深度学习是很强大,几乎可以通过足够的数据训练出各种各样复杂函数。但缺点是,难以训练出满意的结果。
与许多游戏中的强力角色一样,虽然成长值高,练级却困难。花好半天,练个半死,才见经验条缓缓爬到头。然而,此时电脑突然一黑,罢工了,又忘了存档。在怒砸键盘,对天大喊三声 “搞Billy!”,悔恨的泪水流了一嘴后,你放弃作为一名合格玩家的尊严,默默掏出了修改器。
这种设定,是游戏制作者为了游戏平衡性而设置的,给你一个强大的角色,但同时也让他难于成长。于是,我估计我们这个世界的游戏制作者也是这样想的。所谓天将降大任于斯人也,先多给你些磨炼,现在是天将降大任与斯网了。
于是这篇便稍稍提提深度学习训练的问题,最后再小结一下。

深度学习的问题是训练起来比较难。这里的难,主要可以从两方面来说。
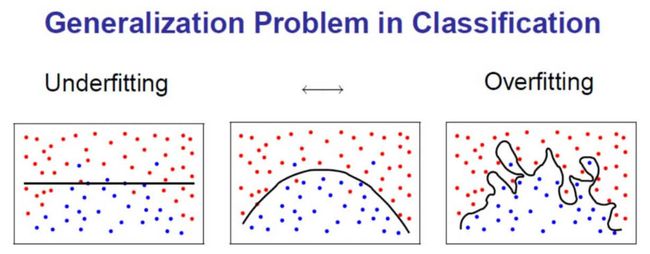
一个是优化起来难,也就是说难找到比较好的解,获得满意的训练好的神经网络,这种问题叫做欠拟合 (Underfitting); 还有一个是由于深层网络结构复杂,对当前数据学习过好,但当出现新的没见过的数据时,表现却很差,称作过拟合(Overfitting)。
说如何解决深度学习中这两方面问题前,便于理解,先来提提什么是欠拟合和过拟合吧。
欠拟合 (学不够) 与过拟合 (学过头)
欠拟合和过拟合,以及它们涉及的Variance和Bias,可以说是机器学习训练中最重要的概念了。
因为所有机器学习工程师训练模型的最终目的就是,不要让模型欠拟合 (能力过弱),也不要让它过拟合 (能力过强),而要让模型刚刚好。所以说机器学习训练中也得遵循中庸之道,缺不好,过也不好,刚刚好最好。
打个比方的话,小明要考试了,他有一套来自无数勇者前辈们,冒着生命危险从考场带出的往年考题集。之后出现两种情况。
第一种情况,小明这家伙非常不争气,守着一座金山却不当一回事。考试前几天,还天天窝在寝室和一群小伙伴打游戏,早就忘了还有考试这事。等回过神,考题集也没怎么看。于是,结果可想而知,考的一塌糊涂。这个可以叫做欠拟合吧。
另外一种情况,平行世界中小明是一位非常勤奋的同学,但脑瓜比较笨,不怎么转得过弯来。拿了考题集,从开学起就每天做一遍,等到考试前,已经可以倒写如流。你翻开一页,他可以把答案转个一百八十度写出来,还工工整整,像刚从打印机打出来。
但到了考试那天,题目一出来,傻眼了。居然换了出卷老师,考的题型和之前不一样,亦或是题目改了些条件,小明不会了。于是小明做完几道基础题,就愤愤然离开了考场。这个算是叫做过拟合吧。
这里面,把小明当做是我们的神经网络。那么,来自前辈的考题集就是训练数据集了。最后,考试题目就是测试数据集,来测试我们的神经网络性能。
小明在考题集上做练习,可以看做是神经网络在训练数据集上进行训练。
于是类比而来,给神经网络一个训练数据集,如果连这个数据集都学不好的话,那就更别提那些测试数据、新数据了,这就欠拟合了;而如果把这个训练数据集学得太好,记得分毫不差,以至于当出现新的数据时,都反应不过来,那就过拟合了。
深度学习中的欠拟合

