前言
本文将会作为开启SurfaceFlinger的系列第一篇文章。然而SurfaceFlinger几乎贯通了整个Android领域中所有的知识。从HAL硬件抽象层到Framework层,从CPU绘制到OpenGL等硬件绘制。
为了让整个系列的书写更有逻辑性。这一次我将一反常态,先把整个架构的设计思想概述写出来,作为后面的系列文章的指导。本文之后都会将SurfaceFlinger称为SF。
遇到什么疑问,可以来本文下讨论:https://www.jianshu.com/p/c954bcceb22a
正文
SF的渲染第一定律:
SF是整个Android系统渲染的核心进程。所有应用的渲染逻辑最终都会来到SF中进行处理,最终会把处理后的图像数据交给CPU或者GPU进行绘制。
姑且让我们先把这句话当作Android渲染系统的第一定律。SF在整个Android系统中,并非担当渲染的角色,而是作为图元抛射机一样,把所有应用进程传递过来的图元数据加工处理后,交给CPU和GPU做真正的绘制。
SF的渲染第二定律:
在每一个应用中都以Surface作为一个图元传递单元,向SF这个服务端传递图元数据。
这是Android渲染体系的第二定律。把这两个规律组合起来就是如下一个简单示意图。
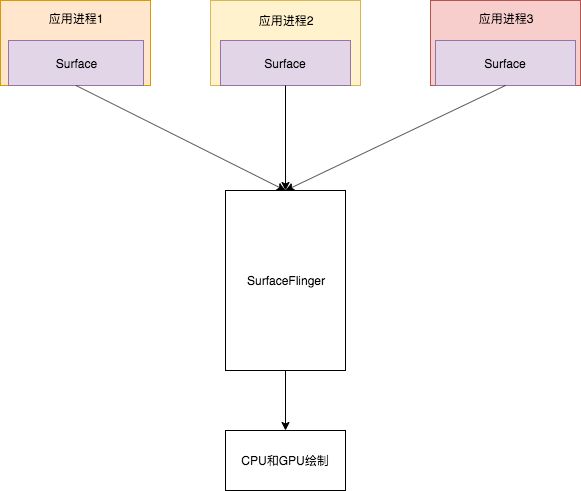
SF的渲染第三定律:
SF是以生产者以及消费者为核心设计思想,把每一个应用进程作为生产者生产图元保存到SF的图元队列中,SF则作为消费者依照一定的规则把生产者存放到SF中的队列一一处理。
用图表示就如下:
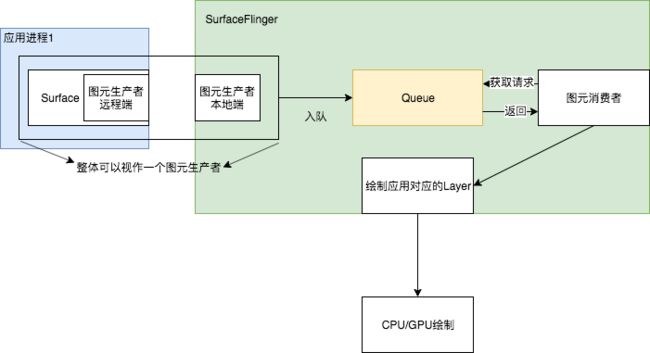
SF体系渲染的第四定律:
为了能够跨进程的传输大容量的图元数据,使用了匿名共享内存内存作为工具把图元数据都输送到SF中处理。
众所周知,我们需要从应用进程跨进程把图元数据传输到SF进程中处理,就需要跨进程通信,能考虑的如socket这些由于本身效率以及数据拷贝了2份(从物理内存页层面上来看),确实不是很好的选择。一个本身拷贝大量的数据就是一个疑问。那么就需要那些一次拷贝的进程间通信方式,首先能想到的当然是Binder,然而Binder进程间通信,特别是应用的通信数据总量只有1M不到的大小加上应用其他通信,势必会出现不足的问题。
为了解决这个问题,Android使用共享内存,使用的是匿名共享内存(Ashmem)。匿名共享内存也是一种拷贝一次的进程间通信方式,其核心比起binder的复杂的mmap更加接近Linux的共享内存的概念。
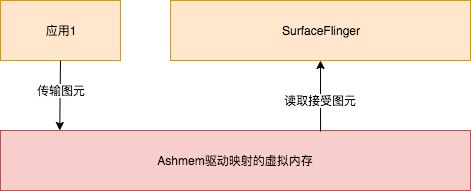
SF体系渲染的第五定律:
SF底层有一个时间钟在不断的循环,或从硬件中断发出,或从软件模拟发出计时唤起,每隔一段时间都会获取SF中的图元队列通过CPU/GPU绘制在屏幕。
第五定律的诞生实际上很符合Android系统的设计情况,除了需要Android应用有办法通知SF需要渲染的模式,当然需要SF自己不断的把图元绘制到屏幕的行为的自己回调自己的行为,SF自己不断的绘制在SF中的图元数据。
