原理链接
推荐系统遇上深度学习(三)--DeepFM模型理论和实践
推荐系统遇上深度学习系列:
推荐系统遇上深度学习(一)--FM模型理论和实践:https://www.jianshu.com/p/152ae633fb00
推荐系统遇上深度学习(二)--FFM模型理论和实践:https://www.jianshu.com/p/781cde3d5f3d
文章目录
- 1、背景
- 2、DeepFM模型
- 3、相关知识
- 4、代码解析
- 参考资料
1、背景
特征组合的挑战
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。
之前介绍的因子分解机(Factorization Machines, FM)通过对于每一维特征的隐变量内积来提取特征组合。最终的结果也非常好。但是,虽然理论上来讲FM可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合。
那么对于高阶的特征组合来说,我们很自然的想法,通过多层的神经网络即DNN去解决。
DNN的局限
下面的图片来自于张俊林教授在AI大会上所使用的PPT。
我们之前也介绍过了,对于离散特征的处理,我们使用的是将特征转换成为one-hot的形式,但是将One-hot类型的特征输入到DNN中,会导致网络参数太多:

如何解决这个问题呢,类似于FFM中的思想,将特征分为不同的field:
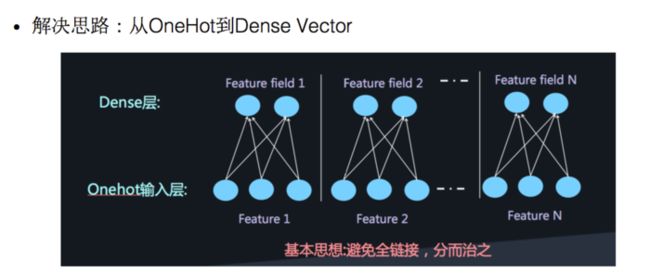
再加两层的全链接层,让Dense Vector进行组合,那么高阶特征的组合就出来了

但是低阶和高阶特征组合隐含地体现在隐藏层中,如果我们希望把低阶特征组合单独建模,然后融合高阶特征组合。

即将DNN与FM进行一个合理的融合:

二者的融合总的来说有两种形式,一是串行结构,二是并行结构


而我们今天要讲到的DeepFM,就是并行结构中的一种典型代表。
2、DeepFM模型
我们先来看一下DeepFM的模型结构:
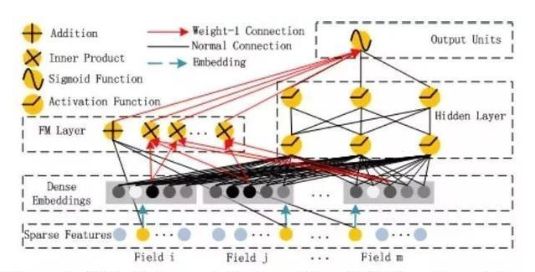
DeepFM包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。DeepFM的预测结果可以写为:

FM部分
FM部分的详细结构如下:
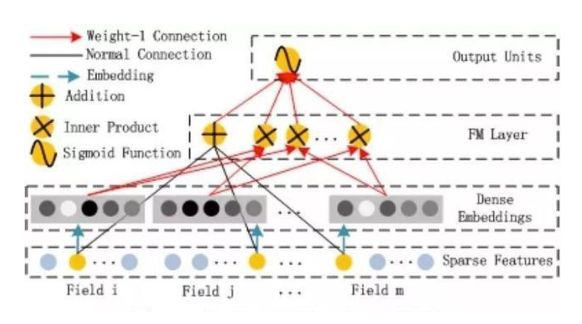
FM部分是一个因子分解机。关于因子分解机可以参阅文章[Rendle, 2010] Steffen Rendle. Factorization machines. In ICDM, 2010.。因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM也可以很好的学习。
FM的输出公式为:
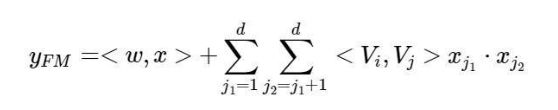
深度部分

