开公众号啦,「心智万花筒」欢迎一起读书交流成长。

qr-code
资源
- 地震数据
- read_html
- read_html参数详解
- mpl_toolkits安装参考,官方安装说的不是很清楚。
- Basemap很nice的教程
- Bug: 'NoneType' object has no attribute 'next_element'
- Request乱码问题
import pandas as pd
import requests
import numpy as np
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
%matplotlib inline
小练习
参见此处。
html_1 = requests.get('http://zh.wikipedia.org/wiki/%E7%9C%81%E4%BC%9A')
html_1_text = html_1.text
dfs_1 = pd.read_html(html_1_text,header=0,attrs={'class': 'wikitable'})
dfs_1[0].head()
| 編號 | 行政區 | 簡稱 | 省會或首府 | 地區 | Unnamed: 5 | 編號.1 | 行政區.1 | 簡稱.1 | 省會或首府.1 | 地區.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 江蘇省 | 蘇 | 鎮江 | 華中 | 20 | 甘肅省 | 隴 | 蘭州 | 華北 | NaN |
| 1 | 2 | 浙江省 | 浙 | 杭州 | 華中 | 21 | 寧夏省 | 寧 | 銀川 | 塞北 | NaN |
| 2 | 3 | 安徽省 | 皖 | 合肥 | 華中 | 22 | 青海省 | 青 | 西寧 | 西部 | NaN |
| 3 | 4 | 江西省 | 贛 | 南昌 | 華中 | 23 | 綏遠省 | 綏 | 歸綏(今呼和浩特) | 塞北 | NaN |
| 4 | 5 | 湖北省 | 鄂 | 武昌(今武漢) | 華中 | 24 | 察哈爾省 | 察 | 張垣(今張家口) | 塞北 | NaN |
读取表格read_html
安装
read_html依赖一些库,比如html5lib,lxml,beautiful soup等,如果没有安装会报错。
Bug
直接用pd.read_html()一直出错,上个小例子没问题,但读取这个网站出了问题:
AttributeError: 'NoneType' object has no attribute 'next_element'
google后发现可能是beautifulsoup4版本的问题,在这找到一点线索,然后pip uninstall beautifulsoup4 and pip install beautifulsoup4=='4.0.5'解决问题了,不是很清楚为何。
吐槽
本来就想安安静静地写一行解决问题,谁知道还有坑有坑
dsf = pd.read_html('http://data.earthquake.cn/datashare/globeEarthquake_csn.html',header=0)[4]
执行后文字部分都是乱码,应该是编码问题,下面给出了解决方案。
不过我忍不住要吐槽一句,为什么这个网站把所以的内容都放在table里,如果这样,能不能给个id或者class,导致利用attrs精确获得表格的微操失败,心中也是万马奔腾。
获取数据
url = 'http://data.earthquake.cn/datashare/globeEarthquake_csn.html'
html = requests.get(url)
乱码问题
request默认是ISO-8859-1编码,这里会导致乱码
html.encoding
'ISO-8859-1'
html_text = html.text
dfs = pd.read_html(html_text,header=0)
dfs[4].head()
| ·¢ÕðÈÕÆÚ | ·¢Õðʱ¿Ì | γ¶È(¡ã) | ¾¶È(¡ã) | Éî¶È(km) | Õ𼶠| ʼþÀàÐÍ | ²Î¿¼µØµã | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-24 | 20:12:09.6 | 40.9 | 79.3 | 6 | Ms3.2 | ÌìÈ»µØÕð | н®°¢¿ËËÕµØÇøÎÚʲÏØ |
| 1 | 2016-05-24 | 18:34:34.2 | 40.2 | 77.2 | 8 | Ms3.0 | ÌìÈ»µØÕð | н®¿Ë×ÎÀÕËÕÖÝ°¢Í¼Ê²ÊÐ |
| 2 | 2016-05-24 | 08:56:14.7 | 37.4 | 92.9 | 10 | Ms3.0 | ÌìÈ»µØÕð | Çຣº£Î÷Öݸñ¶ûľÊÐ |
| 3 | 2016-05-24 | 03:09:56.5 | 28.0 | 85.3 | 8 | Ms3.8 | ÌìÈ»µØÕð | Äá²´¶û |
| 4 | 2016-05-24 | 02:09:01.5 | 28.6 | 87.5 | 7 | Ms3.9 | ÌìÈ»µØÕð | Î÷²ØÈÕ¿¦ÔòÊж¨ÈÕÏØ |
改变默认编码
html.encoding = html.apparent_encoding
html.encoding #竟然是GB2312,一开始窃以为是UTF-8...
