shuffle及Spark shuffle历史简介
shuffle,中文意译“洗牌”,是所有采用map-reduce思想的大数据计算框架的必经阶段,也是最重要的阶段。它处在map与reduce之间,又可以分为两个子阶段:
- shuffle write:map任务写上游计算产生的中间数据;
- shuffle read:reduce任务读map任务产生的中间数据,用于下游计算。
下图示出在Hadoop MapReduce框架中,shuffle发生的时机和细节。

Spark的shuffle机制虽然也采用MR思想,但Spark是基于RDD进行计算的,实现方式与Hadoop有差异,并且中途经历了比较大的变动,简述如下:
- 在久远的Spark 0.8版本及之前,只有最简单的hash shuffle,后来引入了consolidation机制;
- 1.1版本新加入sort shuffle机制,但默认仍然使用hash shuffle;
- 1.2版本开始默认使用sort shuffle;
- 1.4版本引入了tungsten-sort shuffle,是基于普通sort shuffle创新的序列化shuffle方式;
- 1.6版本将tungsten-sort shuffle与sort shuffle合并,由Spark自动决定采用哪一种方式;
- 2.0版本之后,hash shuffle机制被删除,只保留sort shuffle机制至今。
下面的代码分析致力于对Spark shuffle先有一个大致的了解。
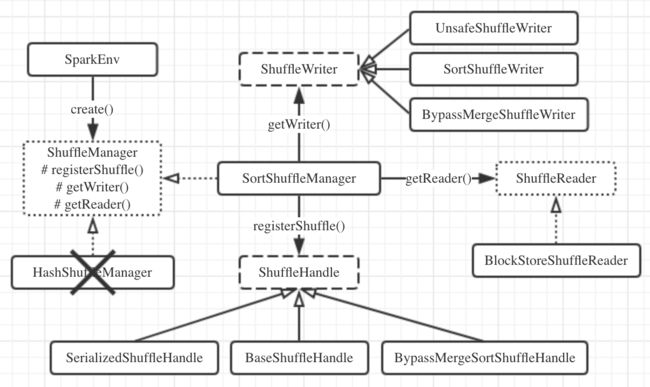
shuffle机制的最顶层:ShuffleManager特征
鉴于shuffle的重要性,shuffle机制的初始化在Spark执行环境初始化时就会进行。查看SparkEnv.create()方法:
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
// 通过反射创建ShuffleManager
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
上面的代码可以印证hash shuffle已经成为历史了。另外,还可以通过spark.shuffle.manager参数手动指定shuffle机制,不过意义不大。
o.a.s.shuffle.ShuffleManager是一个Scala特征(相当于Java接口的增强版)。其中定义的核心方法有3个:
/**
* Register a shuffle with the manager and obtain a handle for it to pass to tasks.
*/
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
/** Get a writer for a given partition. Called on executors by map tasks. */
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V]
/**
* Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive).
* Called on executors by reduce tasks.
*/
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
- registerShuffle()方法用于注册一种shuffle机制,并返回对应的ShuffleHandle(类似于句柄),handle内会存储shuffle依赖信息。根据该handle可以进一步确定采用的ShuffleWriter/ShuffleReader的种类。
- getWriter()方法用于获取ShuffleWriter。它是executor执行map任务时调用的。
- getReader()方法用于获取ShuffleReader。它是executor执行reduce任务时调用的。
sort shuffle机制概况:SortShuffleManager类
在hash shuffle取消后,o.a.s.shuffle.sort.SortShuffleManager就是ShuffleManager目前唯一的实现类。来看它对上面提到的三个方法的具体实现。
registerShuffle()方法
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
可以看出,根据条件的不同,会返回3种不同的handle,对应3种shuffle机制。从上到下来分析一下:
- 检查是否符合SortShuffleWriter.shouldBypassMergeSort()方法的条件:
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
false
} else {
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
也就是说,如果同时满足以下两个条件:
- 该shuffle依赖中没有map端聚合操作(如groupByKey()算子)
- 分区数不大于参数
spark.shuffle.sort.bypassMergeThreshold规定的值(默认200)
那么会返回BypassMergeSortShuffleHandle,启用bypass merge-sort shuffle机制。
- 如果不启用上述bypass机制,那么继续检查是否符合canUseSerializedShuffle()方法的条件:
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
if (!dependency.serializer.supportsRelocationOfSerializedObjects) {
log.debug(/*...*/)
false
} else if (dependency.aggregator.isDefined) {
log.debug(/*...*/)
false
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
log.debug(/*...*/)
false
} else {
log.debug(/*...*/)
true
}
}
}
也就是说,如果同时满足以下三个条件:
- 使用的序列化器支持序列化对象的重定位(如KryoSerializer)
- shuffle依赖中完全没有聚合操作
- 分区数不大于常量
MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE的值(最大分区ID号+1,即2^24=16777216)
那么会返回SerializedShuffleHandle,启用序列化sort shuffle机制(也就是tungsten-sort)。
- 如果既不用bypass也不用tungsten-sort,那么就返回默认的BaseShuffleHandle,采用基本的sort shuffle机制。
getWriter()方法
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
根据不同的handle,获取不同的ShuffleWriter。对于tungsten-sort会使用UnsafeShuffleWriter,bypass会使用BypassMergeSortShuffleWriter,普通的sort则使用SortShuffleWriter。它们都继承自ShuffleWriter抽象类,并且都实现了write()方法。
getReader()方法
override def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C] = {
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context)
}
ShuffleReader比较简单,只有一种,即BlockStoreShuffleReader。它继承自ShuffleReader特征,并实现了read()方法。
总结