1.常见调优方法:
spark作业经常会出现跑得很慢或者卡死的情况,需要考虑调优。
1.1 任务提交参数调整
最简单的调优就是调整参数为spark作业加大资源。
以下是我提交任务常用的shell脚本
SPARK_HOME=/opt/spark
${SPARK_HOME}/bin/spark-submit \
--verbose \ #verbose选项来生成更详细的运行信息以做参考,可以知道配置是如何加载的。
--master yarn \ #yarn模式
--deploy-mode cluster \ #cluster模式(不输出日志)
--executor-memory 2G \
--driver-memory 5G \
--executor-cores 10 \ #处理器核数
--conf spark.dynamicAllocation.enabled=true \
#spark.dynamicAllocation.enabled:是否开启动态资源配置,根据工作负载来衡量是否应该增加或减少executor,默认false
--conf spark.dynamicAllocation.minExecutors=1 \
#spark.dynamicAllocation.minExecutors
#动态分配最小executor个数,在启动时就申请好的,默认0
--conf spark.dynamicAllocation.maxExecutors=50 \
#spark.dynamicAllocation.maxExecutors
#动态分配最大executor个数,默认infinity
--conf spark.shuffle.service.enabled=true \
#启用External shuffle Service服务
#External shuffle Service是长期存在于NodeManager进程中的一个辅助服务。
#通过该服务来抓取shuffle数据,减少了Executor的压力,在Executor GC的时候也不会影响其他Executor的任务运行。
#shuffle.service是必须要启动的
--conf spark.rdd.compress=true \
#这个参数决定了RDD Cache的过程中,RDD数据在序列化之后是否进一步进行压缩再储存到内存或磁盘上。
#当然是为了进一步减小Cache数据的尺寸,对于Cache在磁盘上而言,绝对大小大概没有太大关系,主要是考虑Disk的IO带宽。
#而对于Cache在内存中,那主要就是考虑尺寸的影响,是否能够Cache更多的数据,是否能减小Cache数据对GC造成的压力等。
#简单来说:参数为true,在使用persist(StorageLevel.MEMORY_ONLY_SER)的时候,就能够压缩内存中的rdd数据。减少内存消耗,就是在使用的时候会占用CPU的解压时间。
--conf spark.defalut.parallelism=300 \
#该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。设置该参数为num-executors * executor-cores的2~3倍较为合适。
--files /opt/spark/conf/hive-site.xml \
--queue algo \
--class package_name.class_name \
--name class_name_${runid} \
WY-UP-1.0-SNAPSHOT.jar \
$stat_date
以下是在堡垒机上调试spark代码的脚本
#!/bin/sh
echo "-------Geting spark shell!------"
/opt/spark/bin/spark-shell
--master yarn-client
--executor-memory 2g
--driver-memory 3g
--executor-cores 2
--num-executors 20
--conf spark.default.parallelism=50
--conf spark.sql.shuffle.partitions 50
--conf spark.storage.memoryFraction=0.4
--conf spark.shuffle.memoryFraction=0.5
--queue algo
--jars /home/wangyao/myjars/hive-hcatalog-core-0.13.1.jar
和资源相关的部分是参数executor个数,cpu per exector(每个executor可使用的CPU个数),memory per exector(每个executor可使用的内存)
增加executor和增加每个executor的cpu core,也就是是增加了执行的并行能力。
/usr/local/spark/bin/spark-submit \
--class package_name.class_name \
--num-executors 3 \*配置executor的数量 *\
--driver-memory 100m \*配置driver的内存(影响不大)*\
--executor-memory 100m \*配置每个executor的内存大小 *\
--executor-cores 3 \*配置每个executor的cpu core数量 *\
--conf spark.sql.shuffle.partitions 50
--conf spark.default.parallelism 100
WY-UP-1.0-SNAPSHOT.jar \
