ONE一个除了有一个ONE模块之外,另外还有ONE 文章,ONE 问题模块
这篇笔记将会讲述如何爬取这两个模块。
15年前,互联网是一个逃避现实的地方;现在,现实是一个可以逃避互联网的地方。

From ONE一个
获得文章链接列表
继续上篇日记,依旧是利用chorme分析网页构成。
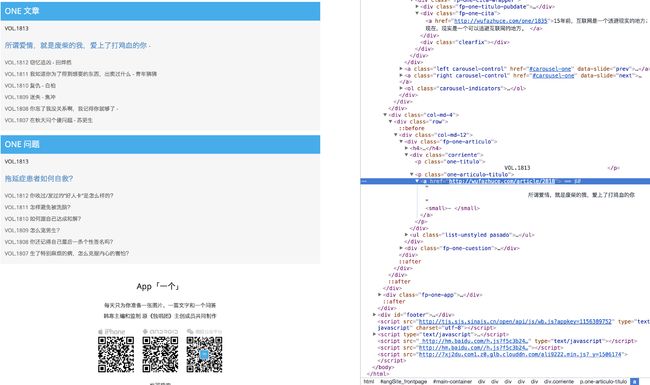
由图可看出,文章的主要内容并不在主页当中,需要点开链接跳转得到,我们需要得到每一篇文章的url,组成文章链接列表,再利用列表链接进行文章的爬取。
而通过源代码,我们发现文章的链接都在类名为fp-one-articulo的div中,于是我们遍历该div中所有的a标签,再从标签中提取url。
def getArticlelist(page):
article_list = []
soup = BeautifulSoup(page, 'html.parser')
for i in soup.findAll('div',class_ ='fp-one-articulo'):
for j in i.find_all('a'):
article_url = j['href']
article_list.append(article_url)
return article_list
可以获得文章链接列表:
'http://wufazhuce.com/article/2818',
'http://wufazhuce.com/article/2819',
'http://wufazhuce.com/article/2816',
'http://wufazhuce.com/article/2810',
'http://wufazhuce.com/article/2808',
'http://wufazhuce.com/article/2815',
'http://wufazhuce.com/article/2812'
获得文章内容
既然已经获得文章链接列表,接下来我们就需要遍历列表,对每一个链接进行解析,目标得到文章的作者,标题,内容。
def getArticle(list):
artlist = []
for url in list:
page_article = requests.get(url).content
soup = BeautifulSoup(page_article, 'html.parser')
title = soup.find_all('div',class_ = 'one-articulo')[0].h2.text
autor = soup.find_all('div',class_ = 'one-articulo')[0].p.text
article = soup.find_all('div',class_ = 'one-articulo')[0].find_all('div',class_ = 'articulo-contenido')[0].text
data = {
'title':title,
'article':article,
'autor':autor
}
artlist.append(data)
return artlist
函数返回包含所有文章的标题,作者及内容的字典格式

问题模块
问题模块与上面文章模块没有明显差别,依旧先得到urllist,再对每一个url进行爬取。
def getQuestionlist(page):
question_list = []
soup = BeautifulSoup(page, 'html.parser')
for i in soup.findAll('div',class_ ='fp-one-cuestion'):
for j in i.find_all('a'):
question_url = j['href']
question_list.append(question_url)
return question_list
def getQuestion(list):
queslist = []
for url in list:
page_article = requests.get(url).content
soup = BeautifulSoup(page_article, 'html.parser')
question_title = soup.find_all('div',class_ = 'one-cuestion')[0].h4.text
question_brief = soup.find_all('div',class_ = 'cuestion-contenido')[0].text
question_content = soup.find_all('div',class_ = 'cuestion-contenido')[1].text
data = {
'ques_title':question_title,
'ques_brief':question_brief,
'ques_content':question_content
}
queslist.append(data)
return queslist
集合字典
上文中,我们分别获得了ONE模块,ONE 文章模块,ONE 问题模块的字典列表,那么我们如何将三个字典集合为一个字典对象呢?
for one,art,ques in zip(one_dict,article_dict,question_dict):
dic = {}
dic.update(one)
dic.update(art)
dic.update(ques)
dict_list.append(dic)
for dict in dict_list:
for key in dict:
print key, ':', dict[key]
我们就获得最终的dict_list数据列表。
源码
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
def getPage(url):
return requests.get(url).content
def getOne(page):
list = []
soup = BeautifulSoup(page, 'html.parser')
for i in soup.find_all('div',class_ = 'item'):
# image = i.a.img['src']
onelist = i.find_all('a')
image = onelist[0].img['src']
word = onelist[1].text
infolist = i.find_all('p')
id = infolist[0].text
date = infolist[1].text+' '+infolist[2].text
data = {
'image':image,
'word':word,
'id':id,
'date':date
}
list.append(data)
return list
def getArticlelist(page):
article_list = []
soup = BeautifulSoup(page, 'html.parser')
for i in soup.findAll('div',class_ ='fp-one-articulo'):
for j in i.find_all('a'):
article_url = j['href']
article_list.append(article_url)
return article_list
def getQuestionlist(page):
question_list = []
soup = BeautifulSoup(page, 'html.parser')
for i in soup.findAll('div',class_ ='fp-one-cuestion'):
for j in i.find_all('a'):
question_url = j['href']
question_list.append(question_url)
return question_list
def getArticle(list):
artlist = []
for url in list:
page_article = requests.get(url).content
soup = BeautifulSoup(page_article, 'html.parser')
title = soup.find_all('div',class_ = 'one-articulo')[0].h2.text
autor = soup.find_all('div',class_ = 'one-articulo')[0].p.text
article = soup.find_all('div',class_ = 'one-articulo')[0].find_all('div',class_ = 'articulo-contenido')[0].text
data = {
'title':title,
'article':article,
'autor':autor
}
artlist.append(data)
return artlist
def getQuestion(list):
queslist = []
for url in list:
page_article = requests.get(url).content
soup = BeautifulSoup(page_article, 'html.parser')
question_title = soup.find_all('div',class_ = 'one-cuestion')[0].h4.text
question_brief = soup.find_all('div',class_ = 'cuestion-contenido')[0].text
question_content = soup.find_all('div',class_ = 'cuestion-contenido')[1].text
data = {
'ques_title':question_title,
'ques_brief':question_brief,
'ques_content':question_content
}
queslist.append(data)
return queslist
if __name__ == '__main__':
url = "http://www.wufazhuce.com/"
dict_list = []
one_page = getPage(url)
one_dict = getOne(one_page)
article_list = getArticlelist(one_page)
article_dict = getArticle(article_list)
question_list = getQuestionlist(one_page)
question_dict = getQuestion(question_list)
for one,art,ques in zip(one_dict,article_dict,question_dict):
dic = {}
dic.update(one)
dic.update(art)
dic.update(ques)
dict_list.append(dic)
for dict in dict_list:
for key in dict:
print key, ':', dict[key]
问题
虽然解决了模块内容问题,但是数据少依旧是一个问题。ONE一个网站只开放了七天的数据,如何获得更多的数据,甚至是一年的数据呢?这么大的数据如何保存呢?