其中EventThread扮演一个极其重要的角色,在SF中设计大致如下:
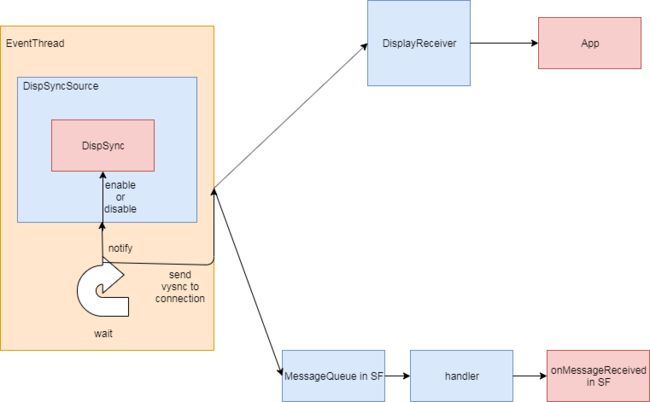
Vsync的介绍
这里面出现了一个新的名次VSync,其实这就是我们玩游戏经常说的垂直同步信号。我以前用渣电脑玩游戏的时候,经常掉帧数卡的不行,之后关闭了垂直信号后感觉好了点,让我有一段时间以为这是个不好的东西。
这里就先介绍一下Android曾经迭代为ui体验更好上的努力,黄油计划。黄油计划故名思议就是为了让系统的ui表现如黄油表面一样顺滑。为此诞生了两个重要的概念Vsync以及Triple Buffer,即垂直信号和三重缓冲。
双缓冲的概念大家应该都熟悉,在OpenGL我已经解释过了,双缓冲就是渲染第一帧的同时已经在绘制第二帧的内容,等到第二帧绘制完毕后就显示出来。这么做的好处很明显,如果一帧画完,才开始画下一帧,势必有一个计算的过程导致ui交互迟缓。
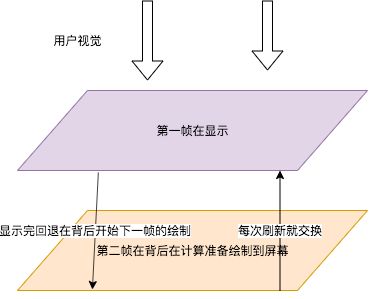
通过这种方式显示前一帧的时候提前绘制好下一帧图元,放在背后等待时机交换,这样就能从感官上流畅不少。
这么做理想十分显示,但是怎么找到一个合适的时机进行交换前后两帧这是一个问题?如果有人在想那就按照屏幕刷新频率来,一般按照通用屏幕刷新60fps也就是约16ms刷新一次即可。
理想是很丰满,但是现实很骨干,这么做好像没有问题,我们深入考虑一下,其实这个过程中有两个变量,一个是绘图速度,一个是显示速度。就算是绘图速度中也有分CPU和GPU的绘制速度。
这里就沿用一下当年google在宣传黄油计划时候的示意图。让我们先看看没有缓冲正常运作的示意图:

最好的情况就是上图,在显示第0帧的时候,CPU/GPU合成绘制完成第1帧在16ms内,当vsync信号来了,就把第1帧交换到显示屏显示。
vsync是什么?玩游戏的时候经常看到垂直同步就是它。它的作用是通过屏幕硬件中断来告诉系统应该什么时候刷新屏幕。通过这样的方式,大致上16ms的发送一次中断让系统刷新。
但是很可能出现下面这种情况,CPU因为繁忙来不及,显示完第一帧的时候,还没空渲染第二帧,就算SF接受到了Vsync的信号,也只能拿出已经渲染好的第一帧显示在屏幕上。这样就重复显示了第一帧,Google开发团队称这种为jank。
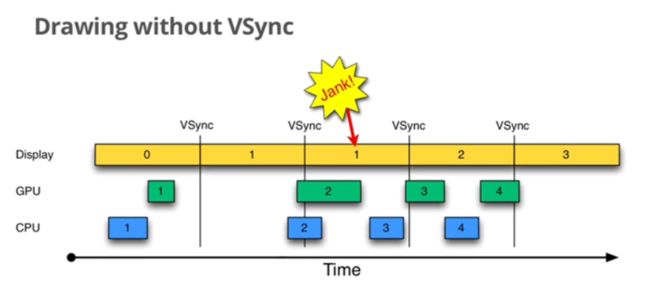
能看到显示第一帧因为第二帧没准备好,只能重复显示第一帧了。
再来看看带着多重缓冲的的工作原理流程:

能看到此时就不是简单的第一第二帧,而是分为A缓冲,B缓冲。能看到在正常情况下,先显示A缓冲的内容,同时准备B缓冲,当一切正常的时候,B缓冲应该在下一个vsync来之前准备好,一旦vsync到来则显示B缓冲,A缓冲回到后台继续绘制。
那么这种方式一旦遇到jank会是怎么一个情况呢?