Spark中RDD对应有partition的概念,每个partition都会对应一个task,task越多,在处理大规模数据的时候,就会越有效率。
但是并不是task越多越好,如果平时测试,或者数据量没有那么大,则没有必要task数量太多。
调整task数量即调整shuffle并行度。
参数可以通过spark_home/conf/spark-default.conf配置文件设置:
--conf spark.sql.shuffle.partitions 50
--conf spark.default.parallelism 100
SparkSQL中有一个比较重要的参数,就是shuffle时候的Task数量,通过spark.sql.shuffle.partitions来调节。
调节的基础是spark集群的处理能力和要处理的数据量,spark的默认值是200。
Task过多,会产生很多的任务启动开销,Task过少,每个Task的处理时间过长,容易straggle。
上边两个参数,第一个是针对sparkSQL(dataframe)的task数量,如果程序是处理rdd则第二个参数生效。
当数据倾斜发生的时候,可以提高shuffle的并行度来缓解数据倾斜。
局限性: 提高shuffle并行度只能让每个task执行更少的不同的key。
无法解决个别key特别大的情况造成的倾斜,如果某些key的大小非常大,即使一个task单独执行它,也会受到数据倾斜的困扰。
增加每个executor的内存量,这样数据可以存在内存内存中,可以减少gc,减少磁盘的擦写。
1.对数据进行持久化操作时,内存越大,可以缓存的内容就越多,写入磁盘的数据就越少。从而减小了磁盘的IO。
2.对于task的执行,会创建很多的临时对,这些对象全部都在内存中,如果内存比较小,可能会导致频繁的GC(minor GC,full GC)。
1.1.1 SparkUI
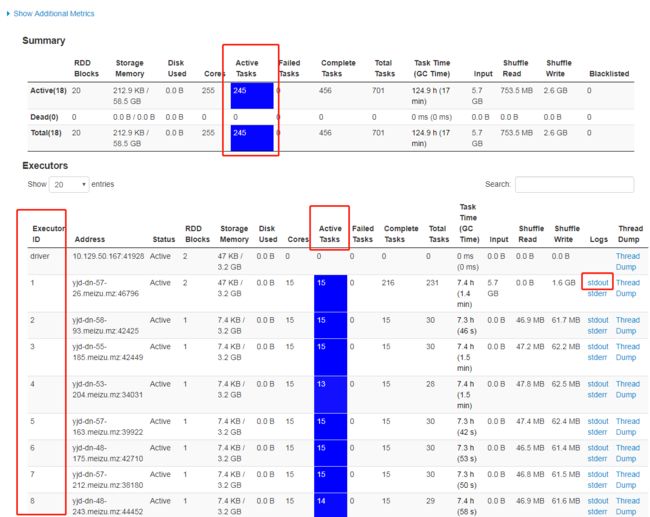
注意这几个指标,ExecutorID可以看出Executor的数量,相关参数:spark.dynamicAllocation.maxExecutors=50
每个executors中的ActiveTasks,可以看出每个executors并行了多少个核,相关参数executor-cores 10。
上面的ActiveTasks,就是统计总的task量。
其他参数可以看名字一一对应。
1.1.2 dataframe和rdd的分区调整
repartition可以给df和rdd分区,rdd可以使用getNumPartitions来查看分区数(默认是200),这些方法在sparkSQL和rdd中都有介绍,这边主要是写写分区数在调优方面的作用。
分区数量直接影响到每个executror中的task数量,所以分区数量要配合上面的参数做调整,有时会碰到任务无法分发的情况,比如查看IP一直是同一个机器在跑,这时候就需要手动分发,手动分发就是重新分区。另外通常hive存表的时候,不喜欢有太多的小文件,所以存表前建议重新分区(10-30个作用)。
1.2 rdd、dataframe持久化
因为spark中每使用一次rdd或dataframe都会重新计算一次,需要复用的rdd或dataframe一定要进行持久化,减少重复运算。
使用cache()或者presist()来进行持久化,cache不能指定持久化级别且底层也是调用presist,所以推荐presist。
有时候需要多次持久化,用完以后也要记得释放内存。
释放持久化:unpersist()。
1.2.1 Spark的持久化级别(节选自http://lxw1234.com/archives/2016/05/661.htm)
可以在persist()中指定storage level参数使用其他的保存类型。
_SER后缀表示,使用序列化的方式来保存RDD数据,此时RDD中的每个partition都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。
_DISK后缀表示,持久化到磁盘中。
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子 操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化 机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有 副本的话,就只能将这些数据从源头处重新计算一遍了。 |
1.2.2.如何选择一种最合适的持久化策略
- 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为 不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能 也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的, 如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化 后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来 的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中 的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为 既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
