标准库
1.collections
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
namedtuple的用法namedtuple('名称', [属性list])
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
>>> isinstance(p, Point)
True
>>> isinstance(p, tuple)
True
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value)
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出,字符'g'、'm'、'r'各出现了两次,其他字符各出现了一次。
most_common(n=None)是Counter实例对象的一个方法,从大到小返回可迭代对象的数量的一个list。
In [4]: from collections import Counter
In [5]: Counter("fhewiurfjoweri").most_common()
Out[5]:
[('e', 2), ('f', 2), ('i', 2), ('r', 2), ('w', 2),('h', 1), ('j', 1), ('o', 1), ('u', 1)]
In [6]: Counter("fhewiurfjoweri").most_common(2) #选择前两个
Out[6]: [('e', 2), ('f', 2)]
装饰器之回调函数的语法糖@
装饰器本身就是一种函数,它的作用可以增加某些函数的功能(无需重新定义函数)。例如在1000个不同的函数之前添加某个相同功能,这时只需装饰器修饰一下就可以完成。
装饰器并不是凭空产生的魔法,它所依赖的就是函数对象可以作为参数进行传递,函数定义也可以返回函数对象,因此产生出意想不到的黑魔法。注意返回结果Fun()与Fun和调用Fun()与Fun的区别。
装饰器本身与闭包很类似,函数嵌套函数,并将函数对象返回。
装饰器分两类
- 函数装饰函数
- 类装饰函数
def hello(fn):
def wrapper():
print "hello, %s" % fn.__name__
fn()
print "goodby, %s" % fn.__name__
return wrapper
@hello
def foo():
print "i am foo"
foo()
当你运行代码,你会看到如下输出:
hello, foo
i am foo
goodby, foo
你可以看到如下的东西:
1)函数foo前面有个@hello的“注解”,hello就是我们前面定义的函数hello
2)在hello函数中,其需要一个fn的参数(这就用来做回调的函数)
3)hello函数中返回了一个inner函数wrapper,这个wrapper函数回调了传进来的fn,并在回调前后加了两条语句。
1.Decorator 的本质
对于Python的这个@注解语法糖- Syntactic Sugar 来说,当你在用某个@decorator来修饰某个函数func时,如下所示:
@decorator
def func():
pass
其解释器会解释成下面这样的语句:
func = decorator(func)
这不就是把一个函数当参数传到另一个函数中,然后再回调吗?是的,但是,我们需要注意,那里还有一个赋值语句,把decorator这个函数的返回值赋值回了原来的func。 根据《函数式编程》中的first class functions中的定义的,你可以把函数当成变量来使用,所以,decorator必需得返回了一个函数出来给func,这就是所谓的**higher order function **高阶函数,不然,后面当func()调用的时候就会出错。 就我们上面那个hello.py里的例子来说,
@hello
def foo():
print "i am foo"
被解释成了:
foo = hello(foo)
是的,这是一条语句,而且还被执行了。你如果不信的话,你可以写这样的程序来试试看:
def fuck(fn):
print "fuck %s!" % fn.__name__[::-1].upper()
@fuck
def wfg():
pass
没了,就上面这段代码,没有调用wfg()的语句,你会发现, fuck函数被调用了,而且还很NB地输出了我们每个人的心声(GFW:防火墙)!
