KYLIN是什么?
上古神兽,直接上图

- 可扩展超快OLAP引擎:
Kylin是为减少在Hadoop上百亿规模数据查询延迟而设计
- Hadoop ANSI SQL 接口:
Kylin为Hadoop提供标准SQL支持大部分查询功能
- 交互式查询能力:
通过Kylin,用户可以与Hadoop数据进行亚秒级交互,在同样的数据集上提供比Hive更好的性能
- 多维立方体(MOLAP Cube):
用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体
- 与BI工具无缝整合:
Kylin提供与BI工具,如Tableau,的整合能力,即将提供对其他工具的整合
- 其他特性:
- Job管理与监控
- 压缩与编码
- 增量更新
- 利用HBase Coprocessor
- 基于HyperLogLog的Dinstinc Count近似算法
- 友好的web界面以管理,监控和使用立方体
- 项目及立方体级别的访问控制安全
- 支持LDAP
Kylin的发展历程
源自ebay上海团队
2014年10月开源
2015年11月毕业
目前最高版本2.2 ,本次介绍的是1.5.1
前奏
事实表和维度表
事实表:事实表是记录具体时间了,包含了每个事件的具体要素,以及具体发生的事情
维度表:是对事实表中事件的要素描述信息。
星型模型和雪花模型
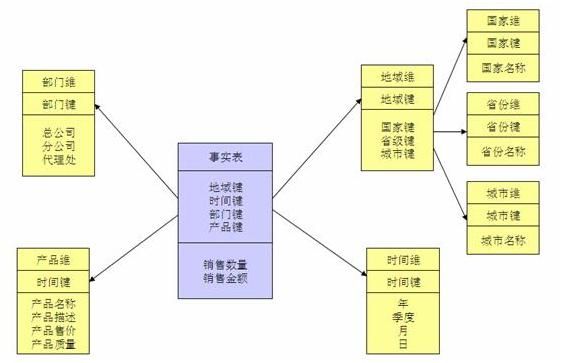
星型模型是一张事实表对应多张维度表
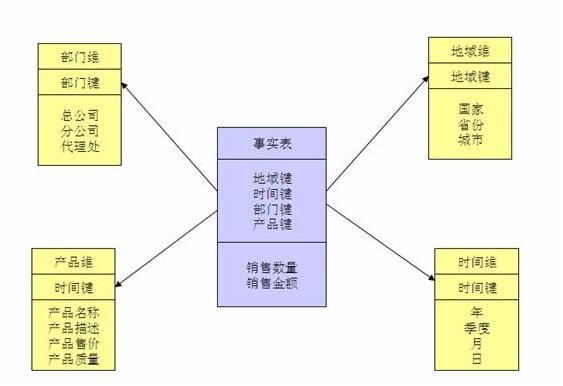
雪花模型,顾名思义,事实表连接事实表再连接维度表
OLAP
联机分析处理
OLAP的基本操作
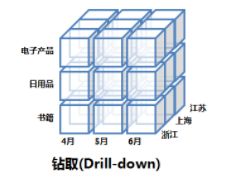
钻取(Drill-down)
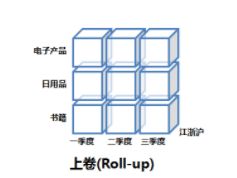
上卷(Roll-up)
切片(Slice)
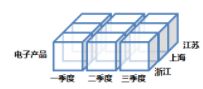
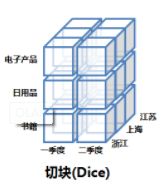
切块(Dice)
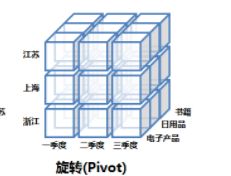
旋转(Pivot)
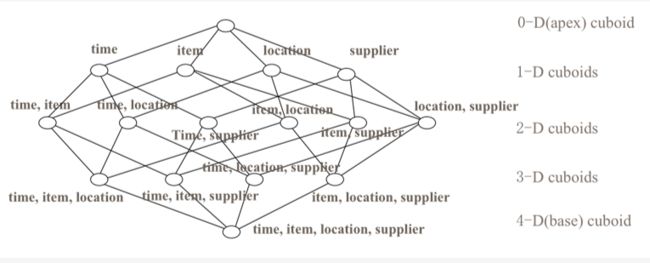
数据立方体 cube
举例说明,什么是cube,
cube是所有的dimensions组合,任一dimensions的组合称为cuboid
kylin整体结构
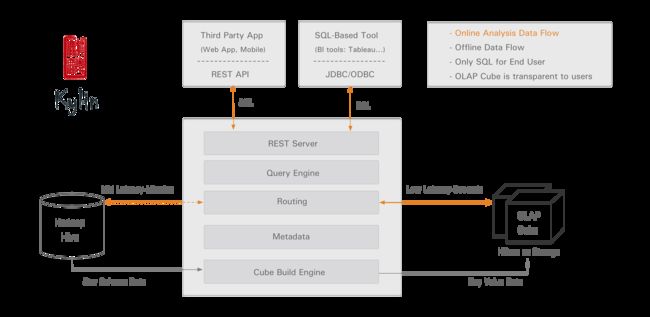
SQL查询
支持大部分sql查询。
cube 构建完成后,sql先被翻译成执行计划,从这个计划,可以执照要查表,怎么join,还有过滤条件等,去找cube,如果命中了cube,会被发送到存储引擎,翻译成scan操作,
group by --cubeid
where 条件--开始结束值
result ,rowkey 反向编码--dimesion值
