
内容来源:2018年1月25日,ServiceComb 开发工程师崔毅华在“ServiceComb在线直播”进行《Service Center源码揭秘》演讲分享。IT 大咖说(WeChat_ID:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:2332 | 4分钟阅读
观看嘉宾完整演讲视频及PPT,请点击:http://t.cn/Eyfdkex
摘要
揭秘Service Center的架构和设计细节,在线阅读分享Service Center代码。
什么是服务注册中心?
服务注册中心具有服务注册和服务发现能力的可靠的分布式服务。
为什么需要服务注册中心?
是单体架构向微服务服务化演进的需要。
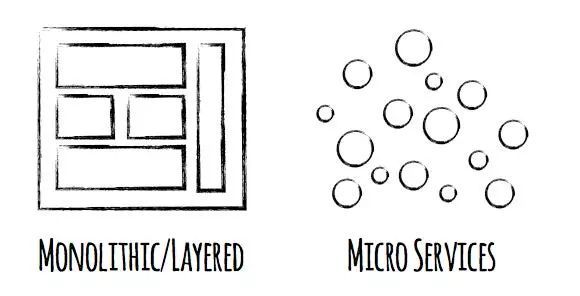
以前的老式单体结构非常臃肿,部署在一个集群上,不够灵活。在演进的过程中,架构师分散地进行了拆分,慢慢演进成微服务的架构。
单体架构到微服务架构的演进中的确带来了很多好处,比如架构业务实现了解耦,单一职责,而且每一个服务可以独立运行。在开发运维上成本也更低,迭代上线周期更短,解放了程序员的生产力。
但同时也引入了新的问题。比如业务间的通信发生了变化,需要远程通信调用。要解决通信上的问题,除了定制一个业务间通信的标准协议之外,还需要一个具有服务注册和服务发现能力的组件,能够保存业务进程的一些实例信息,还能提供查询实例IP地址的标准接口给各个业务去使用。
服务注册中心
服务端发现
DNS可以作为服务端发现的组件,各个服务会把自己的服务名当作域名,把自己的实例IP注册到DNS当中。DNS会根据每一次请求返回一个IP给服务消费端。
随着业务规模变大,容器化的出现又使得微服务架构重新出现。在这种情况下,DNS的问题也慢慢突显出来。首先,DNS的缓存刷新不及时。其次,为了减轻DNS的压力,一般服务端在开发过程中就会把域名解析的IP缓存到本地,基本上没有什么问题的话不会访问DNS。DNS本身又缺少一个主动通知的机制,无法通知消费方刷新本地缓存,时间一长就会出现越来越多的实例不可用、IP找不到或者IP无法访问等情况,整个架构都会非常不稳定。另外还会有一个中心化的问题。DNS一旦出现故障,集中式的服务发现就会影响整个系统。
DNS这个方案虽然可以临时解决一些问题,但是它最终还是不适合做服务注册中心的。
客户端发现
服务消费端只需要关心和查询订阅自己依赖的一些业务服务实例表或IP列表,自己在本地根据喜欢的路由策略进行过滤和请求。操作简单数量也很少,所以大部分开源类似可以做服务注册中心组件的都偏向于做客户端发现。
适合做服务注册中心的开源组件有Service Center,eureka,etcd,zookeeper和consul。
为什么实现自己的服务注册中心?
应该提供标准化的接口,具有负载均衡和服务订阅的能力。运行时的依赖一定要够轻,可靠性也是非常重要的。
从服务注册中心到服务管理中心
我们定义了微服务的静态元数据结构,Service Center也提供了非常方便的接口去检索这些信息。
为了很好地呈现微服务之间的调用关系,也需要把依赖关系拉进来作为管理。
根据依赖关系的管理来可以进行实例变化的推送。
支持多租隔离。
Service Center从设计上已经考虑了各种故障点并提供了对应的保护机制,也就是高可用保障的能力。

根据上面的架构图可见,微服务的重要发现会统一通过Service Center进行处理。
元数据
1、应用App,便于微服务可在多个应用间重用
2、微服务名称,App内唯一
3、微服务描述信息,让使用者可以快速了解到业务范畴等
4、微服务访问契约内容,API能力的描述文件
5、微服务扩展属性,添加具体业务扩展属性
6、微服务黑白名单,支持Provider侧设置路由策略
7、微服务标签,支持按标签检索
高可用性保障
我们引用了互联网分布式系统设计的准则BASE来判断组件是否为高可靠的。BASE就是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)。
CAP理论
