第十一章 博客文章
本章将实现Flasky博客的核心功能,允许用户读取和撰写文章。你将学到一些关于模板重用、长项目列表的分页和富文本等新知识。
提交和显示文章
我们需要先准备好一个新的数据库模型来支持文章发布。这个模型设计如例子11-1所示:
Example 11-1. app/models.py: Post model
class Post(db.Model):
__tablename__ = 'posts'
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.Text)
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)
author_id = db.Column(db.Integer, db.ForeignKey('users.id'))
class User(UserMixin, db.Model):
# ...
posts = db.relationship('Post', backref='author', lazy='dynamic')
文章由body,timestamp和一用户对多文章的关系组成。body字段类型为db.Text——没有长度限制。
撰写文章的表单将被显示在程序的主页面上。这个表单也很简单,仅包含了一个输入文字的文本块和一个提交按钮。表单的定义如例子11-2所示:
Example 11-2. app/main/forms.py: Blog post form
class PostForm(Form):
body = TextAreaField("What's on your mind?", validators=[Required()])
submit = SubmitField('Submit')
视图函数index()处理这个表单请求并将旧的文章列表传递给模板,如例子11-3:
Example 11-3. app/main/views.py: Home page route with a blog post
@main.route('/', methods=['GET', 'POST'])
def index():
form = PostForm()
if current_user.can(Permission.WRITE_ARTICLES) and form.validate_on_submit():
post = Post(body=form.body.data, author=current_user._get_current_object())
db.session.add(post)
return redirect(url_for('.index'))
posts = Post.query.order_by(Post.timestamp.desc()).all()
return render_template('index.html', form=form, posts=posts)
视图函数把表单和完整的文章列表(list格式)传递给模板。文章列表根据文章的发表时间倒序排列。表单使用传统方式进行处理:接收到提交请求就会创建一个新的Post实例。在允许创建新post前会检查当前用户的撰写文章的权限。
注意,新的文章对象的author属性被设置为current_user._get_current_object()。来自于flask-login的current_user变量就像所有的上下文变量一样,作为一个线程本地代理对象存在。这个对象表现地像一个用户对象,实际上也真的是一个内部包含了一个真实用户对象的包装器。数据库需要一个真实用户对象,通过调用_get_current_object()来取得。(译注:这一段不理解)
表单在index.html模板的欢迎信息下方显示,接下来是文章列表。文章列表把数据库里所有的文章按照从新到旧的顺序依次排列,创建一个文章时间线。这部分模板变化请看例子11-4:
Example 11-4. app/templates/index.html: Home page template with blog posts
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
...
{% if current_user.can(Permission.WRITE_ARTICLES) %}
{{ wtf.quick_form(form) }}
{% endif %}
{% for post in posts %}
-
 }}) {{ moment(post.timestamp).fromNow() }}
{{ post.body }}
{{ moment(post.timestamp).fromNow() }}
{{ post.body }}
{% endfor %}
...
注意,我们调用User.can()方法用来对不具备WRITE_ARTICLES权限的用户隐藏表单。文章列表使用了css样式表美化,显示为HTML无序列表格式。作者的小头像显示在左侧,头像及作者名字都是连接到用户档案页面的链接。我们使用的CSS样式表保存在程序static文件夹下。你可以在GIthub仓库中找到它。
译注:css文件也需要做相应修改,可自行斟酌。
图11-1是浏览器中显示的带有表单和文章列表的首页。
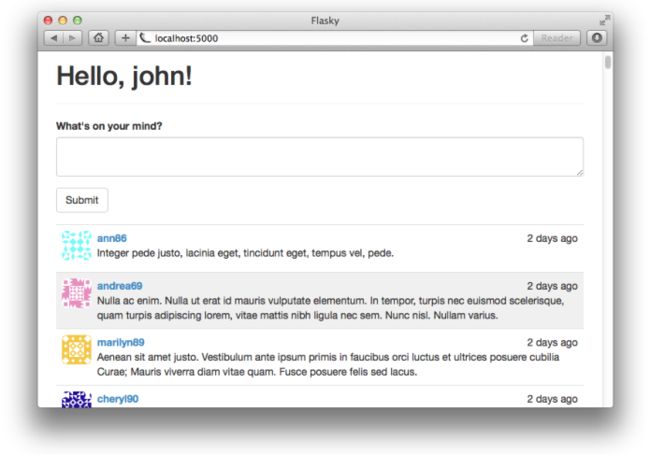
档案页面的文章
我们来改进一下用户档案页面,让它显示该用户的所有文章列表。例子11-5显示了对该视图函数的更改来获取文章列表:
Example 11-5. app/main/views.py: Profile page route with blog posts
@main.route('/user/')
def user(username):
user = User.query.filter_by(username=username).first()
if user is None:
abort(404)
posts = user.posts.order_by(Post.timestamp.desc()).all()
return render_template('user.html', user=user, posts=posts)
某用户的文章列表可以依赖User.posts关系来获取,这一关系是一个查询对象,我们可以使用类似于order_by()的过滤器器来进行筛选。
user.html模板也需要
Example 11-6. app/templates/user.html: Profile page template with blog posts
...