再回到我们hello.py的那个例子,我们可以看到,hello(foo)返回了wrapper()函数,所以,foo其实变成了wrapper的一个变量,而后面的foo()执行其实变成了wrapper()。
知道这点本质,当你看到有多个decorator或是带参数的decorator,你也就不会害怕了。
比如:多个decorator
@decorator_one
@decorator_two
def func():
pass
相当于:
func = decorator_one(decorator_two(func))
比如:带参数的decorator:
@decorator(arg1, arg2)
def func():
pass
相当于:
func = decorator(arg1,arg2)(func)
这意味着decorator(arg1, arg2)这个函数需要返回一个“真正的decorator”。
2.带参数及多个Decrorator
我们来看一个有点意义的例子:
HTML.py
def makeHtmlTag(tag, *args, **kwds):
def real_decorator(fn):
css_class = " class='{0}'".format(kwds["css_class"]) \
if "css_class" in kwds else ""
def wrapped(*args, **kwds):
return "<"+tag+css_class+">" + fn(*args, **kwds) + ""
return wrapped
return real_decorator
@makeHtmlTag(tag="b", css_class="bold_css")
@makeHtmlTag(tag="i", css_class="italic_css")
def hello():
return "hello world"
print hello()
# 输出:
# hello world
在上面这个例子中,我们可以看到:makeHtmlTag有两个参数。所以,为了让 hello = makeHtmlTag(arg1, arg2)(hello) 成功,makeHtmlTag 必需返回一个decorator(这就是为什么我们在makeHtmlTag中加入了real_decorator()的原因),这样一来,我们就可以进入到 decorator 的逻辑中去了—— decorator得返回一个wrapper,wrapper里回调hello。看似那个makeHtmlTag() 写得层层叠叠,但是,已经了解了本质的我们觉得写得很自然。
什么,你觉得上面那个带参数的Decorator的函数嵌套太多了,你受不了。好吧,没事,我们看看下面的方法。
3.class式的 Decorator
首先,先得说一下,decorator的class方式,还是看个示例:
class myDecorator(object):
def __init__(self, fn):
print "inside myDecorator.__init__()"
self.fn = fn
def __call__(self):
self.fn()
print "inside myDecorator.__call__()"
@myDecorator
def aFunction():
print "inside aFunction()"
print "Finished decorating aFunction()"
aFunction() #调用了__call__方法
# 输出:
# inside myDecorator.__init__()
# Finished decorating aFunction()
# inside aFunction()
# inside myDecorator.__call__()
@myDecorator
def aFunction():
print "inside aFunction()"
等价于
aFunction=myDecorator(aFunction) #aFunction是一个实例对象
上面这个示例展示了,用类的方式声明一个decorator。我们可以看到这个类中有两个成员:
1)一个是__init__(),这个方法是在我们给某个函数decorator时被调用,所以,需要有一个fn的参数,也就是被decorator的函数。
2)一个是__call__(),这个方法是在我们调用被decorator函数时被调用的。
上面输出可以看到整个程序的执行顺序。
这看上去要比“函数式”的方式更易读一些。
下面,我们来看看用类的方式来重写上面的html.py的代码:
HTML.py
class makeHtmlTagClass(object):
def __init__(self, tag, css_class=""):
self._tag = tag
self._css_class = " class='{0}'".format(css_class) \
if css_class !="" else ""
def __call__(self, fn):
def wrapped(*args, **kwargs):
return "<" + self._tag + self._css_class+">" \
+ fn(*args, **kwargs) + ""
return wrapped
@makeHtmlTagClass(tag="b", css_class="bold_css")
@makeHtmlTagClass(tag="i", css_class="italic_css")
def hello(name):
return "Hello, {}".format(name)
print hello("Hao Chen")
上面这段代码中,我们需要注意这几点:
1)如果decorator有参数的话,__init__() 成员就不能传入fn了,而fn是在__call__的时候传入的。
2)这段代码还展示了 wrapped(*args, **kwargs) 这种方式来传递被decorator函数的参数。(其中:args是一个参数列表,kwargs是参数dict。
4.用Decorator设置函数的调用参数
你有三种方法可以干这个事:
第一种,通过 **kwargs,这种方法decorator会在kwargs中注入参数。
def decorate_A(function):
def wrap_function(*args, **kwargs):
kwargs['str'] = 'Hello!'
return function(*args, **kwargs)
return wrap_function
@decorate_A
def print_message_A(*args, **kwargs):
print(kwargs['str'])
print_message_A()
第二种,约定好参数,直接修改参数
def decorate_B(function):
def wrap_function(*args, **kwargs):
str = 'Hello!'
return function(str, *args, **kwargs)
return wrap_function
@decorate_B
def print_message_B(str, *args, **kwargs):
print(str)
print_message_B()
第三种,通过 *args 注入
def decorate_C(function):
def wrap_function(*args, **kwargs):
str = 'Hello!'