如果是双缓冲好像没有问题,但是一旦出现jank了之后,之后显示屏就会不断的出现jank。如果缓冲A在显示,而B准备的时间超过16ms,就会导致A缓冲区重复显示,而B当b显示的时候,A也很可能准备时间不足16ms导致无法绘制完成,只能重复显示B缓冲的内容。
这种方式更加的危险,为了解决这个问题,Google引入三重缓冲。
当三重缓冲处理jank的原理流程图:

能看到为了避免后面连锁式的错误,引入三重缓冲就为了让空闲出来的等待时间,能够做更多的事情。就如同双缓冲遇到jank之后,一旦B缓冲CPU+GPU的时间超过了下一个vsync的时间,能够发现其实CPU和GPU有一段时间都没有事情做,光等待下一次Vsync的到来,才会导致整个系统后面的绘制出现连锁式的出现jank。
而三缓冲的出现,在重复显示A缓冲区的时候,CPU不会光等待而是会准备C缓冲区的图元,之后就能把C缓冲区接上。这就是Google所说的三重缓冲区的来源。
不过绝大多数情况都缓冲策略是由SF系统自己决定的,一般我们常说的双缓冲,三缓冲指的就是这个。
实际上这种方式也可以用到音视频的编写优化,里面常用的缓冲区设计和这里也有同工异曲的之妙,但是没有系统如此极致。如果阅读过系统的videoView源码就能看到NullPlayer本质上就是借助Surface图元缓冲区来达到极致的体验,不过VideoView也有设计不合理的地方,之后研读完Android的渲染体系,让我们来分析分析这些源码。
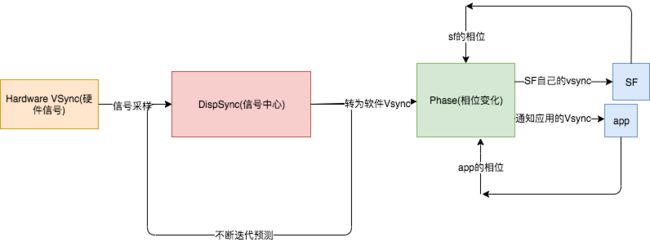
但是这一部分的知识,不足以让我们去理解定律5.其实每一次Vsync从硬件/软件过来的时候,Dispsync都会尝试着通知SF和app,这是完全没有问题,但是后面那个Phase相位又是什么东西?
其实这就是系统的设计的巧妙,我们如果同时把信号通知同时告诉app和sf会导致什么结果?
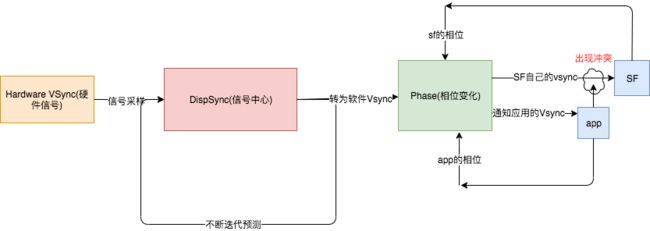
如果此时app后返回了图元,但是sf已经执行了刷新合成绘制行为(很有可能,因为app到sf传输图元速度必定比sf自己通知自己慢),此时就会导致类似jank的问题,导致下一个vsync还是显示当前帧数,因此需要如下一个时间差,先通知app后通知sf,如下图:
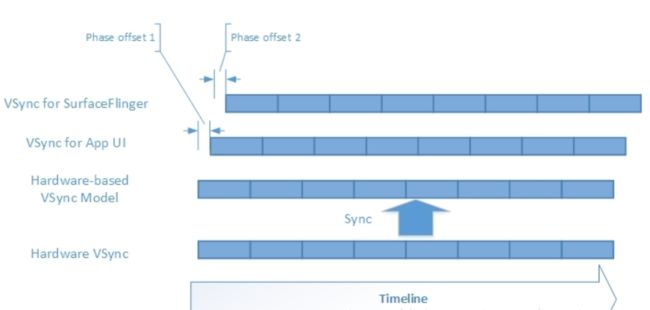
加上这个理解就能明白第五定律。关于第五点的讨论,在Vsync同步信号原理有详细讨论。
小结
这五大定律是指导SF设计的核心思想,从Android4.1一直到9.0都没有太大的变化。只要抓住这五个核心思想,我们阅读起SF的难度就会下降不少。
那么SF的体系和我之前聊过的Skia有什么关系呢?又和顶层的View的绘制流程有什么关系呢?
