很多网站的全部内容需要登录后才能查看,因此本文会介绍一个模拟登录知乎并输出自己关注话题的小例子。
step1:获取登陆所需的参数
我的知乎是用手机号注册的,通过浏览器的开发者工具查看,发现手机登录网址是phone_url = 'http://www.zhihu.com/login/phone_num'。
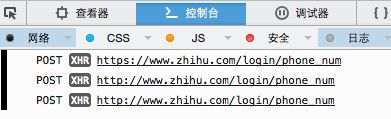
接着需要获取登陆所需的参数,我用的是charles(是少数可以跨平台的抓包工具),在浏览器中打开http://www.zhihu.com/login/phone_num,输入账号密码后,可以找到一个post方法,单击查看它的request参数:
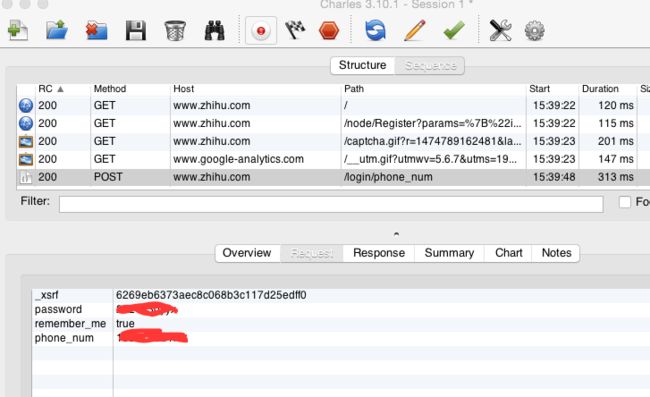
发现除了我们输入的手机号和密码,还有一个_xsrf,是每次随机生成的,所以我们要查看网站源码,把它读取出来。在这条语句里:

可以用正则表达式找出来:
def get_xsrf():
req = opener.open('https://www.zhihu.com')
html = req.read()
html=html.decode('utf-8')
get_xsrf_pattern = re.compile(r'
_xsrf = re.findall(get_xsrf_pattern, html)[0]
return _xsrf
step2:使用cookiescookies是保存在本地的浏览器临时文件目录中的。所以,你要实现自动登录,就首先要在登录时,将用户名和密码写入cookies,再次访问时,就不需要账号密码了。先检测是否存在cookies,如果本地有cookie就不用再post数据了,cookie的文件类型是Set-Cookie3,要用LWPCookieJar进行读取(在http://www.jb51.net/article/46499.htm有详解):
filename = 'cookie'
cookie = http.cookiejar.LWPCookieJar(filename)
try:
cookie.load(filename=filename, ignore_discard=True)
except:
print('Cookie未加载')
step3:创建自定义Opener对象现在建立一个可以处理cookies的opener:
1.urlopen()函数不支持验证、cookie或者其它HTTP高级功能。 要支持这些功能,必须使用build_opener()函数创建自定义Opener对象:opener = request.build_opener(request.HTTPCookieProcessor(cookie))2.给openner添加headers, addheaders方法接受元组而非字典:opener.addheaders = [(key, value) for key, value in headers.items()]然后就可以用opener.open()来传入url和data了
step4:开始登陆操作(终于开始了!有木有小激动啊)传入自己的账号密码:
def login(username, password):
print('使用手机登录中...')
url = phone_url
data = {'_xsrf': get_xsrf(),
'password': password,
'remember_me': 'true',
'phone_num': username
}
# 保存cookie到本地
cookie.save(ignore_discard=True, ignore_expires=True)
主函数:
if __name__ == '__main__':
#在这里输入你的账号和密码
account = 'xxxxxxxx'
secret = 'xxxxxxxx'
login(account, secret)
# 输出主页的关注话题。可以说明登录成功
get_url = 'https://www.zhihu.com/people/yang-zhi-hu-97-58/topics'
get = opener.open(get_url)
content = get.read().decode('utf-8')
#因为看了源码后发现关注话题的名字都在strong标签里
reg = '.*?'
text = re.compile(reg)
textlist = re.findall(text,content)
for i in textlist:
title = re.sub("", "", i)
title = re.sub("", "", title)
print(title)
这样就啦~会输出关注的话题名字还有数量。
最后还是综合一下代码咯:
import http.cookiejar
import json
import re
from urllib import parse, request
phone_url = 'http://www.zhihu.com/login/phone_num'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
filename = 'cookie'
cookie = http.cookiejar.LWPCookieJar(filename)
# 若本地有cookie则不用再post数据了
try:
cookie.load(filename=filename, ignore_discard=True)
except:
print('Cookie未加载')
#urlopen()函数不支持验证、cookie或者其它HTTP高级功能。 要支持这些功能,必须使用build_opener()函数创建自定义Opener对象。
opener = request.build_opener(request.HTTPCookieProcessor(cookie))
# 给openner添加headers, addheaders方法接受元组而非字典
opener.addheaders = [(key, value) for key, value in headers.items()]
# 登陆知乎时服务器给的参数
def get_xsrf():
"""
获取参数_xsrf
"""
req = opener.open('https://www.zhihu.com')
html = req.read()
html=html.decode('utf-8')
get_xsrf_pattern = re.compile(r'
_xsrf = re.findall(get_xsrf_pattern, html)[0]
return _xsrf
def login(username, password):
"""
输入自己的账号密码,模拟登录知乎
"""
# 检测到11位数字则是手机登录
print('使用手机登录中...')
url = phone_url
data = {'_xsrf': get_xsrf(),
'password': password,
'remember_me': 'true',
'phone_num': username
}
# 保存cookie到本地
cookie.save(ignore_discard=True, ignore_expires=True)
if __name__ == '__main__':
account = 'xxxxxxxx'
secret = 'xxxxxxx'
login(account, secret)
# 输出主页的关注话题。以此来验证确实登录成功
get_url = 'https://www.zhihu.com/people/yang-zhi-hu-97-58/topics'
get = opener.open(get_url)
content = get.read().decode('utf-8')
reg = '.*?'
text = re.compile(reg)
textlist = re.findall(text,content)
for i in textlist:
title = re.sub("", "", i)
title = re.sub("", "", title)
print(title)