- 通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次 所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
以上部分(节选自http://lxw1234.com/archives/2016/05/661.htm)下面自己总结一下
1.2.3.简略总结
什么时候需要持久化:
1)某步骤计算特别耗时
2)计算的各种操作特别多
3)在checkpoint之前(checkpoint相当于为了防止长时间操作出问题,而做一个“快照”)
4)shuffle之后
5)shuffle之前
持久化存储方式:
默认缓存方式
MEMORY_ONLY 数据全部缓存在内存中,内存不够大的时候会造成OOM(内存溢出)
MEMORY_ONLY_SER
数据全部以序列化的方式缓存到内存中,内存不足时把dataframe和rdd序列化成一个字节数组(相当于压缩),
这样可以大大降低内存占用,但是序列化反序列化需要消耗一定的性能,速度会降低一些。
MEMORY_AND_DISK_SER
数据以序列化的方式一部分缓存在内存中,一部分持久化到磁盘上。
序列化以后内存仍然不够,那么就存储一部分到磁盘上。
DISK_ONLY 数据全部持久化到磁盘上。
MEMORY_AND_DISK 数据一部分缓存在内存中,一部分持久化到磁盘上。
MEMORY_ONLY_2 数据以双副本的方式缓存在内存中。
MEMORY_AND_DISK_2 数据以双副本的方式一部分缓存到内存中,一部分持久化到磁盘上。
双副本建议在内存资源非常充足的情况下使用。
1.3 spark 广播方式传播数据
1.3.1 摘自厦门大学数据库实验室
广播变量用来把变量在所有节点的内存之间进行共享,这样的方式尤其是在分布式集群中进行并行计算提供了很大的便利,如果数据集很大,需要分布式存储到各个DataNode上,根据“计算向数据靠近”的原则,将每一个DataNode上都要使用的变量(类似全局变量)进行广播,而不是在每一个DataNode上产生一个副本,比如利用sc.broadcast将聚类中心设置为一个只读变量,并广播给每一个集群中的机器进行共享相同的聚类中心。
广播变量(broadcast variables)允许程序开发人员在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。通过这种方式,就可以非常高效地给每个节点(机器)提供一个大的输入数据集的副本。Spark的“动作”操作会跨越多个阶段(stage),对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。这就意味着,显式地创建广播变量只有在下面的情形中是有用的:当跨越多个阶段的那些任务需要相同的数据,或者当以反序列化方式对数据进行缓存是非常重要的。
可以通过调用SparkContext.broadcast(v)来从一个普通变量v中创建一个广播变量。这个广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获得这个广播变量的值,具体代码如下:
scala> val broadcastVar = sparksession.sparkContext.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
这个广播变量被创建以后,那么在集群中的任何函数中,都应该使用广播变量broadcastVar的值,而不是使用v的值,这样就不会把v重复分发到这些节点上。此外,一旦广播变量创建后,普通变量v的值就不能再发生修改,从而确保所有节点都获得这个广播变量的相同的值。
以上摘自:http://dblab.xmu.edu.cn/blog/1313-2/
1.3.2 总结:
分布式计算的时候,每个节点或者多个节点需要相同的少部分数据,而这些数据仅仅存在于某个节点,此时可以使用广播变量,将数据以广播的形式下发到Executor中,然后通过blockManager从Executor中获取数据,并保存到本地,可以极大的减少节点间的网络IO。
如果不使用广播的方式,那么每个task中都需要生成一个副本,1000个task就要生成1000个副本,这样对性能的开销非常大,而用广播的方式是传输到executor中,1000个task可能只需要对应30-50个executor也就只有几十个副本,占用的内存和传输成本就会大大降低。
另外如果数据序列化时间长、结果大,也可以通过广播来解决。
实际场景中,通常使用广播小变量来降低数据传输的性能开销,比如在join的时候,会产生shuffle,可以把两个表中比较小的表广播到集群中,这样就为shuffle操作本身节省下了资源。
注意广播的变量只能是只读变量,如果该变量需要更新则不能广播(各个节点不可能不停的广播更新后的结果)。
刚开始会困惑,为什么持久化了以后还需要广播,实际上二者并没有关系。
1.4 Spark使用Kryo进行序列化操作
1.4.1 Kryo的作用
在以下两种情况需要进行序列化:
1、持久化时候需要进行序列化,StorageLevel.MEMORY_ONLY_SER
2、shuffle的时候
spark默认是使用了ObjectInputStream和ObjectOutputStream对对象进行序列化,默认方法速度慢,产生的结果大。
Spark也可以使用Kryo框架,Kryo序列化的数据在传输速度和占用空间方面相比与Java serialization有显著的提高(一般提高10x)。但是它不支持所有的可序列化数据,并且需要提前注册在程序中用到的class
可以通过设置spark.serializer为org.apache.spark.serializer.KryoSerializer来使用Kryo。
