这篇文章是Python爬虫的第一篇,目标是新浪微博的评论,本篇只实现了抓取评论者的id或个性域名,评论,用户名,详细资料的爬取也许会在以后继续发布。
目录
- 准备开发环境
- 确定爬取内容
- 代码实现
- 伪装浏览器,应对反爬虫
- 总结
OK,介绍一下开发环境
Ubuntu 17.04 还用了一台腾讯的云主机,同样是Unix系统。
Chromium 浏览器,抓包很方便。
-
Python 3.5 另外还需要安装两个 Moudle:
bs4requestspymysql
数据库使用
MySql 5.7IDE使用VIM,关于VIM的配置可以去Google搜索,也可以使用我的一个 vimrc,码字还算比较流畅。https://github.com/matianhe/vimConf
环境准备好之后就要确定爬取的内容
-
如图,打开新浪微博官网,最好是移动端网页,页面简单,容易分析,确定爬取评论页的所有用户名和评论。首先要知道网页的结构,HTML基础可以到W3School学习。

-
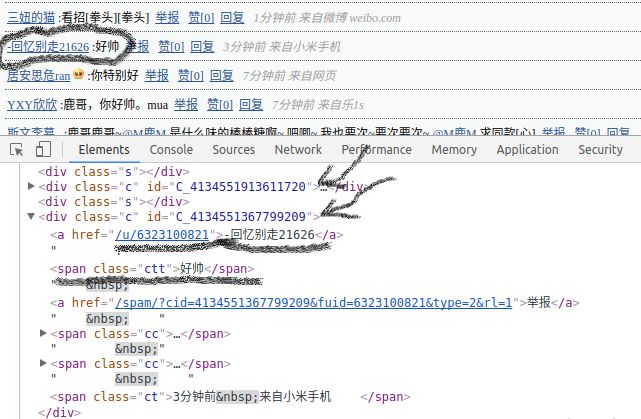
在这里用谷歌浏览器按
F12选择Elements块查看网站源代码。可以发现每一个评论内容都是由一个class为c,id为C_[0-9]的div包裹。帐号ID就是a标签的href属性的内容,用户名是帐号a标签的text内容,评论则是class为ctt的span标签的内容。
 b.png
b.png
写代码
Tips:感觉学框架看官方文档学习最有效率,一定要看!
requests官方文档
bs4官方文档
ubuntu@~:vim comment.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from time import sleep
import queue
import re
import requests
import random # noqa
import tools # noqa
如果有第三方模块导入失败可能是没有安装好模块!可以用pip安装,tools是我自己写的一个功能模块,在文件里可以找到。
eg:
sudo apt install python3-pip
pip3 install bs4
- 第一步就是要找到想要爬的网址,然后精简到最短长度。
page是目标页,之所以设置成变量是想要循环遍历所有评论页。
url = 'https://weibo.cn/comment/FcnGmhbjL?uid=1537790411&rl=0&page=%d' % (page)
- 有了url之后,用requests模块向网页发送请求,它有很多参数,具体可以看官方文档。请求成功之后,他会返回你的网页信息,可以用
.content,.text得到网页内容。
req = requests.get(url, timeout=5, headers=self.header, cookies=self.cookie)
- cookies : 你可以Google一下专业术语,可以把他看作你的帐号密码,有了这一串字符就相当于用帐号密码登录。因为新浪微博查看评论需要登录,所以必须模拟登录的状态,下面会讲到怎么样获取cookie。
- header : 请求头,用来伪装成浏览器,相当于告诉请求的网站,我是××浏览器,我上一个网页是什么,我的接受格式,编码,等等。 主要是为了不被发现是爬虫,其实这样做作用不大,还是会被封IP,主要还是放慢速度。
self.cookie ={‘cookies': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'}
self.header = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686)\
AppleWebKit/537.36 (KHTML, like Gecko) TGUbuntu\
Chromium/59.0.3071109 Chrome/59.0.3071.109\
Safari/537.36',
'referers': 'https://weibo.cn/comment/FcnGmhbjL?\
uid=1537790411&rl=0',
'accept': 'text/html,application/xhtml+xml,application/\
xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4',
'Connection': 'keep-alive',
