Spark是什么?
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是一种开源的类Hadoop MapReduce的通用并行框架,拥有Hadoop MapReduce所具有的优点。
Spark不同于MapReduce的是,Spark的Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 主要有三个特点 :
首先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
其次,Spark 很快,支持交互式计算和复杂算法。
最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
总结一下:从各种方向上(比如开发速度和运行速度等)来看,Spark都优于Hadoop MapReduce;同时,Spark还提供大数据生态的一站式解决方案。因此,学会使用Spark刻不容缓。
目录
Spark生态圈
Spark运行架构
Spark运行模式
Spark的Job执行流程
Spark编程模型之RDD
Spark使用的简单Demo
Spark生态圈
首先,我们先来看一下整个Spark的生态圈,都有哪些功能。
下图很好的说明了整个Spark的层级之间,以及同级之间的关系。(注意,此图有些老,一些名称已经不再使用)
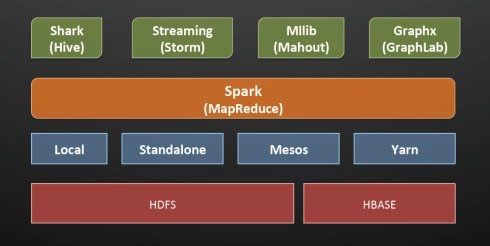
从下往上看,分别是:
数据层:Spark可以运行在众多底层的数据模型中,比如HDFS、HBASE、Amazon s3等
资源调度层:这一层是Spark的四种运行模式,包括一种本地模式local,和三种集群模式Standalone,Mesos,Yarn。
计算层:这一层是Spark的核心层,Spark Core;其计算模型基于RDD(弹性分布式数据集)
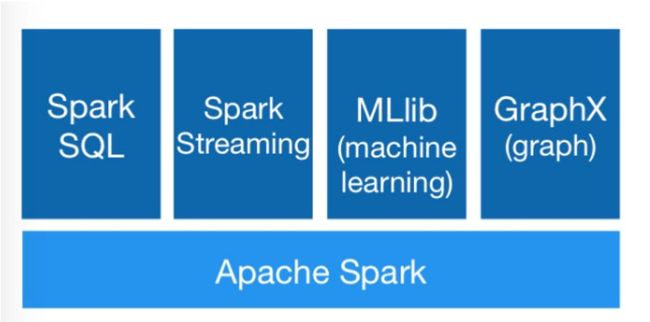
应用层:这一部分提供了基于Spark Core的高级应用,如用于交互式查询的SparkSQL(即图中的shark),用于流式处理的Spark Streaming,用于机器学习的MLlib和用于图计算的GraphX等。
下图展示的是目前的Spark的生态圈及组件。
Spark运行架构
凡是用于大数据处理的,几乎都是主从模式(master/slave),Spark也不例外。
Spark的主节点,被称之为Driver,其控制着整个Spark程序的应用上下文:SparkContext。
Spark的从节点,称为Executor,负责执行具体的任务。
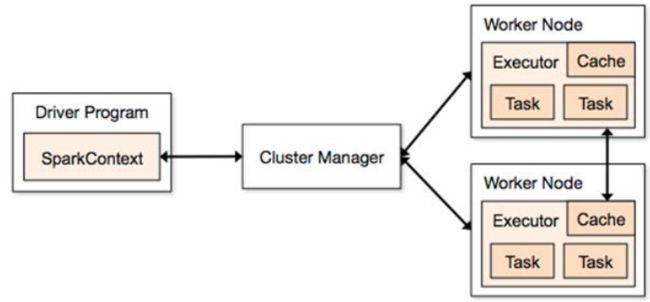
简单解释一下上图:
1 首先Driver会创建一个SparkContext,然后和集群资源的管理者Cluster Manager进行通信,申请资源。
2 Cluster Manager会根据实际情况将合适的Worker节点分配给Spark,作为Executor使用。
3 Driver和各Executor建立连接,生成DAG图,划分Stage,进行Task调度;Executor则负责具体的Task执行。
Spark运行模式
Spark的运行模式往粗了说,就只有两种:用于测试和学习的本地模式,和用于实际生产的集群模式。细分一下,集群模式主要分为Standalone,Spark on Memos,Spark on Yarn三种方式。当然还有更细的划分方式,不过我们此处就不讨论了,所以我们主要介绍下面的四种方式。