Consistency(一致性),在分布式系统的各点同时保持数据的一致。
Availability(可用性),每个请求都能接受到一个响应,无论响应成功或失败。
Partition tolerance(分区容错性),当出现网络分区故障时系统的容错能力
从微服务到服务管理中心
实例缓存机制
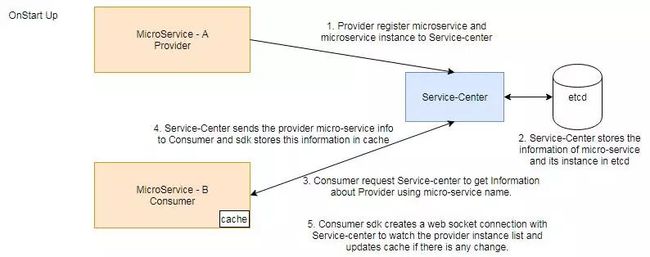
服务管理中心提供了实例缓存机制。基于ServiceComb的SDK开发的微服务在第一次消费provider的时候会进行一次实例发现的操作,在内部向Service Center拉取provider存活的实例集合,并保存到内存缓存中。消费请求都会跟着这个缓存集合不停地用自定义的路由策略去选择一个合适的进行请求。
这样做的好处就是已经运行的SDK进程始终在内部保存了一份实例缓存,在出现服务与Service Center网络分区的情况下,虽然无法实时感知实例的刷新,但是可以在重新连上Service Center之后触发一次实例刷新,保证这个实例最终还是有效的。
在这个过程中,SDK上承载的一些业务是始终可用的,没有中断。
心跳保活机制
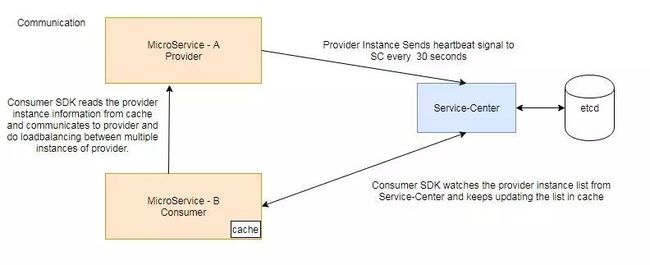
SDK通过进程上报实例心跳的方式对它的实例进行保活。每个provider和Service Center之间的心跳在无法保持的时候,实例就会按照设置好的时间自动老化。
当Service Center感知到这个实例下线了,就会推送给各个监听在ServiceComb上的consumer去刷新本地缓存,实现了微服务动态发现的能力
从微服务管理中心到etcd
异步缓存机制
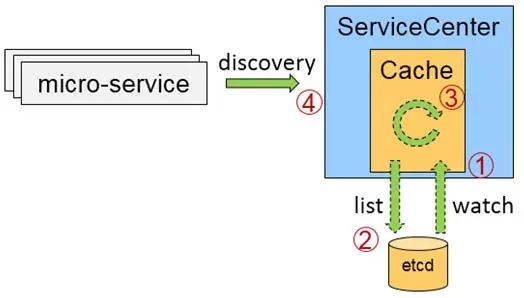
基于Service Center内部本身是不存数据的,一旦etcd出现网络故障的时候,就会导致Service Center不可用。
所以Service Center引入了异步缓存机制,在启动之初Service Center会与etcd建立一个长连接,也就是watch。每次watch的时候为了防止建立watch时间窗发生变化,做了一层保护,在watch之前做了全量的查询。
在运行过程中查询所得到的资源变化会缓存到Service Center本地,然后进行异步的循环。
异步心跳机制
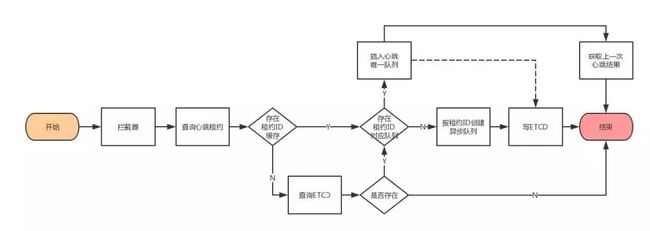
ServiceCenter会根据上报实例的心跳频率和失败次数来推算最终实例下线的时间。异步心跳机制的好处就是它不会因为一些心跳的延时而阻塞,也使得Service Center处理心跳的能力大幅提高。
自我保护机制
前面提到的缓存机制,保证了Service Center在etcd出现网络分区故障时依然保持可读状态,Service Center的自我保护(Self-preservation)机制保证了Provider端与Service Center在出现网络分区故障时依然保持业务可用。
ServiceCenter在一个时间窗内监听到etcd有80%的实例下线事件,会立即启动自我保护机制。即使etcd存储的数据全部丢失,这种极端场景下,SDK与Service Center之间可在不影响业务的前提下,做到数据自动恢复。虽然这个恢复是有损的,但在这种灾难场景下还能保持业务基本可用。
如何参与到ServiceComb社区
官网:http://servicecomb.incubator.apache.org/cn/
通过订阅邮件列表参与讨论:
1、发送任意内容至邮箱:[email protected]
2、收到来自dev-help的邮件后,再回复任意内容来确认订阅邮件列表
在Apache JIRA(https://issues.apache.org/jira/browse/SCB)上提issue或查看最新的开发任务及进展;
加入微信群进行交流;
通过Github(https://github.com/apache?q=servicecomb)发起PR
今天的分享就到这里,谢谢大家!
编者:IT大咖说,转载请标明版权和出处