我们按照角色区分一下:
- framework面向开发者所有的View是便于开发的控件,里面仅仅只是提供了当前View各种属性以及功能。
- 而Android底层的Skia是Android对于屏幕上的画笔,经过View绘制流程的onDraw方法回调,把需要绘制的东西通过Skia绘制成像素图元保存起来
- SF则是最后接受Skia的绘制结果,最后绘制到屏幕上。
所以说,Skia是Android渲染核心这句话没错,但是最终还是需要Skia和系统所提供起来,才是一个Android完整渲染体系。
经过这一层层的屏蔽,让开发者不需要对Android底层的渲染体系有任何理解,也能绘制出不错的效果。
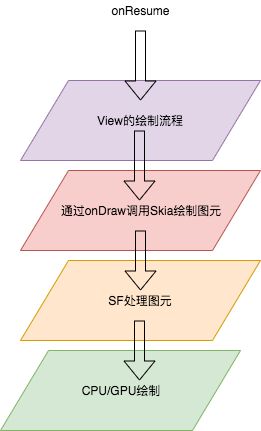
最后会把绘制结果传输到屏幕中。
因此,本次计划将会从底层核心,慢慢向上剖析,直到View的绘制流程,让我们那彻底通读整个android的渲染体系。
计划
本次计划SurfaceFlinger的文章将会通过如下模块一一解析(但是不代表一个模块就只有一篇,也不代表最终顺序,仅仅代表你将会阅读到什么内容):
-
-
图元核心传输工具,匿名共享内存ashmem驱动的核心原理,ashmem原理图大致如下:
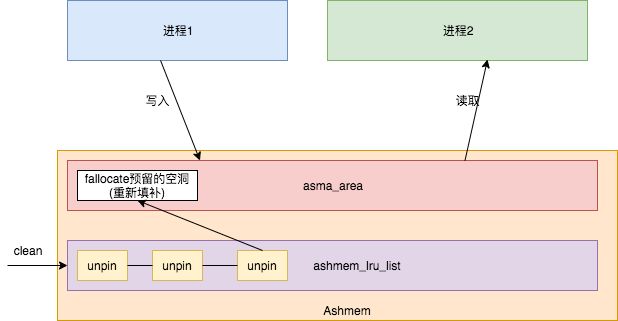 ashmem.png
ashmem.png
-
详见匿名内存ashmem源码分析。然而在Android高版本,已经放弃了ashemem,改用ion驱动。ion的原理图大致如下:
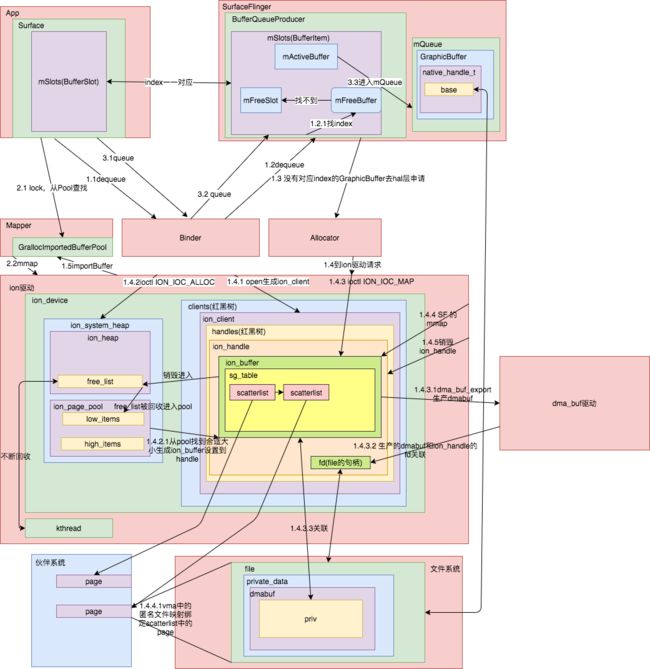
关于ion的分析,详见ion驱动源码浅析
ion实际上是生成DMA直接访问内存。原本ashmem的方式需要从GPU访问到CPU再到内存中的地址。但是在这里就变成了GPU直接访问修改DMA,CPU也能直接修改DMA。这就是最大的变化。
-
- SurfaceFlinger的启动。
详见SurfaceFlinger 的初始化,原理图大致如下:
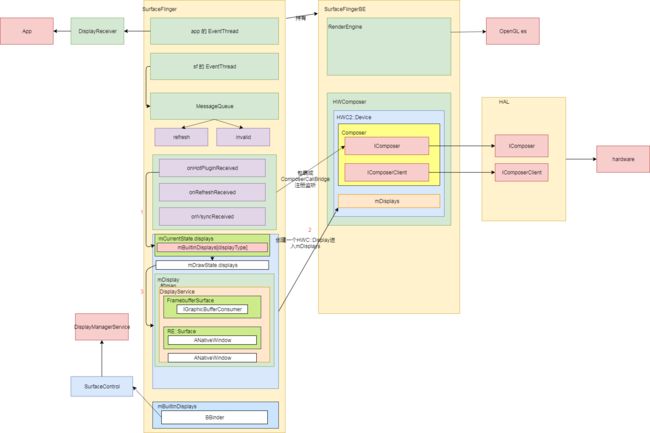 SF 初始化结构.png