#args.insert(1, str)
args = args +(str,)
return function(*args, **kwargs)
return wrap_function
class Printer:
@decorate_C
def print_message(self, str, *args, **kwargs):
print(str)
p = Printer()
p.print_message()
4.Decorator的副作用
到这里,我相信你应该了解了整个Python的decorator的原理了。
相信你也会发现,被decorator的函数其实已经是另外一个函数了,对于最前面那个hello.py的例子来说,如果你查询一下foo.__name__的话,你会发现其输出的是“wrapper”,而不是我们期望的“foo”,这会给我们的程序埋一些坑。所以,Python的functool包中提供了一个叫wrap的decorator来消除这样的副作用。下面是我们新版本的hello.py。
Hello.py
from functools import wraps
def hello(fn):
@wraps(fn)
def wrapper():
print "hello, %s" % fn.__name__
fn()
print "goodby, %s" % fn.__name__
return wrapper
@hello
def foo():
'''foo help doc'''
print "i am foo"
pass
foo()
print foo.__name__ #输出 foo
print foo.__doc__ #输出 foo help doc
当然,即使是你用了functools的wraps,也不能完全消除这样的副作用。
来看下面这个示例:
from inspect import getmembers, getargspec
from functools import wraps
def wraps_decorator(f):
@wraps(f)
def wraps_wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wraps_wrapper
class SomeClass(object):
@wraps_decorator
def method(self, x, y):
pass
obj = SomeClass()
for name, func in getmembers(obj, predicate=inspect.ismethod):
print "Member Name: %s" % name
print "Func Name: %s" % func.func_name
print "Args: %s" % getargspec(func)[0]
# 输出:
# Member Name: method
# Func Name: method
# Args: []
你会发现,即使是你你用了functools的wraps,你在用getargspec时,参数也不见了。
要修正这一问,我们还得用Python的反射来解决,下面是相关的代码:
def get_true_argspec(method):
argspec = inspect.getargspec(method)
args = argspec[0]
if args and args[0] == 'self':
return argspec
if hasattr(method, '__func__'):
method = method.__func__
if not hasattr(method, 'func_closure') or method.func_closure is None:
raise Exception("No closure for method.")
method = method.func_closure[0].cell_contents
return get_true_argspec(method)
当然,我相信大多数人的程序都不会去getargspec。所以,用functools的wraps应该够用了。
5.一些decorator的示例
好了,现在我们来看一下各种decorator的例子:
1)给函数调用做缓存
这个例实在是太经典了,整个网上都用这个例子做decorator的经典范例,因为太经典了,所以,我这篇文章也不能免俗。
from functools import wraps
def memo(fn):
cache = {}
miss = object()
@wraps(fn)
def wrapper(*args):
result = cache.get(args, miss)
if result is miss:
result = fn(*args)
cache[args] = result
return result
return wrapper
@memo
def fib(n):
if n < 2:
return n
return fib(n - 1) + fib(n - 2)
上面这个例子中,是一个斐波拉契数例的递归算法。我们知道,这个递归是相当没有效率的,因为会重复调用。比如:我们要计算fib(5),于是其分解成fib(4) + fib(3),而fib(4)分解成fib(3)+fib(2),fib(3)又分解成fib(2)+fib(1)…… 你可看到,基本上来说,fib(3), fib(2), fib(1)在整个递归过程中被调用了两次。
而我们用decorator,在调用函数前查询一下缓存,如果没有才调用了,有了就从缓存中返回值。一下子,这个递归从二叉树式的递归成了线性的递归。
2)Profiler的例子
这个例子没什么高深的,就是实用一些。
import cProfile, pstats, StringIO
def profiler(func):
def wrapper(*args, **kwargs):
datafn = func.__name__ + ".profile" # Name the data file
prof = cProfile.Profile()
retval = prof.runcall(func, *args, **kwargs)
#prof.dump_stats(datafn)
s = StringIO.StringIO()
sortby = 'cumulative'
ps = pstats.Stats(prof, stream=s).sort_stats(sortby)
ps.print_stats()
print s.getvalue()
return retval
return wrapper
3)注册回调函数
下面这个示例展示了通过URL的路由来调用相关注册的函数示例:
class MyApp():
def __init__(self):
self.func_map = {}
def register(self, name):
def func_wrapper(func):
self.func_map[name] = func
return func
return func_wrapper
def call_method(self, name=None):
func = self.func_map.get(name, None)
if func is None:
raise Exception("No function registered against - " + str(name))
return func()
app = MyApp()
@app.register('/')
def main_page_func():
return "This is the main page."