'GB2312'
html_text = html.text
dfs = pd.read_html(html_text,header=0) # 返回的是一个list,list里是表格
dfs[4].head()
| 发震日期 | 发震时刻 | 纬度(°) | 经度(°) | 深度(km) | 震级 | 事件类型 | 参考地点 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-24 | 20:12:09.6 | 40.9 | 79.3 | 6 | Ms3.2 | 天然地震 | 新疆阿克苏地区乌什县 |
| 1 | 2016-05-24 | 18:34:34.2 | 40.2 | 77.2 | 8 | Ms3.0 | 天然地震 | 新疆克孜勒苏州阿图什市 |
| 2 | 2016-05-24 | 08:56:14.7 | 37.4 | 92.9 | 10 | Ms3.0 | 天然地震 | 青海海西州格尔木市 |
| 3 | 2016-05-24 | 03:09:56.5 | 28.0 | 85.3 | 8 | Ms3.8 | 天然地震 | 尼泊尔 |
| 4 | 2016-05-24 | 02:09:01.5 | 28.6 | 87.5 | 7 | Ms3.9 | 天然地震 | 西藏日喀则市定日县 |
df = dfs[4]
df.columns = ['date','time','lats','lons','dept','mag','class','place']
df.head(3)
| date | time | lats | lons | dept | mag | class | place | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2016-05-24 | 20:12:09.6 | 40.9 | 79.3 | 6 | Ms3.2 | 天然地震 | 新疆阿克苏地区乌什县 |
| 1 | 2016-05-24 | 18:34:34.2 | 40.2 | 77.2 | 8 | Ms3.0 | 天然地震 | 新疆克孜勒苏州阿图什市 |
| 2 | 2016-05-24 | 08:56:14.7 | 37.4 | 92.9 | 10 | Ms3.0 | 天然地震 | 青海海西州格尔木市 |
画地震分布图
不太懂地震,除了了解一下分布,不知道还分析什么,就先画个分布图吧。
把以Ms震级开头的行去掉(共7个),只保留ML开头的,便于分析
Ms = df.mag.map(lambda x: not x.startswith('Ms')) # boolean Series
df = df[Ms]
把震级转换为数字
import re
get_num = lambda x: float(re.findall('\d+\.\d+', x)[0])
# a = 'ML0.5'
# n = re.findall('\d+\.\d+', a)
# float(n[0])
# df['mag_num'].loc[:] = df.loc[:,'mag'].map(get_num)
# df['mag_num'] = df['mag'].map(get_num) 会报错
# http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
temp = df['mag'].map(get_num)
df.loc[:,('mag_num')] = temp
df.head(3)
| date | time | lats | lons | dept | mag | class | place | mag_num | |
|---|---|---|---|---|---|---|---|---|---|
| 5 | 2016-05-23 | 23:43:52.5 | 23.30 | 103.21 | 6 | ML1.7 | 天然地震 | 云南个旧 | 1.7 |
| 6 | 2016-05-23 | 23:43:33.9 | 39.82 | 118.76 | 8 | ML0.5 | 天然地震 | 河北滦县 | 0.5 |
| 7 | 2016-05-23 | 23:36:25.9 | 39.60 | 76.93 | 6 | ML1.4 | 天然地震 | 新疆伽师 | 1.4 |
获取地图分布范围,经纬度表示
# lower left
llcrnrlon, llcrnrlat = df['lons'].min(), df['lats'].min()
# upper right
urcrnrlon, urcrnrlat = df['lons'].max(), df['lats'].max()
获取地震地点经纬度及强度
lons, lats = list(df['lons']), list(df['lats'])
mags = list(df['mag_num'])
辅助函数
不同的等级用不同的颜色
# 按等级配色
def get_marker_color(magnitude):
# Returns green for small earthquakes, yellow for moderate
# earthquakes, and red for significant earthquakes.
if magnitude < 1.5:
return ('go')
elif magnitude < 3.0:
return ('yo')
else:
return ('ro')
作图
fig = plt.figure(figsize=(14,10))
ax = plt.subplot(1,1,1)
eq_map = Basemap(projection='merc', resolution = 'l', area_thresh = 1000.0,
lat_0=0, lon_0=120,
llcrnrlon=llcrnrlon-5, llcrnrlat=llcrnrlat-8,
urcrnrlon=urcrnrlon+10, urcrnrlat=urcrnrlat+3)
eq_map.drawcoastlines()
eq_map.drawcountries()
eq_map.fillcontinents(color = 'lightgray')
eq_map.drawmapboundary()
eq_map.drawmeridians(np.arange(0, 360, 30))
eq_map.drawparallels(np.arange(-90, 90, 30))
min_marker_size = 4
for lon, lat, mag in zip(lons,lats,mags):
x,y = eq_map(lon, lat)
msize = mag*min_marker_size
marker_string = get_marker_color(mag)
eq_map.plot(x, y, marker_string, markersize=msize)
plt.show()
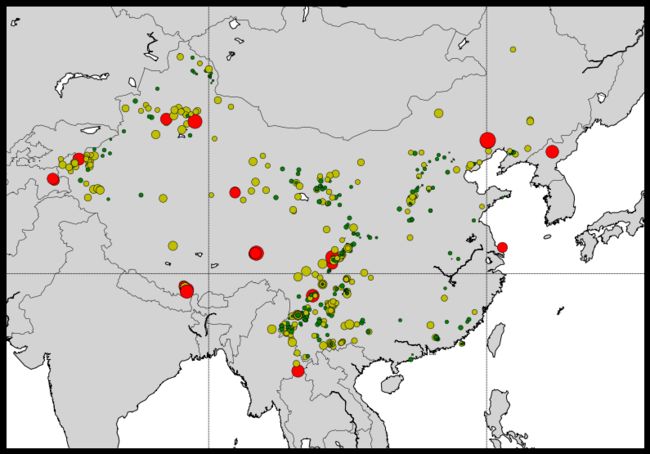
地震分布
可以看到最近一段时间地震在全国范围内的分布。