SF 初始化结构.png
- SurfaceFlinger的启动。
-
- 开机没有Activity,只能直接使用SF机制加上OpenGL es显示开机动画,来看看从linux开机动画到Android开机动画 BootAnimation 。
详见系统启动动画,原理图大致如下:
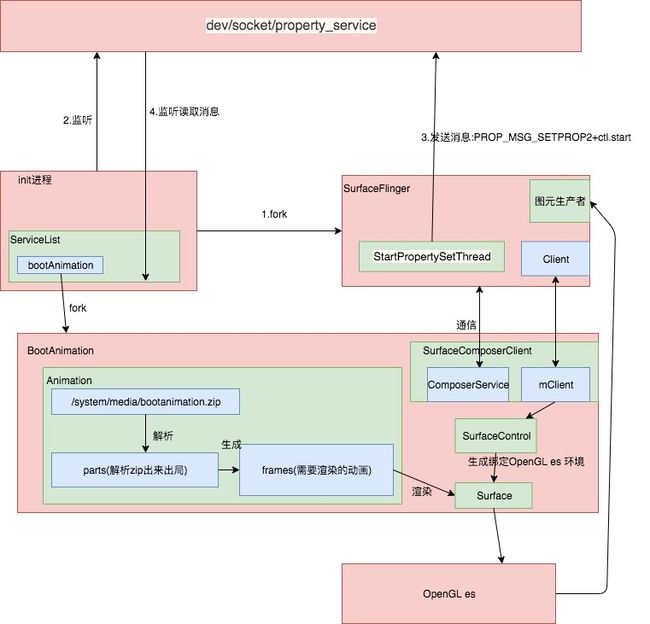 开机动画启动原理.jpg
开机动画启动原理.jpg
- 开机没有Activity,只能直接使用SF机制加上OpenGL es显示开机动画,来看看从linux开机动画到Android开机动画 BootAnimation 。
-
- 理解应用进程如何和SF构建起联系。
详见Vsync同步信号原理。SF是通过一个名为Choreographer监听VSync进而得知绘制周期的。原理图大致如下:
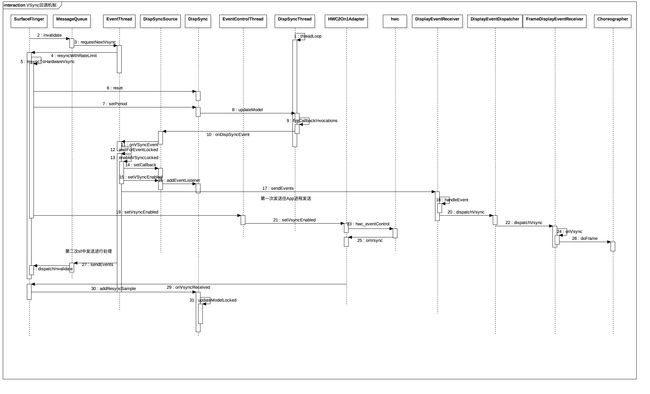 VSync回调机制.jpg
VSync回调机制.jpg
- 理解应用进程如何和SF构建起联系。
-
- SF硬件抽象层hal的理解和运作,理解SF如何和底层HWC/fb驱动关联起来。
详见SurfaceFlinger 的HAL层初始化
其核心数据结构如下:
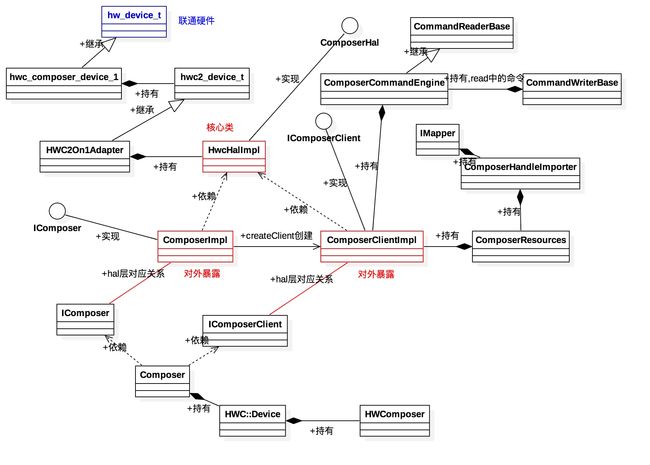
底层硬件回调和SF之间的关联原理图如下:
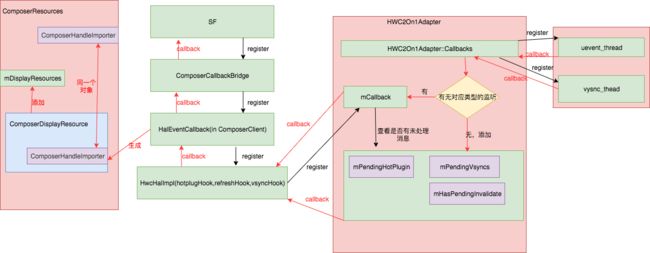
-
- SF是如何连通DisplayManagerService[略,之后有机会进行补充],只是简单的通过SurfaceFlinger获取屏幕信息放在Framework层管理。
-
- Android端在opengl es的核心原理,看看Android对opengl es上做了什么封装。
这个模块分为两部分解析:
一个是正常的OpenGL es使用流程中,软件模拟每一个关键步骤的工作原理是什么,Android在其中进行了什么优化。详见OpenGL es上的封装(上)
