23.2.3. 编程接口
23.2.3.1. Port调度配置API
rte_sched.h文件包含port,subport和pipe的配置功能。
23.2.3.2. Port调度入队API
Port调度入队API非常类似于DPDK PMD TX功能的API。
int rte_sched_port_enqueue(struct rte_sched_port *port, struct rte_mbuf **pkts, uint32_t n_pkts);
23.2.3.3. Port调度出队API
Port调度入队API非常类似于DPDK PMD RX功能的API。
int rte_sched_port_dequeue(struct rte_sched_port *port, struct rte_mbuf **pkts, uint32_t n_pkts);
23.2.3.4. 用例
/* File "application.c" */
#define N_PKTS_RX 64
#define N_PKTS_TX 48
#define NIC_RX_PORT 0
#define NIC_RX_QUEUE 0
#define NIC_TX_PORT 1
#define NIC_TX_QUEUE 0
struct rte_sched_port *port = NULL;
struct rte_mbuf *pkts_rx[N_PKTS_RX], *pkts_tx[N_PKTS_TX];
uint32_t n_pkts_rx, n_pkts_tx;
/* Initialization */
/* Runtime */
while (1) {
/* Read packets from NIC RX queue */
n_pkts_rx = rte_eth_rx_burst(NIC_RX_PORT, NIC_RX_QUEUE, pkts_rx, N_PKTS_RX);
/* Hierarchical scheduler enqueue */
rte_sched_port_enqueue(port, pkts_rx, n_pkts_rx);
/* Hierarchical scheduler dequeue */
n_pkts_tx = rte_sched_port_dequeue(port, pkts_tx, N_PKTS_TX);
/* Write packets to NIC TX queue */
rte_eth_tx_burst(NIC_TX_PORT, NIC_TX_QUEUE, pkts_tx, n_pkts_tx);
}
23.2.4. 实现
内部数据结构示意图,详细内容如下。
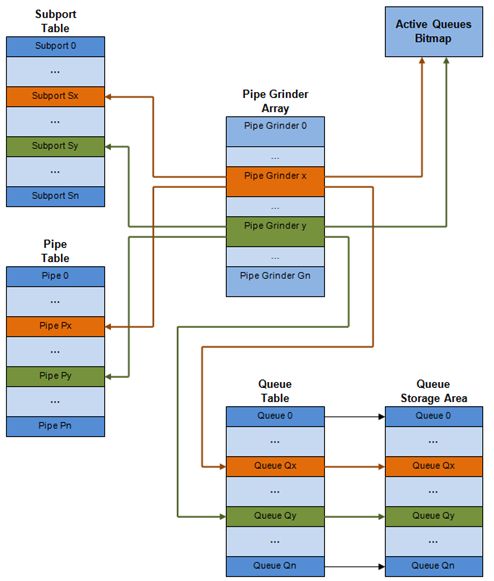
| # | 数据结构 | 大小 | Per port | Access type End | Access type Deq | 描述 |
|---|---|---|---|---|---|---|
| 1 | 子接口表条目 | 64 | # subports per port | Rd, Wr | 持续的子接口数据(信用,等) | |
| 2 | Pipe表条目 | 64 | # pipes per port | Rd, Wr | 在运行时更新的pip,其TC及其队列的持久数据(信用等)。pipe配置参数在运行时不改变。 相同的pipe配置参数由多个pipe共享,因此它们不是pipe表条目的一部分。 | |
| 3 | 队列条目 | 4 | #queues per port | Rd, Wr | Rd, Wr | 持续的队列数据(读写指针)。对于所有队列,每个TC的队列大小相同,允许使用快速公式计算队列基地址,因此这两个参数不是队列表条目的一部分。任何给定pipe的队列表条目都存储在同一个高速缓存行中。 |
| 4 | 队列存储空间 | Config (64x8) | # queues per port | Wr | Rd | 每个队列的元素数组; 每个元素的大小是8字节(mbuf指针)。 |
| 5 | 活动队列位图 | 1 bit per queue | 1 | Wr(set) | Rd, Wr (Clear) | 位图为每个队列维护一个状态位:队列不活动(队列为空)或队列活动(队列不为空)。队列位由调度程序入队设置,并在队列变空时由调度程序清除。位图扫描操作返回下一个非空pipe及其状态(pipe中活动队列的16位掩码)。 |
| 6 | Grinder | ~128 | Config (default: 8) | Rd, Wr | 目前正在处理的活动pipe列表。grinder在pipe加工过程中包含临时数据。一旦当前pipe排出数据包或信用点,它将从位图中的另一个活动管道替换。 |
23.2.4.1. 多核缩放策略
多核缩放策略如下:
- 在不同线程上操作不同的物理端口。但是同一个端口的入队和出队由同一个线程执行。