深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。

嵌入层(embedding layer)的结构如上图所示。当前网络结构有两个有趣的特性,1)尽管不同field的输入长度不同,但是embedding之后向量的长度均为K。2)在FM里得到的隐变量Vik现在作为了嵌入层网络的权重。
这里的第二点如何理解呢,假设我们的k=5,首先,对于输入的一条记录,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
有关模型具体如何操作,我们可以通过代码来进一步加深认识。
3、相关知识
我们先来讲两个代码中会用到的相关知识吧,代码是参考的github上星数最多的DeepFM实现代码。
Gini Normalization
代码中将CTR预估问题设定为一个二分类问题,绘制了Gini Normalization来评价不同模型的效果。这个是什么东西,不太懂,百度了很多,发现了一个比较通俗易懂的介绍。
假设我们有下面两组结果,分别表示预测值和实际值:
predictions = [0.9, 0.3, 0.8, 0.75, 0.65, 0.6, 0.78, 0.7, 0.05, 0.4, 0.4, 0.05, 0.5, 0.1, 0.1]actual = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
然后我们将预测值按照从小到大排列,并根据索引序对实际值进行排序:
Sorted Actual Values [0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1]
然后,我们可以画出如下的图片:
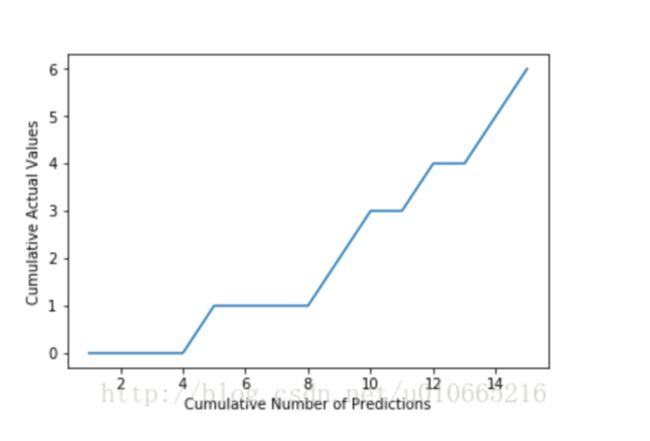
接下来我们将数据Normalization到0,1之间。并画出45度线。

橙色区域的面积,就是我们得到的Normalization的Gini系数。
这里,由于我们是将预测概率从小到大排的,所以我们希望实际值中的0尽可能出现在前面,因此Normalization的Gini系数越大,分类效果越好。
embedding_lookup
在tensorflow中有个embedding_lookup函数,我们可以直接根据一个序号来得到一个词或者一个特征的embedding值,那么他内部其实是包含一个网络结构的,如下图所示:

假设我们想要找到2的embedding值,这个值其实是输入层第二个神经元与embedding层连线的权重值。
之前有大佬跟我探讨word2vec输入的问题,现在也算是有个比较明确的答案,输入其实就是one-hot Embedding,而word2vec要学习的是new Embedding。
4、代码解析
好,一贯的风格,先来介绍几个地址:
原代码地址:https://github.com/ChenglongChen/tensorflow-DeepFM
本文代码地址:https://github.com/princewen/tensorflow_practice/tree/master/Basic-DeepFM-model
数据下载地址:https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
好了,话不多说,我们来看看代码目录吧,接下来,我们将主要对网络的构建进行介绍,而对数据的处理,流程的控制部分,相信大家根据代码就可以看懂。
项目结构
项目结构如下:
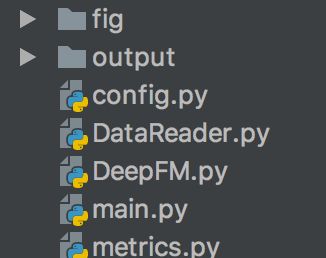
其实还应该有一个存放data的路径。config.py保存了我们模型的一些配置。DataReader对数据进行处理,得到模型可以使用的输入。DeepFM是我们构建的模型。main是项目的入口。metrics是计算normalized gini系数的代码。
模型输入
模型的输入主要有下面几个部分:
self.feat_index = tf.placeholder(tf.int32, shape=[None,None], name='feat_index')self.feat_value = tf.placeholder(tf.float32, shape=[None,None], name='feat_value')self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')self.dropout_keep_fm = tf.placeholder(tf.float32,shape=[None],name='dropout_keep_fm')self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
feat_index是特征的一个序号,主要用于通过embedding_lookup选择我们的embedding。feat_value是对应的特征值,如果是离散特征的话,就是1,如果不是离散特征的话,就保留原来的特征值。label是实际值。还定义了两个dropout来防止过拟合。
权重构建
权重的设定主要有两部分,第一部分是从输入到embedding中的权重,其实也就是我们的dense vector。另一部分就是深度神经网络每一层的权重。第二部分很好理解,我们主要来看看第一部分:
#embeddingsweights['feature_embeddings'] = tf.Variable( tf.random_normal([self.feature_size,self.embedding_size],0.0,0.01), name='feature_embeddings')weights['feature_bias'] = tf.Variable(tf.random_normal([self.feature_size,1],0.0,1.0),name='feature_bias')
weights['feature_embeddings'] 存放的每一个值其实就是FM中的vik,所以它是N * F * K的。其中N代表数据量的大小,F代表feture的大小(将离散特征转换成one-hot之后的特征总量),K代表dense vector的大小。
weights['feature_bias']是FM中的一次项的权重。
Embedding part
这个部分很简单啦,是根据feat_index选择对应的weights['feature_embeddings']中的embedding值,然后再与对应的feat_value相乘就可以了:
# modelself.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * Kfeat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])self.embeddings = tf.multiply(self.embeddings,feat_value)
FM part
首先来回顾一下我们之前对FM的化简公式,之前去今日头条面试还问到过公式的推导。