其中有一个十分关键的数据结构,UML图如下:
 纹理结构.png
纹理结构.png
- Android端在opengl es的核心原理,看看Android对opengl es上做了什么封装。
一个纹理在OpenGL es中是如何合成绘制的,并且Android进行了本地纹理的优化,详见OpenGL es上的封装(下),整个OpenGL es的绘制原理如下:
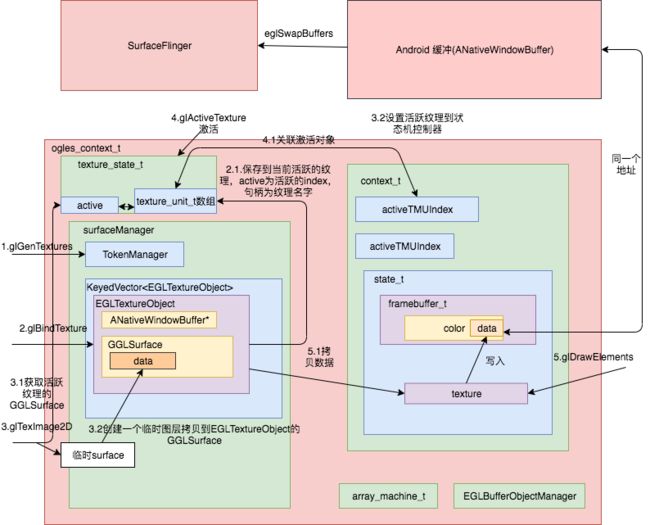
-
- 图元是怎么通过hal层生产出图元数据;应用的图元数据又是获取到应用,如何进入SurfaceFlinger的缓冲队列。
详见GraphicBuffer的诞生。其中涉及了几个重要的数据结构:
 GraphicBuffer生成体系.png
GraphicBuffer生成体系.png
- 图元是怎么通过hal层生产出图元数据;应用的图元数据又是获取到应用,如何进入SurfaceFlinger的缓冲队列。
同时运行原理图如下:

-
- 应用的图元数据是如何消费的。
详见图元的消费,交换缓冲绘制参数,本质是取出一个GraphicBuffer存到缓冲队列的时间和当前时间预计显示最接近的一个,渲染到屏幕中。同时把上一帧的GraphicBuffer放到空闲队列中。
- 应用的图元数据是如何消费的。
其中,我们需要记住下面这个SF中缓冲队列设计的数据结构:
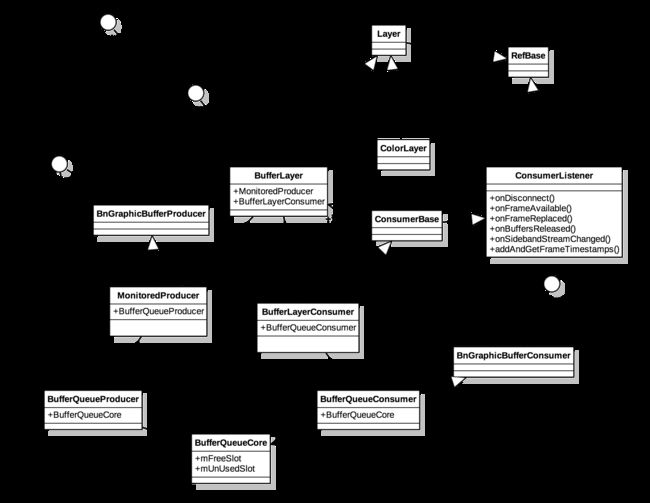
-
- SF是如何通过HWC合成图层,如何合并各个Layer,输出到opengles中处理。
大致上可以分为如下如下7步骤:
1.preComposition 预处理合成
2.rebuildLayerStacks 重新构建Layer栈
3.setUpHWComposer HWC的渲染或者准备
这三步骤,我称为绘制准备,详见图元的合成(上) 绘制的准备
在绘制准备的过程中,最重要的是区分了如下几种绘制模式,已经存储相关的数据到HWC的Hal层中。
- SF是如何通过HWC合成图层,如何合并各个Layer,输出到opengles中处理。