Posts by {{ user.username }}
{% include '_posts.html' %}
...
为了完成这一重构,
译注:在template文件夹下,新建_posts.html。输入如下代码保存:
{% for post in posts %}
-
{{ moment(post.timestamp).fromNow() }}
{{ post.body }}
{% endfor %}
准备长文章列表
随着站点和文章数量的不断增长,程序响应速度会变慢,要想在档案页面和首页显示所有的文章列表就显得不切实际了。大页面需要花费更多的时间生成、下载然后在浏览器中渲染显示,所以随着页面变大用户体验质量就会下降。解决办法就是对数据分页(paginate)并按块(chunks)显示。
创建模拟文章数据
为了显示多页文章,我们需要先有一个大量数据的测试数据库。手工添加新数据即耗时又乏味,我们需要一个自动方案。有好几个Python包可以用来生成模拟数据信息,比较完整的一个就是ForgeryPy,可以用pip安装:
(venv) $ pip install forgerypy
严格说起来,ForgeryPy并不是一个程序依赖包,因为它只是在开发过程中才用到。为了将开发依赖和生产依赖区分开,我们把requirements.txt替换为requirements文件夹,分别存储不同环境下的依赖。这个文件夹里用dev.txt和prod.txt分别存储开发环境依赖和生产环境依赖。由于二者会有大部分依赖都一样,所以把共同的部分独立成common.txt,而dev.txt和prod.txt分别使用-r 前缀包含common.txt,例子11-7展示了dev.txt:
Example 11-7. requirements/dev.txt: Development requirements file
-r common.txt
ForgeryPy==0.1
例子11-8,通过分别给user和post添加类方法后,user和Post模型就可以生成模拟数据了:
Example 11-8. app/models.py: Generate fake users and blog posts
class User(UserMixin, db.Model):
# ...
@staticmethod
def generate_fake(count=100):
from sqlalchemy.exc import IntegrityError
from random import seed
import forgery_py
seed()
for i in range(count):
u = User(email=forgery_py.internet.email_address(),username=forgery_py.internet.user_name(True),password=forgery_py.lorem_ipsum.word(),confirmed=True,name=forgery_py.name.full_name(),
location=forgery_py.address.city(),about_me=forgery_py.lorem_ipsum.sentence(),member_since=forgery_py.date.date(True))
db.session.add(u)
try:
db.session.commit()
except IntegrityError:
db.session.rollback()
class Post(db.Model):
# ...
@staticmethod
def generate_fake(count=100):
from random import seed, randint
import forgery_py
seed()
user_count = User.query.count()
for i in range(count):
u = User.query.offset(randint(0, user_count - 1)).first()
p = Post(body=forgery_py.lorem_ipsum.sentences(randint(1, 3)),timestamp=forgery_py.date.date(True),author=u)
db.session.add(p)
db.session.commit()
我们使用ForgeryPy的随机信息生成器生成了很多模拟对象属性,这一生成器可以生成逼真的names,email,setences和更多属性。
email地址和用户名必须唯一,但由于ForgeryPy完全使用随机生成,所以有一定的几率会出现重复。一旦出现这种意外,数据库会话提交时就会抛出一个IntegrityError例外错误。这个错误将导致会话回滚,因此这一产生重复的操作就不会将用户写入数据库,所以模拟用户数就可能会比我们指定的数量要少。
随机生成文章时需要为每篇文章指定一个随机的用户。此处使用了offset()查询过滤器。这个过滤器只保留指定数量的结果,通过设置一个随机偏移值然后再调用first(),我们就可以每次取得一个随机用户。这个新方法使得我们从shell中生成大量的模拟用户和文章变得非常轻松:
(venv) $ python manage.py shell
>>> User.generate_fake(100)
>>> Post.generate_fake(100)
译注:要运行shell命令,你需要补充相关引用导入——只要shell中报错未定义xxx,你就需要检查了。这里,在manage.py中修改如下:
from app.models import User,Role,Permission,Post
#...