value -- measure,
利用hbase列存储特性,
Cube的构建
分为两种 ,全量构建,增量构建
全量构建
事实表数据不是按照世间增长的,
事实表的数据比较小,或者更新频率很低
增量构建
有时间维度,构建的时候要选取时间范围
每次构建,将生成一个segment
增量构建
前提:必须要有一个时间维度,用来分割。
起始时间就是上一个cube的结束时间
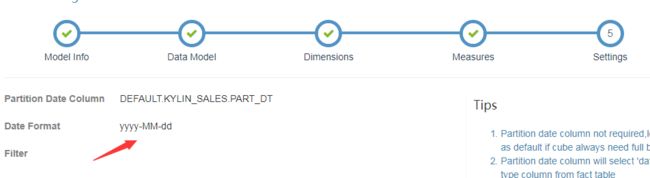
1 model 层面的设置
2 cube 层面的设置
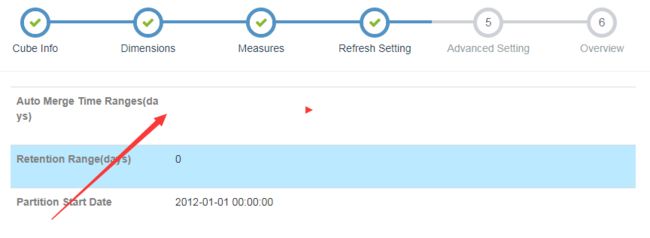
触发增量创建
1 WEB
2 调用rest API

合并
将多个segment合并,起到减少segment的目的
1 手工合并
2 自动合并
举例
设置一个规则 一级28 二级7
A-28 B-7 C-1 D-1 E-1 F-1 G-1 H-1 如果此时加入一个I-1
保留segment
CUBE 优化
Cube 维度优化主要方式
· Cube ID 剪枝优化
· 衍生维度优化
· 聚合组优化
· 强制维度
· 层次维度
· 联合维度
· Cube并发粒度优化
1 维度诅咒
2 的n次方
2 检查cubeid数量
./kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader cube_name
Statistics of test_cube[19700101000000_20170101000000]
Cube statistics hll precision: 14
Total cuboids: 3
Total estimated rows: 180
Total estimated size(MB):0.0013949871063232422
Sampling percentage: 100
Mapper overlap ratio: 1.45
Mapper number: 0
Length of dimensionIDC_INFRASTRUCTURE_DB.HDFS_META.USERNAME is 1
Length of dimension IDC_INFRASTRUCTURE_DB.HDFS_META.GROUPNAMEis 1
|---- Cuboid 11, est row: 91, est MB: 0
|---- Cuboid 01, est row: 43, est MB: 0, shrink: 47.25%
|---- Cuboid 10, est row: 46, est MB: 0, shrink: 50.55%
----------------------------------------------------------------------------