Kryo序列化以后大大降低数据体积,性能可以提升很多,另外如果使用parquet格式的数据,默认会使用Kryo进行序列化。
1.4.2 具体使用
开启Kryo序列化:
在程序中可以用conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")把spark的序列化方式切换为Kyro,这样数据在shuffle和rdd存储过程中都会对数据进行kryo序列化,提高从程序的性能。kryo不是默认序列化方式的原因是它需要用户自己注册要序列化的函数,不过建议所有spark任务都使用Kryo来优化。
如果不想在程序中写入启用Kryo,可以在spark-submit时添加--conf spark.serializer=org.apache.spark.serializer.KryoSerializer选项
class注册
开启Kyro序列化后,对于想要使用的Kryo序列化的类都需要提前注册。spark会自动地注册一些常用的核心scala类型,具体有哪些类型可以参考Twitter chill library。用户自己定义的class可以用conf.registerKryoClasses注册。此外如果用--conf选项可以用spark.kryo.classesToRegister属性来注册class,Class用都后分隔如--conf spark.kryo.classesToRegister=MyClass1,MyClass2
注意不注册空间占用是注册情况下的两倍还多,甚至不如java serializer。
如果选择在程序中设置,选择序列化方式和注册class都是用conf对象设置的,一定要先设置完conf对象后才能创建sparkcontext对象,整个流程如下:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
关于Kryo的一些其他conf属性:
conf属性可以参考Spark Configuration
通常需要设置的两个:
spark.kryo.registrationRequired:默认为false,如果设为true程序运行过程中检查当前被序列化的类型是否被注册如果没有就会抛出异常。这样可以保证整个程序所有序列化类型都被注册防止有类型忘记被注册。
在代码中加上:
conf.set("spark.kryo.registrationRequired","true")
spark.kryoserializer.buffer.max:
配置项spark.kryoserializer.buffer.max,spark1.5.1默认值大小为64m,测试可以根据序列化对象大小确定上界值。--conf spark.kryoserializer.buffer.max=1g或--conf spark.kryoserializer.buffer.max=1024
2.常见错误:
2.1. rdd在map时,报错
java.lang.ClassNotFoundException: scala.Any
问题重现:
import sparkSession.implicits._
var test_df = Seq((1,"1.0,2.0"),(2, "2.0,3.0"),(3,"3.0,4.0")).toDF("imei","feature")
test_df.dtypes
test_df = test_df.rdd.map( v => {
val imei = v(0)
val features = v(1).toString.split(",").map(_.toDouble)
(imei,features)
}).toDF("imei","feature")
test_df.dtypes
解决方法是把所有列强制转化为字符串再做其他处理。
import sparkSession.implicits._
var test_df = Seq((1,"1.0,2.0"),(2, "2.0,3.0"),(3,"3.0,4.0")).toDF("imei","feature")
test_df.dtypes
test_df = test_df.rdd.map( v => {
val imei = v(0).toString
val features = v(1).toString.split(",").map(_.toDouble)
(imei,features)
}).toDF("imei","feature")
test_df.dtypes
2.在dataframe中转换数组中元素的类型
比如需要把Array[Double]转化为Array[Vector](目前只有Double格式才能转化为Vector),再放进模型中训练。
把全为数字的字符串使用split转化为Array[String],再转化为Array[Double]
问题重现:
使用udf把dataframe中类型为Array[string]的一列转化为Array[Double]。
import sparkSession.implicits._
var test_df = Seq((1,Array("1.0")),(2,Array("2.0")),(3,Array("3.0"))).toDF("imei","feature")
test_df.dtypes
val Array_String2Double = udf{arr:Array[String] => arr.map(_.toDouble)}
test_df = test_df.withColumn("feature",Array_String2Double(col("feature")))
