hadoop里面可分为HDFS和mapreduce和yarn
HDFS(Hadoop Distributed File System)Hadoop分布式文件系统,说白了就是用了存储数据的.
备份:默认情况下会备份3份数据,备份数可以通过修改来修改备份数.
容错:当备份数据中有一份丢失了,可以其他已备份的数据来还原丢失的那一份.
hdfs写入数据采用的方法,是先写入一台同时马上写入第二台,在写入第二台的同时写入第三台...以此类推,制造出同时写入的假象,其实就是一台一台往下渗透.
hdfs的写入数据机制
三台服务器,块大小设置64M,总共640M,第一台写完第一个64M,然后把已写入的64M发给第二台,第一台在发给第二台64M的同时去读第2个64M,当第二台从第一台服务器写完第一个64M就发送给第三台服务器并从第一台中写入第2个64M..以此类推,知道写完为止.
hdfs读取数据机制
640M,3台,第一台负责第一个64M,第二台负责第二个64,第三台负责第三个64M,第一台完成第一个64去算第四个64...直到算完为止,然后将结果汇总..
hdfs不适合小文件的存储..因为每次存入数据都会namenode中有有一份元数据,如果小文件太多的话,namenode就会内存不足,整个程序就会崩掉.
yarn
yarn负责各个计算框架的任务调度,和资源管理系统,管理集群资源,比如CPU和内存..
mapreduce
分布式计算模型
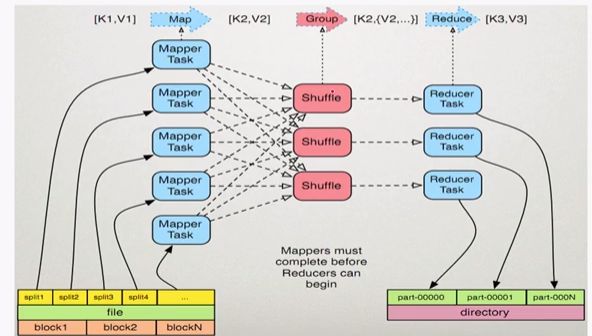
map任务处理
1,读取输入文件内容,解析成key,value对.对输入文件的每一行,解析成key,value对.每一个键值对调用一次map函数.
2,写自己的逻辑,处理输入的key,value,转换成新的key,value输出.
3,对输出的key,value进行区分.
4,对不同分区的数据,按照key进行排序,分组.相同key的value放到一个集合中.
5,(可选)分组后的数据进行归约.
reduce任务处理
1,对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点.
2,对多个map任务的输出进行合并,排序.写reduce函数自己的逻辑,对输入key,value处理,转换成新的key,value输出.
3,把reduce的输出保存到文件中.
hive是一个数据仓库,数据库和数据仓库最大的区别就是数据库是用来存储数据的,数据仓库是用管理数据的,比如展示数据,数据上一些汇总结果后的一些数据展示啊.数据库更可以理解为物理内存,磁盘,数据仓库可以理解为一个展示或汇总的一个工具.
在大数据中hdfs可以理解为一个数据库,hive是一个数据仓库.