本地模式
一般是指“Local[N]”模式,其使用N个线程来进行主从模拟。不需要进行额外的参数配置,安装好Spark之后,默认启动的就是这种模式。
其操作全为单机完成,主要用于学习和功能测试。
Standalone
这里需要构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。
这种模式是指利用Spark自己原生的master作为Cluster Manager来管理集群资源。这里需要注意的是,master并不是driver。master只担任资源管理调度等方面的工作,具体的Task调度还是由driver完成。
Spark on Memos
Spark客户端直接连接Mesos,不需要额外构建Spark集群,这种模式利用Memos的调度机制来管理集群。
Spark on Yarn
Spark客户端直接连接Yarn,不需要额外构建Spark集群,这种模式是指利用Yarn的调度机制来管理集群,即上图中的spark运行架构中的Cluster Manager为Resource Manager。
需要补充的一点是,几种集群模式中,都有两种细分的方式,这里以Standalone为例。
Standalone Client模式(集群)
该模式运行与集群之上,使用这种模式的时候,Master进程做为cluster manager,SparkSubmit做为Client端和运行driver程序;Worker进程用来作为Executor。
Standalone Cluster模式(集群)
该模式也是运行于集群之上,使用这种模式的时候,Client端的SparkSubmit进程会在提交任务之后退出,Client不再负责运行driver程序;Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动driver程序;同时因为DriverWrapper 进程会占用Worker进程的一个core,所以同样的资源下配置下,会比Standalone Client模式,少用1个core来参与计算。
总结一下:Client模式中,Client提交任务之后,会作为Spark程序的driver,仍然和集群保持连接;而Cluster模式中,Client提交任务之后就退出,由集群中的某个节点担任driver,也可以简单理解为后台模式。
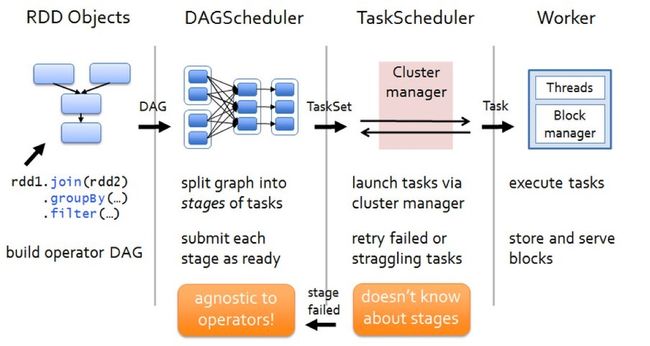
Spark执行流程(Job的执行流程)
整个Spark执行任务,可以分为以下四个部分:
Driver端:
1 生成逻辑查询计划
2 生成物理查询计划
3 任务调度
Executor端
4 任务执行
整个流程的简图可以参照下图:
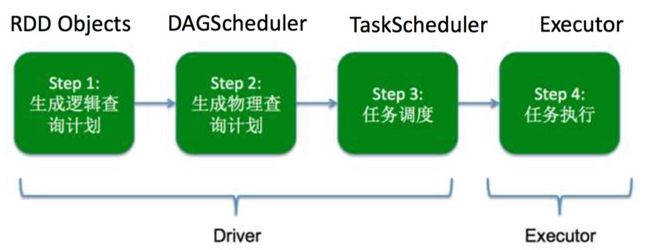
如果对上面的流程有疑惑的话,可以这么考虑:
Driver端:
1 生成逻辑查询计划:这一步主要是根据我们对RDD的操作,比如map,join,reduce等操作,来设定RDD的查询依赖关系。
2 生成物理查询计划:根据上一步的逻辑图和数据实际分布的情况,生成整个任务实际执行的调度图(DAG图)。
3 任务调度:根据第二步生成的DAG图,进行具体的任务调度。
Executor端
4 任务执行:Executor执行具体的任务