@app.register('/next_page')
def next_page_func():
return "This is the next page."
print app.call_method('/')
print app.call_method('/next_page')
注意:
1)上面这个示例中,用类的实例来做decorator。
2)decorator类中没有__call__(),但是wrapper返回了原函数。所以,原函数没有发生任何变化。
4)给函数打日志
下面这个示例演示了一个logger的decorator,这个decorator输出了函数名,参数,返回值,和运行时间。
from functools import wraps
def logger(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
ts = time.time()
result = fn(*args, **kwargs)
te = time.time()
print "function = {0}".format(fn.__name__)
print " arguments = {0} {1}".format(args, kwargs)
print " return = {0}".format(result)
print " time = %.6f sec" % (te-ts)
return result
return wrapper
@logger
def multipy(x, y):
return x * y
@logger
def sum_num(n):
s = 0
for i in xrange(n+1):
s += i
return s
print multipy(2, 10)
print sum_num(100)
print sum_num(10000000)
上面那个打日志还是有点粗糙,让我们看一个更好一点的(带log level参数的):
import inspect
def get_line_number():
return inspect.currentframe().f_back.f_back.f_lineno
def logger(loglevel):
def log_decorator(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
ts = time.time()
result = fn(*args, **kwargs)
te = time.time()
print "function = " + fn.__name__,
print " arguments = {0} {1}".format(args, kwargs)
print " return = {0}".format(result)
print " time = %.6f sec" % (te-ts)
if (loglevel == 'debug'):
print " called_from_line : " + str(get_line_number())
return result
return wrapper
return log_decorator
但是,上面这个带loglevel参数的有两具不好的地方,
1) loglevel不是debug的时候,还是要计算函数调用的时间。
2) 不同level的要写在一起,不易读。
我们再接着改进:
import inspect
def advance_logger(loglevel):
def get_line_number():
return inspect.currentframe().f_back.f_back.f_lineno
def _basic_log(fn, result, *args, **kwargs):
print "function = " + fn.__name__,
print " arguments = {0} {1}".format(args, kwargs)
print " return = {0}".format(result)
def info_log_decorator(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
result = fn(*args, **kwargs)
_basic_log(fn, result, args, kwargs)
return wrapper
def debug_log_decorator(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
ts = time.time()
result = fn(*args, **kwargs)
te = time.time()
_basic_log(fn, result, args, kwargs)
print " time = %.6f sec" % (te-ts)
print " called_from_line : " + str(get_line_number())
return wrapper
if loglevel is "debug":
return debug_log_decorator
else:
return info_log_decorator
1)我们分了两个log level,一个是info的,一个是debug的,然后我们在外尾根据不同的参数返回不同的decorator。
2)我们把info和debug中的相同的代码抽到了一个叫_basic_log的函数里,DRY原则。
5)一个MySQL的Decorator
下面这个decorator是我在工作中用到的代码,我简化了一下,把DB连接池的代码去掉了,这样能简单点,方便阅读。
import umysql
from functools import wraps
class Configuraion:
def __init__(self, env):
if env == "Prod":
self.host = "coolshell.cn"
self.port = 3306
self.db = "coolshell"
self.user = "coolshell"
self.passwd = "fuckgfw"
elif env == "Test":
self.host = 'localhost'
self.port = 3300
self.user = 'coolshell'
self.db = 'coolshell'
self.passwd = 'fuckgfw'
def mysql(sql):
_conf = Configuraion(env="Prod")
def on_sql_error(err):
print err
sys.exit(-1)
def handle_sql_result(rs):
if rs.rows > 0:
fieldnames = [f[0] for f in rs.fields]
return [dict(zip(fieldnames, r)) for r in rs.rows]
else:
return []
def decorator(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
mysqlconn = umysql.Connection()
mysqlconn.settimeout(5)
mysqlconn.connect(_conf.host, _conf.port, _conf.user, \
_conf.passwd, _conf.db, True, 'utf8')
try:
rs = mysqlconn.query(sql, {})
except umysql.Error as e:
on_sql_error(e)
data = handle_sql_result(rs)
kwargs["data"] = data
result = fn(*args, **kwargs)
mysqlconn.close()
return result
return wrapper
return decorator
@mysql(sql = "select * from coolshell" )
def get_coolshell(data):
... ...