def make_shell_context():
return dict(app=app,db=db,User=User,Role=Role,Permission=Permission,Post=Post)
在页面中显示数据
例子11-9展示了首页路由为了显示分页数据所做的更改:
Example 11-9. app/main/views.py: Paginate the blog post list
@main.route('/', methods=['GET', 'POST'])
def index():
# ...
page = request.args.get('page', 1, type=int)
pagination = Post.query.order_by(Post.timestamp.desc()).paginate(page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],error_out=False)
posts = pagination.items
return render_template('index.html', form=form, posts=posts,pagination=pagination)
显示的页码来自于请求查询字符串,可以从request.args中获取。如果没有有效的页码,就会使用默认值1(第一页)。type=int参数确保了一旦参数不能转换成整数,则返回一个默认值。
为了载入一页记录,应该用Flask-SQLAlchemy的paginate()替换all()方法。paginate()方法把当前页码作为第一个且必要的一个参数。可选参数per_page用来确定每页的记录数,如果没有指定,则默认每页显示20条。另外一个可选参数是error_out默认设置为True,它用来触发404错误,如果请求的页码超过有效范围就会触发该错误。如果error_out被设置为False,超出范围的页码请求将返回一个空列表。为了配置每页显示数,我们在程序配置中单独指定了FLASK_POSTS_PER_PAGE,可以从这里读取它。
经过这些更改,首页上的文章列表将以一个指定数量显示。如果希望看第二页,可以在浏览器地址栏URL中添加?page=2回车。
添加一个Pagination插件
paginate()的返回值是一个Paginatin类的对象。这个对象包含了一些很有用的特性,可以用来在模板中生成链接,所以它应该以参数的形式传递给模板。pagination对象的特性列表如表11-1所示:
属性 说明
items 当前页面上的记录
query 用来分页的源查询
page 当前页码
prev_num 上一页页码
next_num 下一页页码
has_next 如果有下一页则为True
has_prev 如果有上一页则为True
pages 查询得到的所有页数
per_page 每页记录数
total 查询结果总数
pagination()的方法列表如下,表11-2:
方法 说明
iter_pages(left_edge=2, 一个迭代器,用来返回分页插件中要显示的页码序列
left_current=2, 这个列表中的参数分别如下:left_edge,左侧2页码数,left_current 当前页码向左偏移两页,
right_current=5, right_current 当前页码向右偏移五页right_edge 右侧边界2页的页码
right_edge=2) 例如:对于第50页(当前页),共100页,这个迭代器按照左侧的默认配置将返回
如下页: 1, 2,None , 48, 49, 50, 51, 52, 53, 54, 55, None ,
99, 100。 None值界定了页码序列的前后缺口(在模板中就显示为...)。
prev() 上一页的分页对象.
next() 下一页的分页对象
武装上这个强大对象和bootstrap样式表类,就可以轻松创建一个分页导航。例子11-10显示了可复用的Jinja2宏格式的实现:
Example 11-10. app/templates/_macros.html: Pagination template macro
{% macro pagination_widget(pagination, endpoint) %}
{% endmacro %}
这个宏创建了一个Bootstrap无序列表风格的分页元素。其内部的定义链接如下:
- "Previous Page"上一页,如果当前页是第一页的话这个链接就会被设置为CSS 的disable 类(
译注:呈现禁用状态)。 - 链接到分页对象的iter_pages()迭代器返回来的所有页面。这些页面作为明确页码名称的链接,通过传递给url_for()明确的页码生成。当前页使用activecss类来高亮显示,而页码序列的"缺口"(Gaps in the sequence of pages)则用省略号显示。
- "Next page"下一页链接,如果当前是最后一页则这个链接不可用(disable css类)
Jinja2宏总是接收键值参数,不带有必须包含**kwargs的参数列表(?译注:不太理解这一句:Jinja2 macros always receive keyword arguments without having to include **kwargs in the argument list)。Pagination宏把所有接收到的键值参数都传递给url_for()来生成分页导航链接。这个方法可以被用在路由上,如档案页面的动态部分。
pagination_widget宏可以被添加在index.html和user.html中,位于被引用的_post.html模板下方。例子11-11展示了首页中它的用法:
Example 11-11. app/templates/index.html: Pagination footer for blog post lists
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% import "_macros.html" as macros %}
...
