Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格的要求,适合产生大量数据的互联网服务的数据收集业务。
Kafka高性能的读写主要是借力于操作系统底层的PageCache。
kafka集群模式
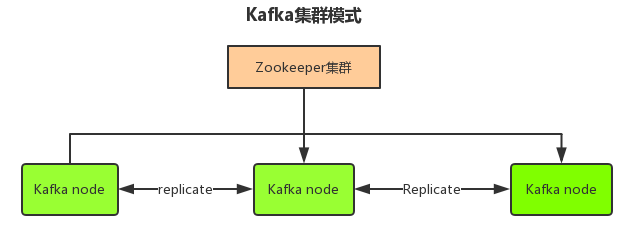
Kafa关注与性能,对数据可靠性要求不是很高。
RocketMQ
阿里开源的,具有高吞吐量、高性能、适合大规模分布式系统的应用。目前在阿里集团被广泛引用于交易、充值、流计算、消息推送、日志流式处理。优点:能够保证顺序消费,提供了丰富的消息拉取和处理的模式,方便水平扩展,实时的消息订阅的机制,承载上亿级别消息的能力。RocketMQ借鉴了Kafka。数据存储关键的两个文件commit log,consume queue。使用Name server做集群的协调和管理,原因是阿里觉得Zookeeper的性能太低了,Name server的源码非常精简。RocketMQ的集群架构有很多种,比如说主从模式、双Master模式、双主双从模式、多主多从模式,RocketMQ刷盘策略也很多,比如同步双写,异步复制 。
RocketMQ的维护是一个痛点,需要非常专业的运维团队。
RabbitMQ
RabbitMQ是使用Erlang语言开发的,性能是非常好的,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,可以使用镜像队列,对性能和吞吐量的要求还在其次。
第二章 RabbitMQ核心概念及AMQP协议
2.1 本章导航
为什么选择RabbitMQ?
RabbitMQ的高性能之道是如何做到的?
什么是AMQP高级协议?
AMQP核心概念是什么?
RabbitMQ整体架构模型是什么样子的?
RabbitMQ消息是如何流转的?
RabbitMQ消息生产与消费
RabbitMQ交换机详解
RabbitMQ队列、绑定、虚拟主机、消息
2.2 初识RabbitMQ
RabbitMQ是开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang语言来编写的,并且RabbitMQ是基于uAMQP协议的。
为什么选择RabbitMQ?
开源,社区活跃,性能优越,稳定性保障;提供可靠性消息投递(confirm)、返回模式(return)。
与SpringAMQP完美的整合,API丰富。
集群模式丰富,表达式配置、HA模式,镜像队列模型。
保证数据不丢失的前提下做到高可靠性、可用性。
RabbitMQ高性能的原因
使用Erlang语言开发,这使得RabbitMQ在Broker之间的数据交互的性能是非常优秀的。Erlang语言的优点:Erlang有着和原生Socket一样的延迟。
2.3 什么是AMQP 高级消息队列协议
AMQP全称:Advanced Message Queuing Protocol
定义:具有现代特征的二进制协议。是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向对象的中间件设计。
AMQP协议模型
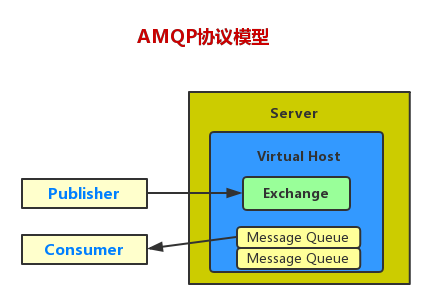
Virtual Host : 虚拟主机
Exchange:交换机
Message Queue:交换机
AMQP核心概念
Server:又称Broker,接受客户端的连接,实现AMQP实体服务。
Connection:连接,应用程序和Broker之间的网络连接。
Channel:网络信道,几乎所有的操作都在channel中进行,Channel是进行消息读写的通道。客户端可建立多个Channel,每个Channel代表一个会话任务。
Message:消息,服务器和应用程序之间传送的数据,由Properties和Body组成。Properties可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body则是消息体的内容。
Virtual Host:虚拟主机,用于进行逻辑隔离,最上层的消息路由。一个Virtual Host里面可以有若干个Exchange和Queue,同一个Virtual Host里面不能有相同名称的Exchange或Queue。
Exchange:交换机,接收消息,根据消息的路由键转发消息到绑定的队列。