详细的Job执行的流程图,如下:
Spark编程模型之RDD(resilient distributed dataset)
RDD定义
RDD,弹性分布式数据集,是Spark中的数据抽象模型和编程模型,本质上是一种抽象的特殊集合 。
RDD的特点是支持多种数据来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作等。
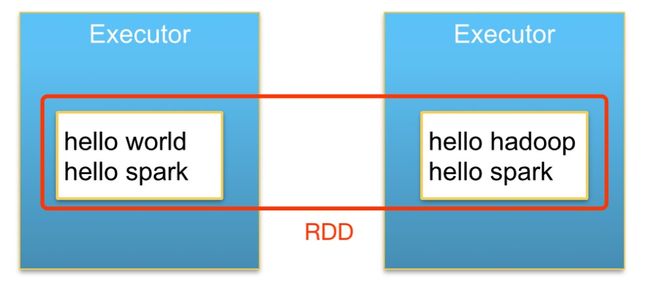
在逻辑上,一个RDD代表一个数据集。而在物理上,同一个RDD里的数据可能分布在不同的节点。
下图表示一个RDD在物理上跨节点的分布情况。
RDD创建
#RDD主要有三种方式创建
1 通过内存中的数据创建(比如内存中的数组,适合学习测试使用)
val seq=Seq(1,2,3)
val rdd=sc.makeRDD(seq)
2 通过外部数据集创建(如HDFS数据集,一般用在生产环境)
val rdd=sc.textFile("test.txt")
3 通过其他RDD转换而来(RDD transformation)
val childRdd=rdd.map(func)
RDD操作
RDD的操作分为两种:Transformation(转换)操作和Action(执行)操作。其中,转换操作会生成一个新的RDD,但这种操作是惰性的,并不会立即执行,而是生成了RDD间的相互依赖关系;执行操作一般是“写”操作,“写”到driver的collect()、take()和写到文件的save()等,或者立刻需要返回结果的count()等函数;执行操作都是立即执行的。
Transformation
1 将一个RDD转化成一个新的RDD
2 保存RDD间的依赖关系,生成DAG图
3 惰性操作,不会立刻执行
Action
1 触发任务的执行
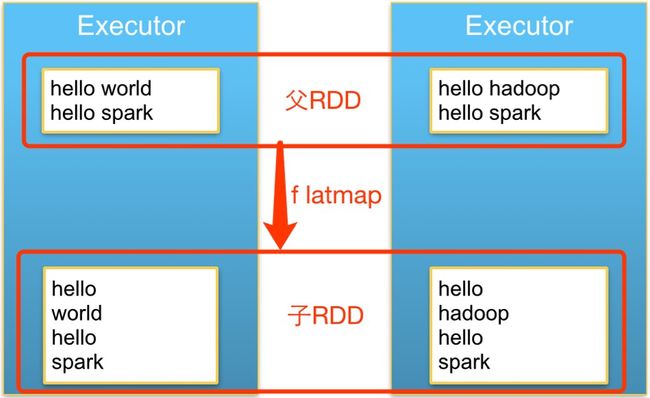
RDD依赖关系
上面已经说到,RDD可以由RDD转换而来,这样就形成了RDD之间的相互依赖关系。根据RDD在实际执行中的表现,可以将RDD间的依赖关系分为以下两种:
窄依赖:每个父RDD的一个Partition最多被子RDD的一个Partition所使用
宽依赖:每个父RDD的一个Partition会被多个子RDD的Partition所使用
简单来说,窄依赖就是父子的一对一或者多对一关系,宽依赖就是父子的一对多关系。Job执行时,当窄依赖失败时,只需要重算对应的父RDD就可以了;而当宽依赖失败的时候,需要重算所有对应的父RDD,而重算的父RDD中,会有一些是无效的;同时,宽依赖一般会跨节点,产生大量的shuffle过程,所以要尽量减少宽依赖。
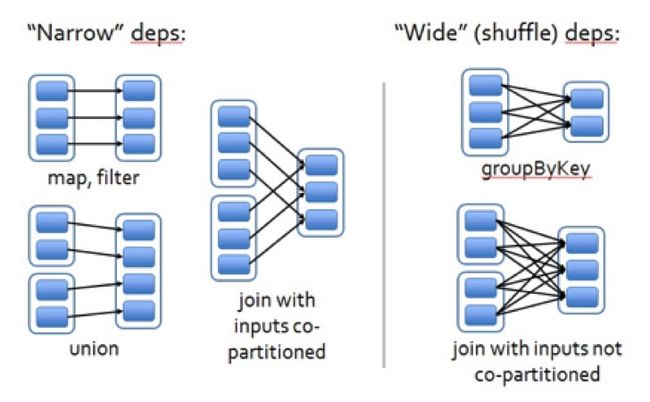
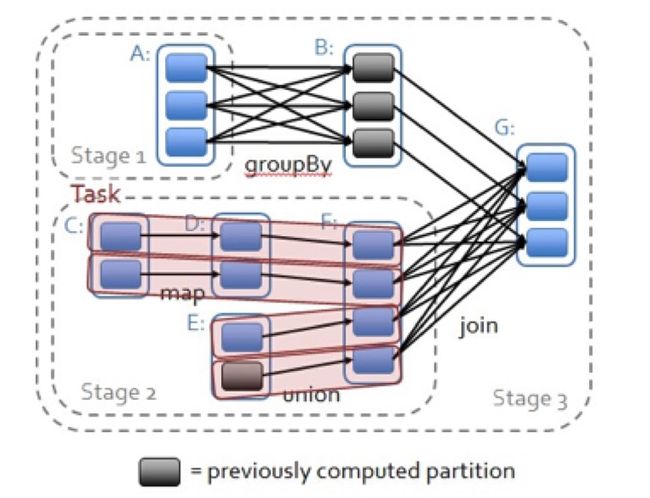
RDD的宽依赖:stage的划分
那么,RDD的宽窄依赖有什么用呢?上面也说过,知道什么是宽依赖,并且知道宽依赖是性能瓶颈,有助于我们优化程序的执行。
其次,RDD的宽依赖,也是stage的划分依据,如下图所示:
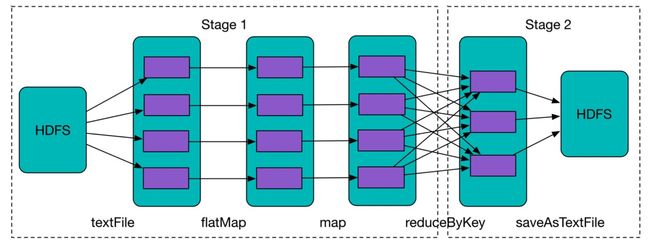
Spark使用的简单Demo

文集
Spark:理论与实践
文章
五分钟大数据:Spark入门
Spark编程快速入门
Spark难点解析:Join实现原理
可视化发现Spark数据倾斜