... ..
6)线程异步
下面量个非常简单的异步执行的decorator,注意,异步处理并不简单,下面只是一个示例。
rom threading import Thread
from functools import wraps
def async(func):
@wraps(func)
def async_func(*args, **kwargs):
func_hl = Thread(target = func, args = args, kwargs = kwargs)
func_hl.start()
return func_hl
return async_func
if __name__ == '__main__':
from time import sleep
@async
def print_somedata():
print 'starting print_somedata'
sleep(2)
print 'print_somedata: 2 sec passed'
sleep(2)
print 'print_somedata: 2 sec passed'
sleep(2)
print 'finished print_somedata'
def main():
print_somedata()
print 'back in main'
print_somedata()
print 'back in main'
main()
迭代器之__iter__和_next_
1.迭代器介绍
概念上说,迭代器是一个对容器实现遍历的工具。遍历,就是循环的另一种说法
在python中,迭代器的概念实际上与java,c++中的STL各容器的迭代器的概念是一致的,都是为容器中元素的遍历操作提供一层接口,将对容器的遍历的操作与容器的具体实现分离开。
迭代器的本质就是一个对象,具有内存空间。
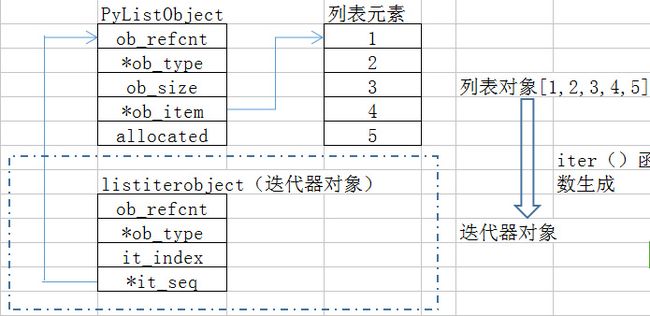
如图,PyListObject对象的迭代器对象只是对PyListObject对象做了一个简单的包装,在迭代器中,维护了当前访问的元素在PylistObject对象中的序号:it_index。通过这个序号,listiterobject对象就可以实现对PyListObject的遍历。

迭代器快速入门:
目前可迭代对象包括:字符串,列表,元组,字典,集合
>>> lst = range(2)
>>> it = iter(lst) #事实上,是调用了lst的__iter__()的方法
>>> it #迭代器对象
使用迭代器的next()方法可以访问下一个元素:
>>> it.next()
0
那么在这个例子中,我们已经访问到了最后一个元素1,再使用next()方法会怎样呢?