Binding:Exchange和Queue之间的虚拟连接,binding中可以包含routing key。
Routing Key:一个路由规则,虚拟机可用它来确定如何路由一个特定消息。
Queue:也称为Message Queue,消息队列,保存消息并将它们转发给消费者。
2.4 RabbitMQ的整体架构
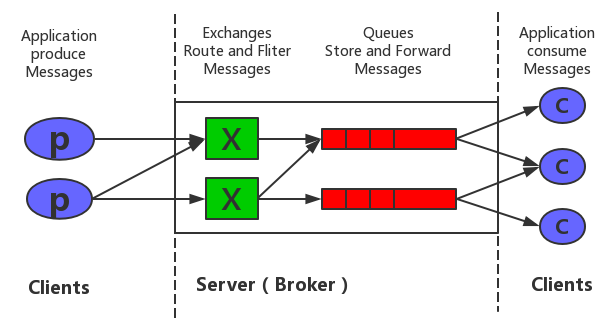
消息生产者投递消息到Exchange,消费者监听Message Queue。
一个Exchange可以绑定多个Queue。
2.5 RabbitMQ安装和使用
2.6 Exchange交换机
交换机类型:direct,fanout,headers,topic
Durability:是否需要持久化,true为持久化。
Auto Delete:当Exchange上绑定的队列都删除后,这个Exchange就会自动删除。
Internal:当前Exchange是否为RabbitMQ内部使用,默认是false。
2.7消息Message
本质上是有Properties和Playload组成。
常用属性delivery mode,headers(自定义属性)。
其他属性:content_type,content_encoding,priority
correlation_id(业务和时间字符串的拼接,做成唯一的id,做消息ack,路由,幂等啊),reply_to(消费失败返回到哪个队列),expiration(过期时间),message_id(消息id),timestamp,user_id,app_id,cluster_id等。
2.8 虚拟主机
虚拟地址,用于进行逻辑隔离,最上层的消息路由。
一个Virtual Host里面可以有若干个Exchange和Queue。
同一个Virtual Host里面不能有相同名称的Exchange或Queue。
3 RabbitMQ高级特性
消息如何保障100%的投递成功?
消息幂等性概念详解。
在海量订单产生的业务高峰期,如何避免消息的重复消费问题?
*Confirm确认消息,Return返回消息。
自定义消费者。
消息的Ack与重回队列
消息限流
TTL消息
死信队列
3.1 消息如何保障100%投递成功
什么是生成端的可靠性投递?
- 保障消息成功的发送出去
- 保障MQ节点的成功接收
- 发送端收到MQ节点(Broker)确认回答
- 完善的消息进行补偿机制
BAT、TMD互联网大厂的解决方案: - 消息落库,对消息状态进行打标(持久化到数据库,适合并发不高的场景)。
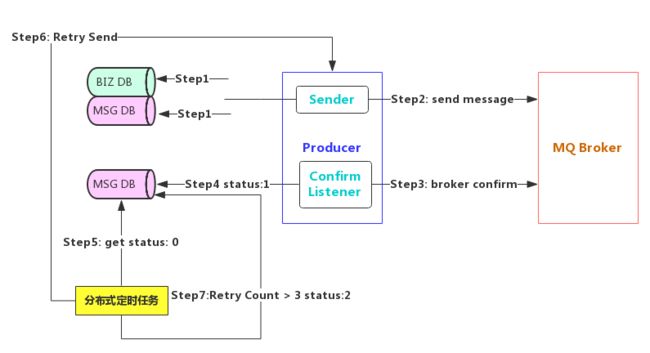
-
消息的延迟投递,做二次确认,回调检查。
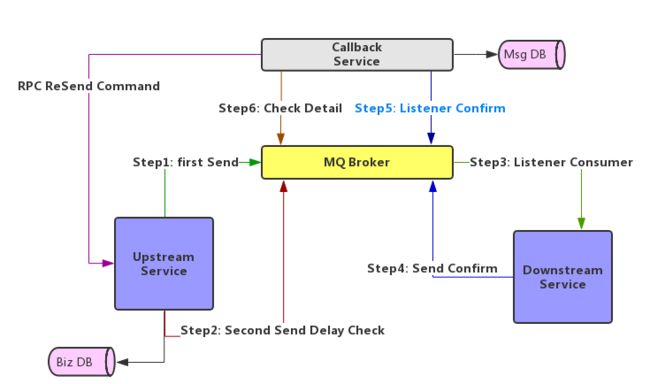 消息延迟投递-回调确认
消息延迟投递-回调确认
消息延迟投递,回调确认的目的是为了在主业务流程消除消息的入库操作,提高系统的吞吐量。Step2和Step1发送的是相同的消息,并且同时发出,不同之处在于Step2投递的是延迟消息。Step3消费者消费完消息后,进入Step4-向一个对列发送消息消费成功的消息,CallbackService的Step5和Step4监听同一个队列,CallbackService监听到消费成功的消息后,将消息持久化到数据库。Step6监听到延迟消息后,去数据库比对该消息是否消费成功,如果消费成功就忽略;如果没有消费成功,就会向上游服务发送RPC通信,告诉延迟检查的消息没有找到,上游服务根据id去业务库中查找业务记录重新拼接消息进行再投递。
3.2 幂等性的概念
我们先看下数据库的乐观锁机制:
比如我们执行一条更新库存的SQL语句:
UPDATE t_reps SET count = count - 1, VERSION = VERSION + 1 WHERE VERSION = 1
我们来分析减库存是如何能应对高并发场景的。更新库存之前要查出当前库存的版本号,更新库存的同时更新版本号(where中带着版本号去作为更新条件)。假如有a,b两个线程同时来更新库存,如果a,b查出的版本号都是1,那么如果a线程更新库存成功的同时版本号也会更新为2,这时候b线程就不能再做减库存的操作了。
幂等性的含义是:一个操作不管并行执行多少次,它的结果永远是相同的。
在海量订单产生的业务高峰期,如何去避免消息的重复消费问题呢?