{% include '_posts.html' %}
{{ macros.pagination_widget(pagination, '.index') }}
{% endif %}
图11-2就是分页链接在页面中的样子:

使用Markdown和Flask-PageDown的富文本文章
对于短信息和状态更新,纯文本就足够了,但对于希望撰写长篇文字的用户来说就缺乏格式支持非常不便。本节中,我们将升级文本域,来支持Markdown语法,并且提供文章的富文本预览。
为了实现这一要求,我们需要几个新的包:
- PageDown,客户端Markdown-HTML转换的js实现
- Flask-PageDown,PageDown与Flask-WTF集成后的封装
- Markdown ,服务器端的Markdown-HTML转换的Python实现
- Bleach, HTML清除器的Python实现
安装命令(同时安装多个扩展)如下:
(venv) $ pip install flask-pagedown markdown bleach
使用Flask-pagedown
Flask-pagedown扩展定义了一个pagedownField字段类,其外观与WTForms的TextAreField一样。在使用这个字段之前,我们需要先初始化这个扩展,如例子11-12:
Example 11-12. app/__init__.py: Flask-PageDown initialization
from flask.ext.pagedown import PageDown
# ...
pagedown = PageDown()
# ...
def create_app(config_name):
# ...
pagedown.init_app(app)
# ...
为了把首页中的文本域(textarea)转换成Markdown 富文本编辑器,我们需要先把PostForm中的body字段转成pagedownField,如例子11-13:
Example 11-13. app/main/forms.py: Markdown-enabled post form
from flask.ext.pagedown.fields import PageDownField
class PostForm(Form):
body = PageDownField("What's on your mind?", validators=[Required()])
submit = SubmitField('Submit')
在pageDown库的帮助下生成Markdown预览,这也需要添加到模板中。Flask-pagedown简化了这一任务,它通过CDN提供了一个包含必要文件的宏模板,如例子11-14所示:
Example 11-14. app/index.html: Flask-PageDown template declaration
{% block scripts %}
{{ super() }}
{{ pagedown.include_pagedown() }}
{% endblock %}
现在,我们实现了在文本域中录入Markdown格式的文字,立即就可以在预览区看到HTML格式的显示。图11-3显示了带有富文本的博客提交表单:
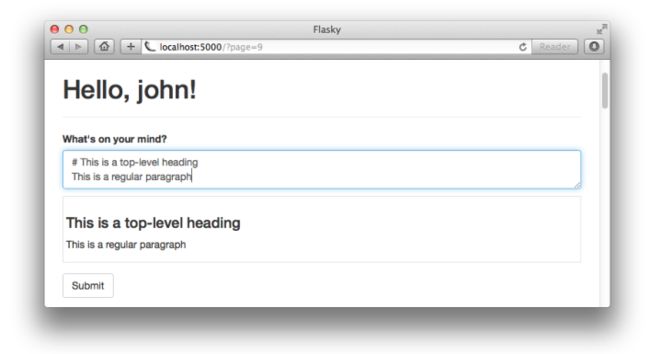
在服务器端处理富文本
客户端提交表单时,将通过POST请求发送Markdown的源文本——页面上显示的HTML预览是被忽略的。通过表单传递HTML预览具有很大的安全风险,因为通过构造不符合markdown源文本的HTML代码片段,攻击者能很容易地向服务器非法提交内容。为了防止风险,我们只提交markdown源文本,在服务器端使用Markdown包(python编写的markdown-html转换器)转成html,再使用Bleach清理这一html结构,确保其中只使用了我们允许的html标记。
Markdown转HTML这一动作也可以在_post.html模板中完成,但非常没有效率,因为每次显示页面时都需要对文章进行转换。为了解决这一问题,我们只在创建文章时执行一次转换——把文章的HTML代码格式缓存在一个Post模型的新字段里,这样模板可以直接访问。Markdown原格式文章被保存在数据库里,以备修改之用。例子11-15显示了models.py中Post模型的变化:
Example 11-15. app/models.py: Markdown text handling in the Post model#原文误写models/post.py
from markdown import markdown
import bleach
class Post(db.Model):
# ...
body_html = db.Column(db.Text)
# ...
@staticmethod
def on_changed_body(target, value, oldvalue, initiator):
allowed_tags = ['a', 'abbr', 'acronym', 'b', 'blockquote', 'code','em', 'i', 'li', 'ol', 'pre', 'strong', 'ul','h1', 'h2', 'h3', 'p']
target.body_html = bleach.linkify(bleach.clean(markdown(value, output_format='html'),tags=allowed_tags, strip=True))
db.event.listen(Post.body, 'set', Post.on_changed_body)
on_change_body函数被注册为监听SQLAlchemy对body字段的"set"事件,也就是说,一旦这个类任意实例中的body字段被设置为新值,这个函数都会被自动调用。这个函数渲染html格式的body并把它存储在body_html中,有效的自动完成从markdown到html的格式转换。
实际上转换有三个步骤。首先,markdown()函数完成初步转换。然后,结果传递给clean(),只允许指定的html标记。clean()函数将清除所有不在白名单中的标记。最终转换由Bleach提供的linkify()函数完成,它会把纯文本格式的URL转换成正确的连接。最后一步是必要的,因为markdown本身没有提供自动连接转换。PageDown作为一个扩展进行了支持,所以linkify()必须在服务器端进行匹配。
最后一个改变是在模板中用post.body_html替换了post.body,如例子11-16所示:
Example 11-16. app/templates/_posts.html: Use the HTML version of the post bodies in the template
...