(1) 首先看到Segment整体信息,Cube statistics hll precision指对Cube估计的大小精度,以及Cube中包含的Cuboid数量,对于此Cube中的Segment包含的总行数估计和Segment大小的估计值。这里需要说明的是,Segment预估的大小会影响构建Cube中的步骤,比如常见的mapper和reducer数量,数据split大小等。
(2) 接着可以看到所有Cuboid的详细信息,其结果以树结构的方式罗列出来。每个节点代表一个Cuboid,每个Cuboid都是由一连串的0或1的数字组成,数字串的长度等于有效维度的数量,从左到右的每个数字依次代表Rowkeys设置中的各个维度。如果数字为0,则代表这个Cuboid中不存在相应的维度;如果数字为1,则代表这个Cuboid中存在相应的维度。我们也可以看到,除了最顶端的Cuboid之外,每个Cuboid都有一个父Cuboid,且都比父Cuboid少了一个“1”,也就是比父Cuboid少一个维度。
(3) 最顶端的父Cuboid为Base Cuboid,它直接由源数据计算而来,包含所有的维度。
(4) 对于每层的Cuboid还有其他的统计信息,包括Cuboid行数的估计值,该Cuboid大小的估计值,以及此Cuboid的行数与父Cuboid的对比值(即Shrink值)。
3. 检查Cube大小
在Kylin的Web GUI的Model页面中,我们可以选择一个READY状态的Cube,将鼠标移到该Cube的Cube Size列时,会提示Cube的源数据大小,以及当前Cube的大小除以源数据大小的比例,称为膨胀率(Expansion Rate)。
一般来说,Cube的膨胀率应该在0% ~ 1000%之间,如果有个Cube的膨胀率超过1000%,那么Cube管理员就应该查找原因了,通常原因有以下几个方面:
1)、Cube的维度数量较多,没有进行很好的剪枝;
2)、Cube中存在较高基数的维度,导致这类维度每个Cuboid占用的空间很大,从而造成Cube体积变大;
3)、存在比较占用空间的度量。
对于Cube膨胀率高的情况,需要针对实际的业务需求进行分析,可以考虑通过下面的几种优化方式进行优化:
[Derived Dim]衍生维度优化
衍生维度(Derived Dim):当一个或者多个维度能够从主键中推断出来,那么这些维度列就称之为衍生“Derived” 列。
衍生维度(Derived Dim)优化效果:维度表中的n个维度计算,将Cuboid从2^n 减为2。
使用场景:在星型模型中,有一个用户维度表,表中包含了ID,A,B,C ,其中ID 为PK,在这里通过ID的值就可以确定A,B,C的值,因为A,B,C为ID的Derived。当进行build一个Cube包含A,B,C 的时候,只需要包含ID,并且将A,B,C标记为derived ,这样derived列就不会生成Cuboid 。

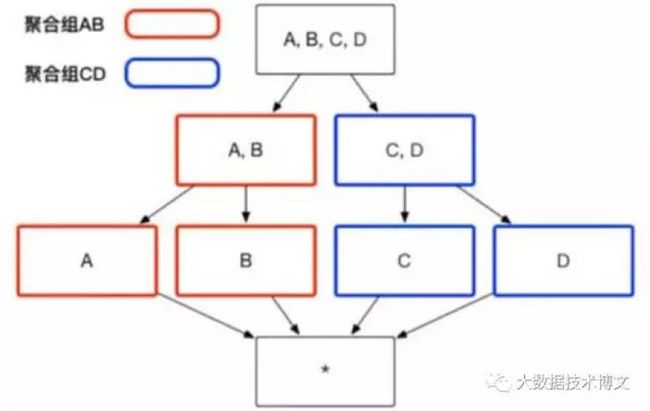
[Aggregation Group]聚合组优化
聚合组(Aggregation Group): 根据业务的维度组合,划分出具有强依赖的组合,这些组合称之为聚合组,在聚合组内,维度之间的组合会预计算,聚合组之间并不交叉预计算,从而减少Cuboid的数量.