所以我们的二次项可以根据化简公式轻松的得到,再加上我们的一次项,FM的part就算完了。同时更为方便的是,由于权重共享,我们这里可以直接用Embedding part计算出的embeddings来得到我们的二次项:
# first order termself.y_first_order = tf.nn.embedding_lookup(self.weights['feature_bias'],self.feat_index)self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order,feat_value),2)self.y_first_order = tf.nn.dropout(self.y_first_order,self.dropout_keep_fm[0])# second order term# sum-square-partself.summed_features_emb = tf.reduce_sum(self.embeddings,1) # None * kself.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K# squre-sum-partself.squared_features_emb = tf.square(self.embeddings)self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K#second orderself.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square,self.squared_sum_features_emb)self.y_second_order = tf.nn.dropout(self.y_second_order,self.dropout_keep_fm[1])
DNN part
DNNpart的话,就是将Embedding part的输出再经过几层全链接层:
# Deep componentself.y_deep = tf.reshape(self.embeddings,shape=[-1,self.field_size * self.embedding_size])self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[0])for i in range(0,len(self.deep_layers)): self.y_deep = tf.add(tf.matmul(self.y_deep,self.weights["layer_%d" %i]), self.weights["bias_%d"%I]) self.y_deep = self.deep_layers_activation(self.y_deep) self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[i+1])
最后,我们要将DNN和FM两部分的输出进行结合:
concat_input = tf.concat([self.y_first_order, self.y_second_order, self.y_deep], axis=1)
损失及优化器
我们可以使用logloss(如果定义为分类问题),或者mse(如果定义为预测问题),以及多种的优化器去进行尝试,这些根据不同的参数设定得到:
# lossif self.loss_type == "logloss": self.out = tf.nn.sigmoid(self.out) self.loss = tf.losses.log_loss(self.label, self.out)elif self.loss_type == "mse": self.loss = tf.nn.l2_loss(tf.subtract(self.label, self.out))# l2 regularization on weightsif self.l2_reg > 0: self.loss += tf.contrib.layers.l2_regularizer( self.l2_reg)(self.weights["concat_projection"]) if self.use_deep: for i in range(len(self.deep_layers)): self.loss += tf.contrib.layers.l2_regularizer( self.l2_reg)(self.weights["layer_%d" % I])if self.optimizer_type == "adam": self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8).minimize(self.loss)elif self.optimizer_type == "adagrad": self.optimizer = tf.train.AdagradOptimizer(learning_rate=self.learning_rate, initial_accumulator_value=1e-8).minimize(self.loss)elif self.optimizer_type == "gd": self.optimizer = tf.train.GradientDescentOptimizer(learning_rate=self.learning_rate).minimize(self.loss)elif self.optimizer_type == "momentum": self.optimizer = tf.train.MomentumOptimizer(learning_rate=self.learning_rate, momentum=0.95).minimize( self.loss)
模型效果
前面提到了,我们用logloss作为损失函数去进行模型的参数更新,但是代码中输出了模型的 Normalization 的 Gini值来进行模型评价,我们可以对比一下(记住,Gini值越大越好呦):
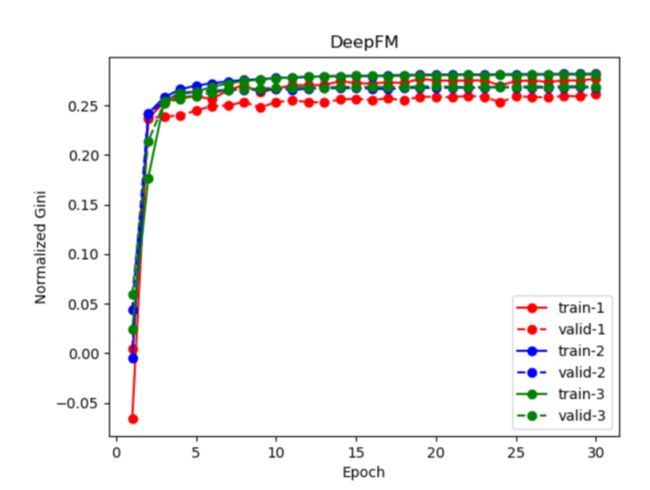
好啦,本文只是提供一个引子,有关DeepFM更多的知识大家可以更多的进行学习呦。
参考资料
1、http://www.360doc.com/content/17/0315/10/10408243_637001469.shtml
2、https://blog.csdn.net/u010665216/article/details/78528261