- 通过在不同线程上操作相同物理端口(虚拟端口)的不同组的子端口,可以将相同的物理端口拆分到不同的线程。类似地,子端口可以被分割成更多个子端口,每个子端口由不同的线程运行。但是同一个端口的入队和出队由同一个线程运行。仅当出于性能考虑,不可能使用单个core处理完整端口时,才这样处理。
23.2.4.1.1. 同一输出端口的出队和入队
上面强调过,同一个端口的出队和入队需要由同一个线程执行。因为,在不同core上对同一个输出端口执行出队和入队操作,可能会对调度程序的性能造成重大影响,因此不推荐这样做。
同一端口的入队和出队操作共享以下数据结构的访问权限:
- 报文描述符
- 队列表
- 队列存储空区
- 活动队列位图
可能存在使性能下降的原因如下:
- 需要使队列和位图操作线程安全,这可能需要使用锁以保证访问顺序(例如,自旋锁/信号量)或使用原子操作进行无锁访问(例如,Test and Set或Compare and Swap命令等))。前一种情况对性能影响要严重得多。
- 在两个core之间对存储共享数据结构的缓存行执行乒乓操作(由MESI协议缓存一致性CPU硬件透明地完成)。
当调度程序入队和出队操作必须在同一个线程运行,允许队列和位图操作非线程安全,并将调度程序数据结构保持在同一个core上,可以很大程度上保证性能。
23.2.4.2. 性能缩放
扩展NIC端口数量只需要保证用于流量调度的CPU内核数量按比例增加即可。
23.2.4.3. 入队水线
每个数据包的入队步骤:
- 访问mbuf以读取标识数据包的目标队列所需的字段。这些字段包括port,subport,traffic class及queue,并且通常由报文分类阶段设置。
- 访问队列结构以识别队列数组中的写入位置。如果队列已满,则丢弃该数据包。
- 访问队列阵列位置以存储数据包(即写入mbuf指针)。
应该注意到这些步骤之间具有很强的数据依赖性,因为步骤2和3在步骤1和2的结果变得可用之前无法启动,这样就无法使用处理器乱序执行引擎上提供任何显着的性能优化。
考虑这样一种情况,给定的输入报文速率很高,队列数量大,可以想象得到,入队当前数据包需要访问的数据结构不存在于当前core的L1或L2 data cache中,此时,上述3个内存访问操作将会产生L1和L2 data cache miss。就性能考虑而言,每个数据包出现3次L1 / L2 data cache miss是不可接受的。
解决方法是提前预取所需的数据结构。预取操作具有执行延迟,在此期间处理器不应尝试访问当前正在进行预取的数据结构,此时处理器转向执行其他工作。可用的其他工作可以是对其他输入报文执行不同阶段的入队序列,从而实现入队操作的流水线实现。
下图展示出了具有4级水线的入队操作实现,并且每个阶段操作2个不同的输入报文。在给定的时间点上,任何报文只能在水线某个阶段进行处理。

由上图描述的入队水线实现的拥塞管理方案是非常基础的:数据包排队入队,直到指定队列变满为止;当满时,到这个队列的所有数据包将被丢弃,直到队列中有数据包出队。可以通过使用RED/WRED作为入队水线的一部分来改进,该流程查看队列占用率和报文优先级,以便产生特定数据包的入队/丢弃决定(与入队所有数据包/不加区分地丢弃所有数据包不一样)。
23.2.4.4. 出队状态机
从当前pipe调度下一个数据包的步骤如下:
- 使用位图扫描操作识别出下一个活动的pipe(prefetch pipe)。
- 读取pipe数据结构。更新当前pipe及其subport的信用。识别当前pipe中的第一个active traffic class,使用WRR选择下一个queue,为当前pipe的所有16个queue预取队列指针。
- 从当前WRR queue读取下一个元素,并预取其数据包描述符。
- 从包描述符(mbuf结构)读取包长度。根据包长度和可用信用(当前pipe,pipe traffic class,subport及subport traffic class),对当前数据包进行是否调度决策。
为了避免cache miss,上述数据结构(pipe,queue,queue array,mbufs)在被访问之前被预取。隐藏预取操作的延迟的策略是在为当前pipe发出预取后立即从当前pipe(在grinder A中)切换到另一个pipe(在grinderB中)。这样就可以在执行切换回pipe(grinder A)之前,有足够的时间完成预取操作。
出pipe状态机将数据存在处理器高速缓存中,因此它尝试从相同的pipe TC和pipe(尽可能多的数据包和信用)发送尽可能多的数据包,然后再移动到下一个活动TC pipe(如果有)或另一个活动pipe。

23.2.4.5. 时间和同步
输出端口被建模为字节槽的传送带,需要由调度器填充用于传输的数据。对于10GbE,每秒需要由调度器填充12.5亿个字节的槽位。如果调度程序填充不够快,只要存在足够的报文和信用,则一些时隙将被闲置并且带宽将被浪费。
原则上,层次调度程序出队操作应由NIC TX触发。通常,一旦NIC TX输入队列的占用率下降到预定义的阈值以下,端口调度器将被唤醒(基于中断或基于轮询,通过连续监视队列占用)来填充更多的数据包进入队列。
23.2.4.5.1. 内部时间引用