test_df.show
报错:
org.apache.spark.SparkException: Failed to execute user defined function($anonfun$1: (array) => array)
Caused by: java.lang.ClassCastException: scala.collection.mutable.WrappedArray$ofRef cannot be cast to [Ljava.lang.String;
后来转成rdd发现,初始化Array再放进dataframe、rdd中,虽然dtypes和printSchema方法显示的是ArrayType,但是实际上格式是WrappedArray,WrappedArray没法做Array相应的操作。
最简单的方法就是直接转成rdd再处理,直接在map中生成这个Array,代码如下:
import sparkSession.implicits._
var test_df = Seq((1,"1.0,2.0"),(2, "2.0,3.0"),(3,"3.0,4.0")).toDF("imei","feature")
test_df.dtypes
test_df = test_df.rdd.map( v => {
val imei:String = v(0).toString
val features = v(1).toString.split(",").map(_.toDouble)
(imei,features)
}).toDF("imei","feature")
test_df.dtypes
使用udf的解决方法,需要将WrappedArray转化为Array,stackoverflow上也有类似的问题。
import org.apache.spark.sql.functions._
import org.apache.spark.ml.linalg.Vectors
import scala.collection.mutable
//使用如下类似的udf来转换,数组中的类型
def Array2Vector = udf((features: mutable.WrappedArray[Double]) => Vectors.dense(features.toArray))
def ArrayToVector = udf((features: mutable.WrappedArray[Double]) => new DenseVector(features.toArray))
val Array_String2Double = udf{arr:mutable.WrappedArray[String] => arr.toArray.map(_.toDouble)}
val Seq2Vector = udf((xs: Seq[Double]) => new DenseVector(xs.toArray))
3.在使用for循环遍历连续特征把这些连续特征转化为离散特征时报错:
org.codehaus.janino.JaninoRuntimeException: Code of method “processNext()V” of class
“org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator” grows beyond 64 KB
一共三十五个连续特征列,五个五个拆分开来遍历转化这些特征,速度很快且没有报错,说明程序没有问题。但是一次性遍历转化三十五个特征列的时候,到第十七八个就会变得很慢,然后报上面的错误,报完以后会继续遍历下一个。
最后结果是正常的,当遍历数量少的时候(17-20个),这个报错没有对结果造成影响,当遍历数量多的时候,会一直卡住,出不了结果。
最后查到是spark的一个BUG:https://issues.apache.org/jira/browse/SPARK-18492
解决方案:
分几次完成该遍历作业
4.No Space Left on the device(Shuffle临时文件过多)
由于Spark在计算的时候会将中间结果存储到/tmp目录,而目前linux又都支持tmpfs,其实就是将/tmp目录挂载到内存当中。
那么这里就存在一个问题,中间结果过多导致/tmp目录写满而出现如下错误
No Space Left on the device
解决办法:
第一种:修改配置文件spark-env.sh,把临时文件引入到一个自定义的目录中去即可
export SPARK_LOCAL_DIRS=/home/utoken/datadir/spark/tmp
第二种:偷懒方式,针对tmp目录不启用tmpfs,直接修改/etc/fstab
cloudera manager 添加参数配置:筛选器=>高级=>搜索“spark_env”字样,添加参数export SPARK_LOCAL_DIRS=/home/utoken/datadir/spark/tmp到所有配置项
5.长时间等待无反应,并且看到服务器上面的web界面有内存和核心数,但是没有分配,如下图
[Stage 0:> (0 + 0) / 42]
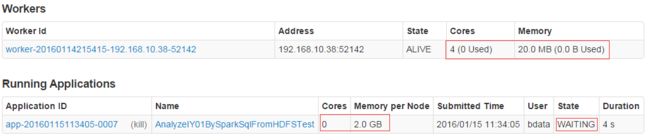
或者日志信息显示:
WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
解决方案:
出现上面的问题主要原因是因为我们通过参数spark.executor.memory设置的内存过大,已经超过了实际机器拥有的内存,故无法执行,需要等待机器拥有足够的内存后,才能执行任务,可以减少任务执行内存,设置小一些即可