>>> it.next()
Traceback (most recent call last):
File "", line 1, in
StopIteration
Python遇到这样的情况时将会抛出StopIteration异常。事实上,Python正是根据是否检查到这个异常来决定是否停止迭代的。
生成器表达式(Generator expression)和列表解析(List Comprehension)
(x+1 for x in lst) #生成器表达式,返回迭代器。外部的括号可在用于参数时省略
[x+1 for x in lst] #列表解析,返回list
迭代器(iterator),容器,及可迭代对象(iterable)的区别。可参考
http://foofish.net/blog/109/iterators-vs-generators
迭代器对象不支持重新迭代,也就是同一个迭代器对象无法多次迭代。所以要确定好for之后的是迭代对象还是迭代器
>>>l=iter([1,2,3,4])
>>>[i for i in I]
[1,2,3,4]
>>>[i for i in I]
[]
2.通过__iter__和__next__自定义可迭代对象和迭代器
关于可迭代对象和迭代器对象:
- 可迭代对象是实现了
__iter__()方法的对象,__iter__()可以返回一个迭代器对象。 可迭代对象(list,tuple,dict)本身只是一个容器,并没有遍历其元素的方法 - 迭代器对象是实现了
__next__()和__iter__()方法的对象,其中他的__iter__()返回的是迭代器对象本身。
通过以上两点,我们就可以自定义迭代器和可迭代对象了。
class ListIterable(object):#定义一个可迭代对象,实现__iter__方法
def __init__(self, data):
self.__data = data
def __iter__(self):
print("call iterable __iter__().")
return ListIterator(self.__data)
class ListIterator(object):#定义一个迭代器,实现__iter__和__next__方法
def __init__(self, data):
self.__data = data
self.__count = 0
def __iter__(self): #迭代器本身也是一个可以迭代的对象
print("call iterator __iter__().")
return self
def __next__(self):
print("call iterator __next__().")
if self.__count < len(self.__data):
val = self.__data[self.__count]
self.__count += 1
return val
else:
raise StopIteration
a = ListIterable([1,2,3,4,5,6])
b = iter(a)
print(a)
print(b)
===================================
call iterable __iter__().
<__main__.ListIterable object at 0x102102160>
<__main__.ListIterator object at 0x1021022b0>
a = ListIterable([1,2,3,4,5,6])
lis = [i for i in a]
print(lis)
===================================
call iterable __iter__().
call iterator __next__().
call iterator __next__().
call iterator __next__().
call iterator __next__().
call iterator __next__().
call iterator __next__().
call iterator __next__().
[1, 2, 3, 4, 5, 6]
- 我们在使用迭代工具对iterable对象进行迭代的时候首先调用的是iterable的
__iter__()方法,返回一个迭代器对象,也就是ListIterator的实例。 - 然后再遍历的时候是调用iterator的next方法输出值。这样就可以解释了为什么这样处理能够多次迭代了,因为每次使用迭代工具迭代的时候都会调用
__iter__()返回一个新的迭代器对象,这样就相当于创建多个迭代器了,自然可以看起来是重复迭代了!
3.for循环的本质
在for循环中,Python将自动调用工厂函数iter()获得迭代器,自动调用next()获取元素,还完成了检StopIteration异常的工作。上述代码可以写成如下的形式,你一定非常熟悉:
for val in lst:
print val
首先Python将对关键字in后的对象调用iter函数获取迭代器,然后调用迭代器的next方法获取元素,直到抛出StopIteration异常。对迭代器调用iter函数时将返回迭代器自身,所以迭代器也可以用于for语句中,不需要特殊处理。
迭代器的优点就是它不要求你事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代至某个元素时才计算该元素(事实上是该完成什么功能由迭代器中的next方法定义),而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件,或是斐波那契数列等等。这个特点被称为延迟计算或惰性求值(Lazy evaluation)。
生成器之yield
生成器是一个函数,函数中使用关键字yield,函数返回的结果是一个generator对象。
>>> def get():
... print('hi')
... yield 0
... yield 1
... yield 3
...