'Host': 'weibo.cn',
'Upgrade-Insecure-Requests': '1',
}
- 有了网页对象之后就用BeautifulSoup来整理,创建的一个对象,把请求回来的数据文件转换成xml格式,就可以很简单的通过html标签来找数据。
soup = BeautifulSoup(req.content, 'lxml')
- 根据一开始分析的内容包裹情况,用find_all()方法来匹配所有
class为c,id以C_开头的div标签,每个标签就相当与一组帐号、用户名、评论,也就是一开始我们分析的数据存在的位置。之后再用for循环遍历,把每一组的信息分别提取出来,存入MySql数据库,中文表情可能无法存入,请参考MySql数据库更改默认字符集。
tags = soup.find_all('div', class_='c', id=re.compile(r'C_.+'))
for tag in tags:
self.user_domain = re.sub(r'.*/', '', tag.a['href'])
self.user_name = tag.a.text
self.user_comment = tag.find_all('span', 'ctt')[0].text
tools.add_inc((self.user_domain, self.user_name, self.user_comment))
add_inc()方法在tools模块里,功能就是连接数据库,插入数据。我调试的时候先把数据打印到屏幕上最后才写到数据库,建数据库命令也tools里。
def add_inc(data):
with pymysql.connect(host='localhost', user='xxx',
passwd='xxx', db='xxx',
charset='utf8mb4') as cur:
try:
sql = ('insert into luhan_inc(user_domain, user_name,\
user_comment) values (%s, %s, %s)')
cur.execute(sql, data)
except Exception as e:
print(e, 'error')
def c_table_luhan_inc():
sql = 'create table luhan_inc(user_domain varchar(16),\
user_name varchar(32), user_comment varchar(512))'
with pymysql.connect(host='localhost', user='×××××',
passwd='×××××', db='××××') as cur:
try:
cur.execute(sql)
except Exception as e:
print(e)
- sleep()每爬一个网页随机休息一下!!!不然会被封ip的!得等20分钟左右解封。况且从道德方面,速度太快会给的网站带来很大的负担。
-
获取 cookie 和 header
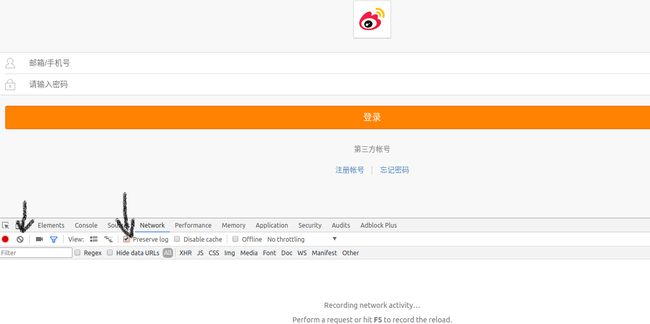
- 打开移动端的登录页面进行抓包,如果显示已经登录需要先退出登录。按
F12调出开发者模式后,选择Network块,所有请求信息都能在这里找到。如果已经存在很多文件,就点红点旁边的清除,然后把preserve log打开(不会清除记录留下我们要找的文件)。到下图的状态之后,输入帐号密码登录。登录网页
- 点击登录之后会出现很多请求文件,我们要找到存有帐号密码的文件。一般为Doc,XHR类型,自己可以多抓几次,熟练之后就会很容易发现。
 带有cookie的文件
带有cookie的文件 - 打开
m.weibo.cn这个文件,会出现详细信息,把需要的header和cookie复制出来就可以用了。
 cookie和header
cookie和header
总结
这篇文章只是粗略的讲了一下过程,还有更换代理IP做多进程没有写,感觉写太多会有点乱,而且速度太快很容易封IP,单机跑速度也还可以,做“小数据”采集够用了,新手学习也还不算难,有问题可以随时评论。完整的代码在下面贴了出来,如果不会用git的话,推荐一个网站去学习廖雪峰的git教程。
补充
- 密码不安全,创建一个密码模块passwd.py。
- 传入固定cookie之后代理IP不起作用,可忽略。
GitHub开源地址:https://github.com/matianhe/crawler。