6.Job aborted due to stage failure: Task 3 in stage 0.0 failed 4 times, most recent failure: Lost task 3.3 in
[Stage 0:> (0 + 4) / 42]2016-01-15 11:28:16,512 [org.apache.spark.scheduler.TaskSchedulerImpl]-[ERROR] Lost executor 0 on 192.168.10.38: remote Rpc client disassociated
[Stage 0:> (0 + 4) / 42]2016-01-15 11:28:23,188 [org.apache.spark.scheduler.TaskSchedulerImpl]-[ERROR] Lost executor 1 on 192.168.10.38: remote Rpc client disassociated
[Stage 0:> (0 + 4) / 42]2016-01-15 11:28:29,203 [org.apache.spark.scheduler.TaskSchedulerImpl]-[ERROR] Lost executor 2 on 192.168.10.38: remote Rpc client disassociated
[Stage 0:> (0 + 4) / 42]2016-01-15 11:28:36,319 [org.apache.spark.scheduler.TaskSchedulerImpl]-[ERROR] Lost executor 3 on 192.168.10.38: remote Rpc client disassociated
2016-01-15 11:28:36,321 [org.apache.spark.scheduler.TaskSetManager]-[ERROR] Task 3 in stage 0.0 failed 4 times; aborting job
Exception in thread "main" org.apache.spark.SparkException : Job aborted due to stage failure: Task 3 in stage 0.0 failed 4 times, most recent failure: Lost task 3.3 in stage 0.0 (TID 14, 192.168.10.38): ExecutorLostFailure (executor 3 lost)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.orgapachesparkschedulerDAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1283)
解决方案:
这里遇到的问题主要是因为数据源数据量过大,而机器的内存无法满足需求,导致长时间执行超时断开的情况,数据无法有效进行交互计算,因此有必要增加内存
7.内存不足或数据倾斜导致Executor Lost(spark-submit提交)
TaskSetManager: Lost task 1.0 in stage 6.0 (TID 100, 192.168.10.37): java.lang.OutOfMemoryError: Java heap space
16/01/15 14:29:51 INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.37:57139 (size: 42.0 KB, free: 24.2 MB)
16/01/15 14:29:53 INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.38:53816 (size: 42.0 KB, free: 24.2 MB)
16/01/15 14:29:55 INFO TaskSetManager: Starting task 3.0 in stage 6.0 (TID 102, 192.168.10.37, ANY, 2152 bytes)
16/01/15 14:29:55 WARN TaskSetManager: Lost task 1.0 in stage 6.0 (TID 100, 192.168.10.37): java.lang.OutOfMemoryError: Java heap space
at java.io.BufferedOutputStream.(BufferedOutputStream.java:76)
at java.io.BufferedOutputStream.(BufferedOutputStream.java:59)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance$$anon$2.(UnsafeRowSerializer.scala:55)
at org.apache.spark.sql.execution.UnsafeRowSerializerInstance.serializeStream(UnsafeRowSerializer.scala:52)