>>> get
>>> f = get()
>>> f
yield的作用相当于return,但是return只能返回一个值并结束函数;但yield可以保留返回值并继续函数执行。
- 第一次调用生成器的next方法时,生成器才开始执行生成器函数(而不是构建生成器时),直到遇到yield时暂停执行(挂起),并且yield的参数将作为此次next方法的返回值;
>>> f.next()
hi
0
- 之后每次调用生成器的next方法,生成器将从上次暂停执行的位置恢复执行生成器函数,直到再次遇到yield时暂停,并且同样的,yield的参数将作为next方法的返回值;
>>> f.next()
1
>>> f.next()
3
- 如果当调用next方法时生成器函数结束(遇到空的return语句或是到达函数体末尾),则这次next方法的调用将抛出StopIteration异常(即for循环的终止条件);
>>> f.next()
Traceback (most recent call last):
File "", line 1, in
StopIteration
从上面看来,生成器就是一种迭代器。生成器拥有next方法并且行为与迭代器完全相同,这意味着生成器也可以用于Python的for循环中。另外,对于生成器的特殊语法支持使得编写一个生成器比自定义一个常规的迭代器要简单不少,所以生成器也是最常用到的特性之一。
重点:
-
当调用生成器函数时,函数体本身不执行,必须调用next方法才执行。
>>> def func(): ... print('im here') ... yield 0 ... yield 1 ... >>> func>>> f = func() >>> f.next() im here 0 注意yield表达式返回的是None,所以对于b=yield a,next返回的是yield后面a的值,并保持现场,跳出函数体。而b必须在第二次调用next的时候才被赋值成None。
-
生成器函数在每次暂停执行时,函数体内的所有变量都将被封存(freeze)在生成器中,并将在恢复执行时还原,并且类似于闭包,即使是同一个生成器函数返回的生成器,封存的变量也是互相独立的。
我们的小例子中并没有用到变量,所以这里另外定义一个生成器来展示这个特点:In [1]: def fibonacci(): ...: a = b =1 ...: yield a ...: yield b ...: while True: ...: a,b = b,a+b ...: yield b ...: In [2]: for num in fibonacci():#for语句会自动调用迭代器的next方法 ...: if num>100: ...: break ...: print(num) 1 1 2 3 5 8 13 21 34 55 89看到while True可别太吃惊,因为生成器可以挂起,所以是延迟计算的,无限循环并没有关系。这个例子中我们定义了一个生成器用于获取斐波那契数列。
生成器函数FQA
1.生成器函数可以带参数吗?当然可以,它本身就是一个函数
>>> def counter(start=0):
... while True:
... yield start
... start += 1
2.既然生成器函数也是函数,那么它可以使用return输出返回值吗?不可以,同一函数不可以既有return又有yield。
send(value)
send是除next外另一个恢复生成器的方法。Python 2.5中,yield语句变成了yield表达式,这意味着yield现在可以有一个值,而这个值就是在生成器的send方法被调用从而恢复执行时,调用send方法的参数。
注意点:
- send的值是赋给等号左边的变量,而不是yield右边的变量
- 没有send,
x=yield y中的x永远是None - send()和next()的返回值都是yield后面的值
- 生成器.send(None)等价于生成器.next()
- send(10)可以理解为先
x=10再next
In [3]: def repeater():
...: n = 0
...: while True:
...: n = yield n
...: print(n)
...:
In [4]: r = repeater()
In [8]: r.__next__()
Out[8]: 0
In [9]: r.__next__()
None
In [10]: r.__next__()
None
In [11]: r.send(10)
10
Out[11]: 10
close():
这个方法用于关闭生成器。对关闭的生成器后再次调用next或send将抛出StopIteration异常。
描述符之@property
1.__set__,__get__,__delete__的定义描述符
描述符就是将某种特殊类型的实例指派给另一个类的属性。其中某种特殊类型的实例是定义了以下一种或者多种魔法方法的实例:
| 魔法方法 | 说明 |
|---|---|
| __get__(self,instance,owner) | 用于访问属性,它返回属性的值 |
| __set__(self,instance,value) | 将在属性分配操作中调用,不返回任何内容 |
| __delete__(self,instance) | 控制删除操作,不返回任何内容 |
描述符的触发:
当我们进行属性访问时便会触发描述符(如果这个属性具有描述符定义的时候),当我们对对象obj的属性d进行访问时候,obj.d,描述符的触发过程大致:先在对象obj的字典中寻找d,如果d是个含有__get__()的对象,则直接调用d.__get__(obj)。
官方文档中对具体的触发细节进行了更详细的描述,具体的触发又分为我们访问的是类属性还是实例属性:
- 如果是对实例属性进行访问,则属性访问转译的关键就在于基类object的__getattribute__方法,我们知道这个内置方法是在进行属性访问的时候无条件调用的,因此这个方法中将obj.d转译成了type(obj).__dict__['d'].__get__(obj, type(obj))。
- 如果是对类对象的属性进行访问,则属性的访问转译关键在于元类type的__getattribute__方法,它将cls.d转译成cls.__dict__['d'].__get__(None, cls),这里__get__()的instance没有也就是相应的None了。
class Mydecorator:
def __get__(self, instance, owner):
print('getting...',self,instance,cls)
def __set__(self, instance, value):
