一个线程处理一个连接
原文链接:
- Main Differences Betwen Java NIO and IO