| Composition的Layer的Type | hasClientComposition | hasDeviceComposition | 渲染方式 |
|---|---|---|---|
| HWC2::Composition::Client | true | - | OpenGL es |
| HWC2::Composition::Device | - | true | HWC |
| HWC2::Composition::SolidColor | - | true | HWC |
| HWC2::Composition::Sideband | - | true | HWC或者OpenGL es |
4.doDebugFlashRegions 打开debug绘制模式
5.doTracing 跟踪打印
6.doComposition 合成图元
7.postComposition 图元合成后的vysnc等收尾工作。
后面四个步骤,我们只需要关注最后两个步骤即可。详见图元的合成(下)
整一套的从消费到合成的流程原理图大致如下:

在合成的过程中,分为HWC和OpenGL es两种,两者负责的角色大致如下:

当然,在Android渲染体系中,也不是只有一对生产者消费者模型:
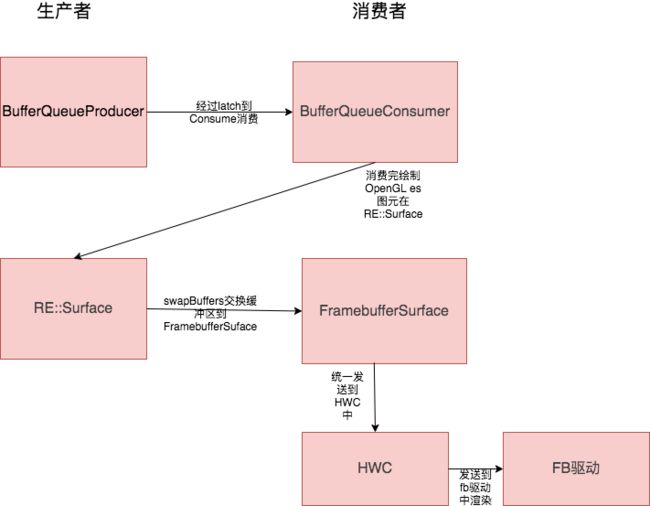
-
- SF的Vsync原理,以及相位差计算原理
整个VSync发送中有三种发送周期:硬件发送VSync周期,软件发送VSync周期,app处理VSync周期,sf处理VSync周期。
详见Vsync同步信号原理
- SF的Vsync原理,以及相位差计算原理
Android为了方便,会暂时把整个周期看成一个周期连续性的函数,计算原理如下:
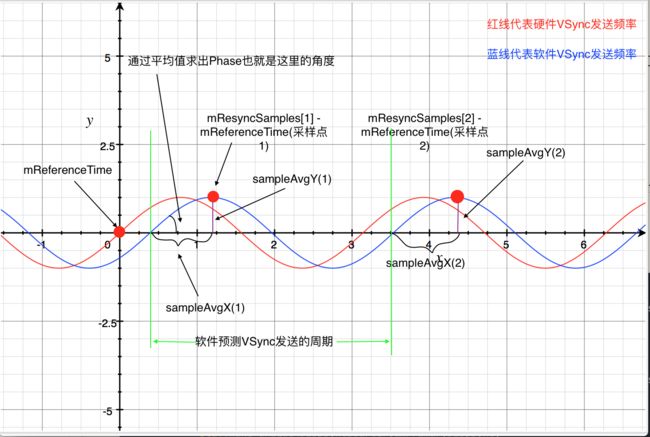
其实就是获取每一个采样点相位,计算采样点相位的平均值就是理想相位。同理,周期也是计算采样点的平均周期,从而计算出一个合适的软件发送VSync轴。
最后在软件渲染的基础上,app的VSync和sf的VSync各自进行延时接受处理,避免出现定律的时序冲突,就是上面那一副蓝色的图。