print('setting...',self,instance,value)
def __delete__(self, instance):
print('deleting...',self,instance)
class Test:
x = Mydecorator() #x是定义了描述符的属性
test = Test()
#print(Test) #
#print(test) #<__main__.Test object at 0x1021023c8>
test.x #访问x,触发x.__get__
test.x = 2 #赋值x,触发x.__set__
输出:
getting... <__main__.Mydecorator object at 0x102102160> <__main__.Test object at 0x1021023c8>
setting... <__main__.Mydecorator object at 0x102102160> <__main__.Test object at 0x1021023c8> 2
deleting... <__main__.Mydecorator object at 0x102102160> <__main__.Test object at 0x1021023c8>
自定义descriptor:
class MyProperty:
def __init__(self,fget=None,fset=None,fdel=None):
self.fget = fget
self.fset = fset
self.fdel = fdel
def __get__(self, instance, cls):
return self.fget(instance)
def __set__(self, instance, value):
return self.fset(instance,value)
def __delete__(self, instance):
return self.fdel(instance)
class C:
def __init__(self):
self._x = None
def getX(self):
return self._x
def setX(self,value):
self._x = value
def delX(self):
del self._x
x = MyProperty(getX,setX,delX)
c = C()
# c.x = 'x-man'
print(c.x)
2.通过描述符可以使实例之间共享一个变量
In [13]: class Height(object):
...: def __init__(self,height):
...: self.height = height
...: def __get__(self,instance,cls):
...: return self.height
...: def __set__(self,instance,value):
...: self.height = value
...:
In [14]: class Student(object):
...: height = Height(1.78)
...:
In [16]: a = Student()
In [18]: a.height
Out[18]: 1.78
In [19]: a.height = 1.9
In [20]: a.height
Out[20]: 1.9
In [21]: b = Student()
In [22]: b.height
Out[22]: 1.9
In [23]: b.height = 2.0
In [24]: b.height
Out[24]: 2.0
In [25]: a.height
Out[25]: 2.0
In [27]: a.height is b.height
Out[27]: True
我们创建了两个学生实例,但是身高属性却是同一个对象,这是因为描述符是类属性,因此每个实例中进行访问的时候都是访问的类属性的引用。
3.@property
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改:
s = Student()
s.score = 9999
这显然不合逻辑。为了限制score的范围,可以通过一个set_score()方法来设置成绩,再通过一个get_score()来获取成绩,这样,在set_score()方法里,就可以检查参数:
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
现在,对任意的Student实例进行操作,就不能随心所欲地设置score了:
>>> s = Student()
>>> s.set_score(60) # ok!
>>> s.get_score()
60
>>> s.set_score(9999)
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
但是,上面的调用方法又略显复杂,没有直接用属性这么直接简单。
有没有既能检查参数,又可以用类似属性这样简单的方式来访问类的变量呢?对于追求完美的Python程序员来说,这是必须要做到的!
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的:
class Student(object):
@property
def score(self): #函数score变成了属性,当访问score时触发这个函数
return self._score
@score.setter #setter是固定写法
def score(self, value): #当赋值时,触发这个函数
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
>>> s = Student()
>>> s.score = 60 # OK,实际转化为s.set_score(60)
>>> s.score # OK,实际转化为s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
注意到这个神奇的@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的。
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2014 - self._birth
上面的birth是可读写属性,而age就是一个只读属性,因为age可以根据birth和当前时间计算出来。
小结
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。