at org.apache.spark.storage.DiskBlockObjectWriter.open(DiskBlockObjectWriter.scala:92)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.insertAll(BypassMergeSortShuffleWriter.java:110)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:73)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
at org.apache.spark.scheduler.Task.run(Task.scala:88)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
16/01/15 14:29:55 ERROR TaskSchedulerImpl: Lost executor 6 on 192.168.10.37: remote Rpc client disassociated
16/01/15 14:29:55 INFO TaskSetManager: Re-queueing tasks for 6 from TaskSet 6.0
16/01/15 14:29:55 WARN ReliableDeliverySupervisor: Association with remote system [akka.tcp://[email protected]:42250] has failed, address is now gated for [5000] ms. Reason: [Disassociated]
16/01/15 14:29:55 WARN TaskSetManager: Lost task 3.0 in stage 6.0 (TID 102, 192.168.10.37): ExecutorLostFailure (executor 6 lost)
16/01/15 14:29:55 INFO DAGScheduler: Executor lost: 6 (epoch 8)
16/01/15 14:29:55 INFO BlockManagerMasterEndpoint: Trying to remove executor 6 from BlockManagerMaster.
16/01/15 14:29:55 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(6, 192.168.10.37, 57139)
16/01/15 14:29:55 INFO BlockManagerMaster: Removed 6 successfully in removeExecutor
16/01/15 14:29:55 INFO AppClient$ClientEndpoint: Executor updated: app-20160115142128-0001/6 is now EXITED (Command exited with code 52)
16/01/15 14:29:55 INFO SparkDeploySchedulerBackend: Executor app-20160115142128-0001/6 removed: Command exited with code 52
16/01/15 14:29:55 INFO SparkDeploySchedulerBackend: Asked to remove non-existent executor 6
.......
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 6.0 failed 4 times, most recent failure: Lost task 0.3 in stage 6.0 (TID 142, 192.168.10.36): ExecutorLostFailure (executor 4 lost)
......
WARN TaskSetManager: Lost task 4.1 in stage 6.0 (TID 137, 192.168.10.38): java.lang.OutOfMemoryError: GC overhead limit exceeded
解决办法:
由于我们在执行Spark任务是,读取所需要的原数据,数据量太大,导致在Worker上面分配的任务执行数据时所需要的内存不够,直接导致内存溢出了,所以我们有必要增加Worker上面的内存来满足程序运行需要。
在Spark Streaming或者其他spark任务中,会遇到在Spark中常见的问题,典型如Executor Lost 相关的问题(shuffle fetch 失败,Task失败重试等)。这就意味着发生了内存不足或者数据倾斜的问题。这个目前需要考虑如下几个点以获得解决方案:
A、相同资源下,增加partition数可以减少内存问题。 原因如下:通过增加partition数,每个task要处理的数据少了,同一时间内,所有正在运行的task要处理的数量少了很多,所有Executor占用的内存也变小了。这可以缓解数据倾斜以及内存不足的压力。
B、关注shuffle read 阶段的并行数。例如reduce,group 之类的函数,其实他们都有第二个参数,并行度(partition数),只是大家一般都不设置。不过出了问题再设置一下,也不错。
C、给一个Executor 核数设置的太多,也就意味着同一时刻,在该Executor 的内存压力会更大,GC也会更频繁。我一般会控制在3个左右。然后通过提高Executor数量来保持资源的总量不变。
8.spark运行正常,某一个Stage卡住