消费端实现幂等性,就意味着,我们的消息永远不会消费多次,即使我们收到了一条同样的消息多次。
业界主流的幂等性操作:
- 唯一ID+指纹码机制,利用数据库主键去重。
指纹码可能是一些业务规则,并不是系统生成的,它的目的就是为了保障这次操作绝对是唯一的。ID+指纹码拼接作为唯一的主键。
SELECT COUNT(1) FROM T_ORDER WHERE ID = 唯一ID+指纹码
先去查看唯一ID+指纹锁是不是唯一的,如果数据库中已经有了,表明消息已经消费过,就可以忽略了;如果没有,就要进行消费。
优点:实现简单。
坏处:高并发下有数据库写入的性能瓶颈。
解决方案:跟进ID进行分库分表进行算法路由。
利用Redis的原子性去实现
使用Redis进行幂等,需要考虑的问题。
- 第一:我们是否要进行数据库落库,如果落库的话,关键解决的问题是数据库和缓存如何做到原子性?
比如,过来了一条消息,我用Redis的原子性把它过滤掉了。如果没有过滤掉,要进行的操作有 (1)redis中set订单id(2)在数据库中存储订单信息,这时候的关键点就是:如何做到数据库和redis缓存之间的一致性,怎么做到同时成功,同时失败。
- 第二:如果不进行落库,那么都存储到缓存中,如何设置定时同步的策略?
放在缓存之中就能100%的成功吗?
3.3 Confirm确认消息
理解Confirm消息确认机制:
- 消息确认,指生产者投递消息后,如果Broker收到消息,则会给我们生产者一个应答。
- 生产者进行接收应答,用来确定这条消息是否正常的发送到Broker,这种方式也是消息的可靠性投递的核心保障!
如何实现Confirm确认消息? - 第一步:在channel上开启确认模式:channel.confirmSelect()
- 第二步:在channel上添加监听:addConfirmListener,监听成功和失败的返回结果,根据具体的结果对消息进行重新发送、或记录日志等后续处理!什么时候会导致no ack呢?比如磁盘写满了、比如RabbitMQ出现了异常、queue的容量到达上限了。如果网络发生抖动,就有可能ack和no ack都没有处理到,这时候就要利用分布式定时任务去重发消息了。
3.4 Return消息机制
- Return Listener用于处理一些不可路由的消息!
- 我们的消息生产者,通过制定Exchange和RoutingKey,把消息发送到某个队列中去,然后我们的消费者监听队列,进行消费处理!
- 但是在某些情况下,如果我们在发送消息的时候,当前的Exchange不存在或者指定的路由Key路由不到,这个时候如果我们需要监听这种不可达的消息,就要使用Return Listener!
- 在基础API中有一个关键的配置项:Mandatory,如果为true,则监听器会接收到路由不可达的消息,然后进行后续处理;如果为false,那么broker端会自动删除该消息,默认值是false!
- addReturnListener
3.5 死信队列
死信队列:DLX,Dead-Letter-Exchange
利用DLX,当消息在一个队列中变成死信(dead message)之后,它能被重新publish到另一个Exchange,这个Exchange就是DLX。
*消息变成死信的几种情况
- 消息被拒绝(basic.reject/basic.nack)并且requeue=false
- 消息TTL过期
- 队列达到最大长度
死信队列详细描述
- DLX也是一个正常的Exchange,和一般的Exchange没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。
- 当这个队列中有死信时,RabbitMQ就会自动的将这个消息重新发布到设置的Exchange上去,进而被路由到另一个队列。
- 可以监听这个队列中消息做相应的处理,这个特性可以弥补RabbitMQ3.0以前支持的immediate参数的功能。
死信队列设置
- 首先需要设置死信队列的exchange和queue,然后进行绑定:
Exchange: dlx.exchange
Queue:dlx.queue
RoutingKey:#
只要有消息到达了这个队列,都能路由到队列。 - 然后我们进行正常声明交换机、队列、绑定,只不过我们需要在队列上加上一个参数即可:arguments.put("x-dead-letter-exchange", "dlx.exchage")。