聚合组优化效果:如果有4个维度,分别为A,B,C,D,那么就会有16个Cuboid,如果AB和CD分别为聚集组的话,那么Cuboid的数量就缩减为8个。
使用场景:所有维度中,有部分维度之间具有聚合操作的,可以将这些维度放在一个聚合组内。不放在聚合组里面的,就直接进行Base Cube操作。
[Mandatory Dimensions]强制维度
强制维度(Mandatory Dimensions):所有Cubeid中都包含的维度称之为强制维度,不包含强制维度的Cubeid不会计算。
优化效果:只计算包含强制维度的Cubeid,Cubeid的数量会缩减一半。
使用场景:假如有三个维度A,B,C,那么Cuboid就会有8个,分别为ABC,AB,BC,AC,A,B,C,这时将A设置为强制维度,那么就只会计算ABC,AB,AC,A这四个 Cubeid。
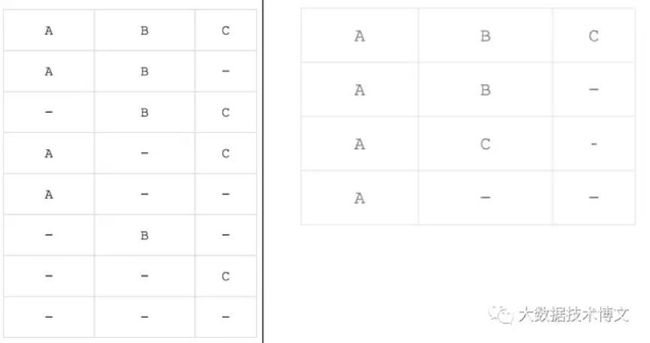
[Hierarchy Dimension]层次维度
层次维度(Hierarchy Dim):某些维度之间具有上下层次关联。
优化效果:如果有三个维度A,B,C 设置为层次维度,那么Cuboid数量将由2^3减为3+1。
使用场景:比较适用于进行下钻分析,比如年月日,省市县这种。
[Joint Dimension]联合维度
联合维度(Joint Dimension):固定用来分组的维度查询。
优化效果:将多个维度优化到一个维度。
使用场景:假如有ABC三个维度,但是在查询的时候只会出现Group by A,B,C,而不会出现Group A,Group by B,Group by A、B等等这种情况,那么就可以将A,B,C设置为联合维度。


调整Cube并发粒度
当Segment中某个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个Hbase Region Server,从而实现Cuboid数据读取的并行化,优化Cube的查询速度。
kylin的默认设置中
kylin.storage.hbase.region-cut-gb=5,
kylin.storage.hbase.min-region-count=1,
kylin.storage.hbase.max-region-count=500
在实际应用中(根据实际数据量调整),可以将
kylin.storage.hbase.region-cut-gb=1
kylin.storage.hbase.min-region-count=2,
kylin.storage.hbase.max-region-count=100,
上面设置为最小为2个分区,每个分区大小为1G,最多设置100个region分区。
ROWKEY的优化
1 编码
kylin有以下几种编码方式
Date
time
integer
Dict
Fixedlength
2 调整rowkey的顺序
在查询中被用作过滤条件的维度放在其他维度前面
经常出现的维度放在前面
基数较高的放在前面