spark提交任务后,前N个Stage运行顺利,卡在某一个Stage,通过sparkUI可以看到,executor运行正常,卡住的Stage的task已经分配至executor,但duration time一直增加,task却不结束,log中没有报错。程序之前有跑通过,无BUG。
解决方法:
有可能是计算太多CPU资源不够,复用超过三次的dataframe一定要持久化。使用df.persist()即可跑通。
9. Exception in thread "main" org.apache.spark.SparkException: Application application_1534307609564_277105 finished with failed status**
spark-submit提交master为yarn cluster,改成yarn client,原因是因为,代码里指定了master为本地测试用(local),需要把local删除或者改成yarn client。
10. ERROR log: error in initSerDe: java.lang.ClassNotFoundException Class org.apache.hive.hcatalog.data.**
正常使用sparksession去查表的时候,出现这个异常,那么我们需要引入org.apache.hive.hcatalog这个包。
例如当需要读取的hive表中有json格式的数据时,我们就需要使用这个包。
在服务器中进入自己的jars文件夹,用rz命令上传需要的jar文件,输入rz回车,选择文件并上传:hive-hcatalog-core-0.13.1.jar
然后在启动spark时候,在启动命令中加入--jars /home/myname/myjars/hive-hcatalog-core-0.13.1.jar 上传这个依赖包即可。
11. Exception in thread "main" java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)[Ljava/lang/Object
代码直接在spark-shell中可以运行,但是打包到平台上却报这个错是因为scala版本不匹配造成的,官方的Scala依赖是2.11, spark2.2 的依赖也是2.11 所以如果你的Scala版本是2.22或者较老版本,需要换到这个版本,不然可能会报错或者出现sparksession不能初始化的问题。
如果检查完pom文件中依赖没有问题,那么可能需要查看一下
12.Caused by: java.lang.IllegalArgumentException: 8858 is not strictly increasing
稀疏矩阵中的index.array 中的index一定是严格递增且没有重复的。
13.启动spark-shell或进入scala单机版是报错
Failed to initialize compiler: object java.lang.Object in compiler mirror not found.
** Note that as of 2.8 scala does not assume use of the java classpath.
** For the old behavior pass -usejavacp to scala, or if using a Settings
** object programmatically, settings.usejavacp.value = true.
java9与spark兼容出现问题,改成java8替换即可。
14.Caused by: java.lang.NullPointerException
空指针异常。
spark在hive表或者其他外部数据源中取数的时候,需要先筛选空值,filter(col1 is not null and col2 is not null and col3 is not null)。
有的时候由于特殊原因,某列需要允许其带有空值,那边map转化的时候就不能使用toString,而需要改用getString,当那一列有空值时,getString会返回“null”。
例如:
df.rdd.map(v.getString(columnIndex))
getString
- 参数:columnIndex(列索引),从0开始,第一列是 0,第二列是 1,……
- 返回:列值;如果值为 SQL NULL,则返回值为 null
15.单条记录消耗大
使用mapPartition替换map,mapPartition是对每个Partition进行计算,而map是对partition中的每条记录进行计算。
16. 各种timeout,executor lost ,task lost
spark.network.timeout 根据情况改成300(5min)或更高,通常设置到600s。默认设置为 120s。
Reference:
http://dblab.xmu.edu.cn/blog/1313-2/
https://stackoverflow.com/questions/47543747/how-to-convert-a-dataframe-of-array-of-doubles-to-vectors
https://www.cnblogs.com/arachis/p/Spark_Exception.html
https://issues.apache.org/jira/browse/SPARK-18492
http://lxw1234.com/archives/2016/05/661.htm