在当前各种充足的计算硬件条件下,深度学习的欠拟合问题,往往并不是训练时间不够导致,可能更主要的是一些内部问题比如梯度消失问题,或是饱和单元阻止梯度的传播导致。
在之前训练一篇有说到,反向传播主要传播的是梯度,而梯度是用来更新神经网络,让神经网络变得更符合我们期望的。而这上述两个问题,一个是梯度消失了,而另一个是梯度被饱和单元挡住,传播不过去。也就是说,两种情况网络都无法获得想要的梯度来更新自己,那么自然而然也就会导致学习不足,导致欠拟合。
其实欠拟合的解决方法比较简单,无非就是训练不够嘛。
那就用更好的训练优化方法,来解决上面提到的两个问题,比如说梯度消失问题的话,可以用比如残差网络 (Residual Network) 或是 定时反向传播 (BPTT) 算法等等更好的算法、框架。
再如神经单元饱和,主要是因为sigmoid或tanh这两个激活函数特性导致的,可以换成ReLu激活函数,或是利用适当的正规化 (Normalization)避免饱和情况的发生。
除了更好的训练优化方法,还可以加上GPU这样的大杀器,加速训练,在短时间内对网络进行更多训练。
深度学习中的过拟合

而深度学习的过拟合问题,因为深层网络结构复杂,可以模拟出来的函数非常复杂,容易对当前数据训练过度。我们需要提高我们模型的泛化性。
怎么解决呢?理论上能提高泛化性的技巧都可以,这里提两个。
第一个方法,使用预训练 (Pre-training) 网络。还记得之前提到,人脑的视觉系统可以提取出各种视觉低级特征、中级特征、还有高级特征吗。那么我们何不利用,在大量图片上已学习到具有普遍性特征的网络,来进行当前任务的学习。
于是就可以用之前在很大的数据集上面,比如说有名的ImageNet,训练过的网络。然后直接把我们当前的网络,底层捕捉特征的部分,换成已经训练过的网络,之后再进行训练。
拿小明考试的例子来打比方的话,既然光看考题不行,那该怎么办。我们首先想到的当然会是,为什么不看书呢。于是,道理也是一样。假如小明在做考题前,有把教科书还有老师发的资料都好好看了一遍,心里有个底,那么就可以把此时的小明当做预训练过的网络。之后,小明再练习完往年考题集的话,即使在考试中出现了往年考题以外的题,他也一定程度上能从容应对了。
第二个方法,就是用随机漏失 (Dropout) 技巧,指的是在网路某些层内,传递参数时,随机丢失一些参数来训练。这样训练出来的好处是,网络不会偷懒只看重几个重要的特征而忽视影响较小的特征。重要特征的丢失,逼得网络不得不想办法利用其他次要特征。网络就会有很强的稳健性,遇到新的没见过的数据,也能够很好处理。
如果再拿小明考试来打比较的话,既然真考试的时候,有些题目会变参数变条件。那何不自己在练习题集的时候,先改改条件,变变参数呢。这样到了考试的时候,也能随机应变。
关于训练的补充
当然,这里说到的这几个技巧,也只是很多技巧中的一些。现在,对这个方面的研究,深度学习社群也都还在如火如荼地进行着,说不定之后会有更好更有效的方法呢。
有某位中二大牛把机器学习训练比作修真炼丹,需要谨慎选择各种各样的条件,材料、时间、火候... 稍有不慎就是一炉废丹。
但我更乐意比作魔法师吧。里面一大堆有着各种各样名字的技巧,像咒语一样,看你怎么组合使用它们取得最好效果。

这些小技巧包括有,正则化 (Regularization)、正规化 (Normalization)、初始化 (Initialization)、模型选择 (包括网格搜索和随机搜索来选各种参数)、什么时候停止训练 (停止法 Early Stopping)、 动量 (Momentum)、各种优化器(Adagrad, RMSProp, Adam)等等等等。
虽然这么多,但以上方法的目的,无非两个,第一,使得训练出来的网络处理新数据时有更好的准确率,高泛化性(很好地处理新数据),解决过拟合;第二,让训练速度更加快,解决欠拟合。
小结
到这里,差不多关于神经网络还有深度学习的一些大体概念也就讲完了。
可能看到这里,大部分人还是云里雾里,本来我自己也就是小菜鸟一只。这里写的大多也是拾各位大牛的牙慧,加上一些自己理解。
虽然是这样说,但是至少至少还是希望大家对这个话题有了些熟悉感,某天遇到,也会会心一笑,这个我知道,貌似在某个号主天天更新乱七八糟东西的公众号上看到过。
吴教授说了,深度学习之于现在的我们,就相当于二十世纪初电力之于当时的人们。诞生之后,对各行各业产生巨大冲击,带来巨大变革。
那之后就来看看现在有哪些行业正在受到冲击,进行变革吧。还有在这些变革中,哪些公司或者人在领导着这些。