-
- SF的fence 同步栅工作原理
详见fence原理
想要弄懂Fence,需要先了解GraphicBuffer的状态变更:
大致分为如下几个状态:dequeue(出队到应用中绘制),queue(入队到SF缓冲区等待消费),acquire(选择渲染的GraphicBuffer),free(消费完毕后等待dequeue)
 GraphicBuffer状态流转.png
GraphicBuffer状态流转.png
- SF的fence 同步栅工作原理
Fence的状态更简单,有acquire,release,retried状态流转大致如下:
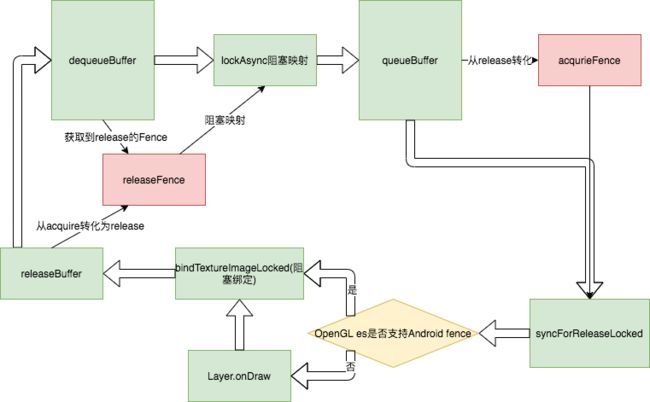
retried是每一次绘制完都会合并在一个不用的Fence中进行记录。
总结一句话,Fence的acquire状态其实是阻塞什么时候可以被消费,什么时候可以被渲染到屏幕;而Fence的release状态则是控制什么时候可以出队给应用进行绘制,什么时候可以被映射到内存。
只有理解这12点,才能说你了解SF了,也不能说精通,毕竟你没办法盲敲出来。
等这12点全部理解通之后,会开启Skia新的篇章,来聊聊Skia的工作原理以及源码解析,最后我们会回归本源,来聊聊View的绘制流程以及WMS。
这个只是一个导读,在这12个知识点背后藏着不少的东西,希望一个总纲能让人有一个总揽,不至于迷失在源码中。
后话
作为每一个经常和UI交互的工程师,有必要也必须要熟悉Android 的渲染原理,只有这样才能让我们写出更加优秀代码,特别是做音视频的哥们,更加有必要阅读这些代码以及看看工业级别的Android的VideoView是如何设计的。其实我在学习一些关于音视频资料的时候,用ffmpeg编写一个视频播放器,发现其实那些demo还有很多地方可以优化的,可以学习flutter如何工作的,如何依托自身平台做进一步优化,而不是应该去做一个泛用的,还过得去的东西。
我会随着进度不断修改本文,本文不是最终版本,会不断的添加不少设计示意图以及UML图。