{% if post.body_html %}
{{ post.body_html | safe }}
{% else %}
{{ post.body }}
{% endif %}
...
|safe后缀用来在渲染显示html内容是告诉Jinja2不要对这一html元素进行转义——Jinja2默认会对所有模板变量进行转义以确保安全。由于markdown转html是在服务器端完成的,所以可以安全的显示。
译注:效果上一条是markdown格式,下一条未写任何格式(markdown将仅添加一个
标志)。
 Paste_Image.png
Paste_Image.png
博客文章的永久性连接
用户可能希望在社交网络上和朋友分享某篇文章,因此,我们需要为每一篇文章分配一个可以引用的唯一URL。例子11-17展示了支持永久链接的路由和视图函数代码:
Example 11-17. app/main/views.py: Permanent links to posts
@main.route('/post/')
def post(id):
post = Post.query.get_or_404(id)
return render_template('post.html', posts=[post])
这个URL是由文章的主键id(向数据库插入文章时自动生成,唯一)构成的。
提醒:对于某些类型的程序,使用一个可读的URL而不是数字id来创建永久链接会更好一些。作为数字id方案的另外方案,(可读的URL)实际上就是给每一篇文章分配一个slug(块?)——指向这篇文章的唯一字符串。
注意,post.html模板接收并用来显示的是一个列表(list),它实际上只包含指定的这篇文章。这是因为,我们在post.html中引用的_post.html模板要用到的变量是一个文章列表(如同index.html和user.html中一样,它们都是传递了文章列表给_post.html)。
我们把永久链接添加在_post.html通用模板中每一篇文章的底部,如例子11-18所示:
Example 11-18. app/templates/_posts.html: Permanent links to posts
{% for post in posts %}
-
...
...
{% endfor %}
新的带有永久链接的post.html模板如例子 11-19所示,它包含了上例模板。
Example 11-19. app/templates/post.html: Permanent link template
{% extends "base.html" %}
{% block title %}Flasky - Post{% endblock %}
{% block page_content %}
{% include '_posts.html' %}
{% endblock %}
文章编辑器
关于博客文章的最后一个功能就是创建文章编辑器,允许用户修改自己文章。这个编辑器位于一个独立页面,在页面顶部,显示当前文章的版本,接下来是markdown编辑器——用来修改markdown源文本。这个编辑器基于Flask-PageDown,所以页面底部将会显示一个文章预览。edit_post.html模板如例子11-20所示。
Example 11-20. app/templates/edit_post.html: Edit blog post template
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}Flasky - Edit Post{% endblock %}
{% block page_content %}
Edit Post
{{ wtf.quick_form(form) }}
{% endblock %}
{% block scripts %}
{{ super() }}
{{ pagedown.include_pagedown() }}
{% endblock %}
相关的路由实现如例子11-21所示,
Example 11-21. app/main/views.py: Edit blog post route
@main.route('/edit/', methods=['GET', 'POST'])
@login_required
def edit(id):
post = Post.query.get_or_404(id)
if current_user != post.author and not current_user.can(Permission.ADMINISTER):
abort(403)
form = PostForm()
if form.validate_on_submit():
post.body = form.body.data
db.session.add(post)
flash('The post has been updated.')
return redirect(url_for('.post', id=post.id))
form.body.data = post.body
return render_template('edit_post.html', form=form)
视图函数只允许作者修改自己的文章,管理员除外——他可以修改所有人的文章。如果用户试图修改别人的文章,视图函数将返回一个403错误代码的响应。这里使用的PostForm表单类跟首页中引用的那个是一样的。
最后,我们给每篇文章底下在永久链接后面再添加一个编辑器链接,这个功能就完工了。请看例子11-22:
Example 11-22. app/templates/_posts.html: Edit blog post links
{% for post in posts %}
-
...
...
{% endfor %}
这里增加了一个到当前用户所编写的任意文章的"Edit"链接。对于管理员,这个链接在所有文章上都会显示,并且具有特殊的风格,从视觉上提醒这是一个管理员功能。图11-4展示了edit和永久链接在浏览器里的样子:

Over,下章见。
<<第十章 用户资料 第十二章 关注者>>