调度器需要跟踪信用逻辑的时间演化,因为信用需要基于时间更新(例如,子流量和管道流量整形,流量级上限执行等)。
每当调度程序决定将数据包发送到NIC TX进行传输时,调度器将相应地增加其内部时间参考。因此,以字节为单位保持内部时间基准是方便的,其中字节表示物理接口在传输介质上发送字节所需的持续时间。这样,当报文被调度用于传输时,时间以(n + h)递增,其中n是以字节为单位的报文长度,h是每个报文的成帧开销字节数。
23.2.4.5.2. 内部时间参考重新同步
调度器需要将其内部时间参考对齐到端口传送带的步速。原因是要确保调度程序不以比物理介质的线路速率更多的字节来馈送NIC TX,以防止数据包丢失。
调度程序读取每个出队调用的当前时间。可以通过读取时间戳计数器(TSC)寄存器或高精度事件定时器(HPET)寄存器来获取CPU时间戳。 当前CPU时间戳将CPU时钟数转换为字节数:time_bytes = time_cycles / cycles_per_byte,其中cycles_per_byte是等效于线上一个字节的传输时间的CPU周期数(例如CPU频率 2 GHz和10GbE端口,* cycles_per_byte = 1.6 *)。
调度程序维护NIC time的内部时间参考。 每当分组被调度时,NIC time随分组长度(包括帧开销)增加。在每次出队调用时,调度程序将检查其NIC time的内部引用与当前时间的关系:
- 如果NIC time未来(NIC time> =当前时间),则不需要调整NIC time。这意味着调度程序能够在NIC实际需要这些数据包之前安排NIC数据包,因此NIC TX提供了数据包;
- 如果NIC time过去(NIC时间<当前时间),则NIC time应通过将其设置为当前时间来进行调整。 这意味着调度程序不能跟上NIC字节传送带的速度,因此由于NIC TX的数据包供应不足,所以NIC带宽被浪费了。
23.2.4.5.3. 调度器精度和粒度
调度器往返延迟(SRTD)是指调度器在同一个pipe的两次连续检验之间的时间(CPU周期数)。
为了跟上输出端口(即避免带宽丢失),调度程序应该能够比NIC TX发送的n个数据包更快地调度n个数据包。
假设没有端口超过流量,调度程序需要跟上管道令牌桶配置的每个管道的速率。这意味着管道令牌桶的大小应该设置得足够高,以防止它由于大的SRTD而溢出,因为这将导致管道的信用损失(带宽损失)。
23.2.4.6. 信用逻辑
23.2.4.6.1. 调度决策
当满足以下所有条件时,从(subport S,pipe P,traffic class TC,queue Q)发送下一个分组的调度决定(分组被发送):
- Subport S的Pipe P目前由一个端口调度选择;
- 流量类TC是管道P的最高优先级的主要流量类别;
- 队列Q是管道P的流量类TC内由WRR选择的下一个队列;
- 子接口S有足够的信用来发送数据包;
- 子接口S具有足够的信用流量类TC来发送数据包;
- 管道P有足够的信用来发送数据包;
- 管道P具有足够的信用用于流量类TC发送数据包。
如果满足所有上述条件,则选择分组进行传输,并从子接口S,子接口S流量类TC,管道P,管道P流量类TC中减去必要的信用。
23.2.4.6.2. 帧开销
由于所有数据包长度的最大公约数为1个字节,所以信用单位被选为1个字节。传输n个字节的报文所需的信用数量等于(n + h),其中h等于每个报文的成帧开销字节数。
| # | Packet field | Length | Comments |
|---|---|---|---|
| 1 | 前导码 | 7 | |
| 2 | 帧开始分隔符 | 1 | |
| 3 | 帧校验序列 | 4 | 当mbuf包长度字段中不包含时这里才需要考虑开销。 |
| 4 | 帧间隙 | 12 | |
| 5 | 总 | 24 |
23.2.4.6.3. 流量整形
Subport和pipe的流量整形使用每个subport/pipe的令牌桶来实现。令牌桶使用一个饱和计数器实现,该计数器跟踪可用信用数量。
令牌桶通用参数和操作如下表所示。
| # | Token Bucket Parameter | Unit | Description |
|---|---|---|---|
| 1 | Bucket_rate | 每秒信用值 | 每秒钟添加到桶中的信用 |
| 2 | Bucket_size | 信用值 | 桶最多可以存储多少信用 |
| # | Token Bucket Operation | Description |
|---|---|---|
| 1 Initilization | 桶设置为预定义值,例如 零或一半的桶大小。 | |
| 2 Credit Update | 基于bucket_rate,信用值将根据现有的信息添加到桶中,定期添加或按需添加。信用值不能超过bucket_size定义的上限,因此在存储桶已满时,任何要添加到存储桶中的信用额将被丢弃。 | |
| 3 Credit Consumption | 作为分组调度的结果,从桶中移除必要的信用。只有在桶中有足够的信用来发送完整数据包(数据包的数据包字节和帧开销)时,才能发送数据包。 |
为了实现上述的令牌桶通用操作,当前的设计使用表23.8中所示的数据结构,而令牌桶操作的实现在表23.9中描述。
| # | Token Bucket Field | Unit | Description |
|---|---|---|---|
| 1 | tb_time | Bytes | 最后一次更新信用的时间。以字节为单位而不是秒或CPU周期进行测量,便于信用消耗操作(因为当前时间也以字节为单位)。有关为什么以字节为单位维护时间的说明,请参见第26.2.4.5.1节“内部时间参考”。 |
| 2 | tb_period | Bytes | 自上一次信用更新以来应该经过的时间段,以便桶被授予tb_credits_per_period价值或信用。 |
| 3 | tb_credits_per_period | Bytes | 每tb_period的信用值。 |
| 4 | tb_size | Bytes | 桶大小,即tb_credits的上限。 |
| 5 | tb_credits | Bytes | 当前在桶中的数值。 |
桶速率(以字节为单位)可以用以下公式计算:
bucket_rate = (tb_credits_per_period / tb_period) * r
其中r =端口线路速率(以字节为单位)。
| # | Token Bucket Operation | Description |
|---|---|---|
| 1 | Initilization | tb_credits = 0; or tb_credits = tb_size / 2; |
| 2 | Credit Update | 信用更新操作:1. 每次为端口发送数据包时,请更新该端口的所有子端口和管道的信用,不可行。2. 每次发送数据包时,请更新管道和子接口的信用。 非常准确,但不需要(过多计算)。3. 每次选择管道(即由其中一个grinders选择)时,请更新管道及其子接口的积分。当前的实现使用选项3。根据“出队状态机”小节描述,管道和子接口信用在管道和子接口信用实际使用之前,每出现一次出口流程选择管道时,都将更新。只有在自上次更新以来已经过了至少一个完整的tb_period时,才能通过更新桶级别来实现精度和速度之间的权衡。可以通过选择tb_credits_per_period = 1的tb_period值来实现全精度。当不需要全精度时,通过将tb_credits设置为更大的值可以获得更好的性能。更新操作:n_periods = (time - tb_time) / tb_period; tb_credits += n_periods * tb_credits_per_period; tb_credits = min(tb_credits, tb_size); tb_time += n_periods * tb_period; |
| 3 | Credit Consumption(报文调度) | 作为分组调度的结果,从桶中移除必要的信用。 只有在桶中有足够的信用来发送完整数据包(数据包的数据包字节和帧开销)时,才能发送数据包。调度操作:pkt_credits = pkt_len + frame_overhead; if(tb_credits> = pkt_credits){tb_credits - = pkt_credits;} |
23.2.4.6.4. 流量类
严格优先级调度实现
同一管道内流量级别的严格优先级调度由管理出队状态机实现,该队列按升序选择队列。因此,12..15(TC 3,最低优先级TC),队列8..11(TC 2),队列4..7(TC 1,比TC 0的优先级低),队列0..3(TC 0,最高优先级TC相关联)。
强制上限
Pipe和Subport级别的流量类别不是流量整形,因此在此上下文中不存在令牌桶。通过周期性地重新填充subport/pipe流量信用计数器来执行subport和pipe级别的流量类别的上限,每次为该subport/pipe调度数据包时消耗信用量,如表23.10所述 和表23.11。
| # | Subport or pipe field | Unit | Description |
|---|---|---|---|
| 1 | Tc_time | Bytes | 当前subport/pipe的4个TC的下次更新(上限重新填充)的时间。有关为什么时间以字节为单位进行维护的说明,请参见“内部时间参考”部分。 |
| 2 | Tc_period | Bytes | 当前subport/pipe的4个TC的两次连续更新之间的时间。这是令牌桶tb_period的典型值的两倍。 |
| 3 | Tc_credits_per_period | Bytes | 在每个执行期间tc_period,当前TC允许使用的信用值的上限。 |
| 4 | Tc_credits | Bytes | 目前执行期间余下的当前流量类别可以消耗的信用额的当前上限。 |