RDD算子的分类
RDD算子从对数据操作上讲,大致分为两类: 转换(transformations)和行动(action)
转换算子: 将一个RDD转换为另一个RDD,这种变换并不触发提交作业,完成作业中间过程处理
行动算子:将一个RDD进行求值或者输出,这类算子会触发 SparkContext 提交 Job 作业
一行wordcount: sc.textFile("hdfs://master01:9000").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://master01:9000/out") //textFile读取的文件后,成了一行一行的,然后flatMap就是将每一行都按" "分割,现在的状态就是单个单个的单词,一行就是一个集合,map则将每一个word都进行作用,_表示匹配,标为1,形成key为单词,value为数字1,形成多个集合.reduceByKey就是将所有的key相同的进行聚合,value相加.,saveAsTextFile是输出到HDFS.
转换算子(15)
1.map
将函数应用于RDD中的每一元素,并返回一个新的RDD
2.flatMap
将函数应用于RDD中的每一项,并每一项都成了集合,,再将所有集合压成一个大集合

3.mapPartitions
mapPartitions 函数获取到每个分区的迭代器,利用获取到的迭代器对整个分区内的元素计算
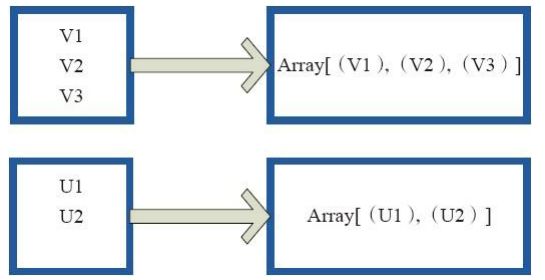
4.glom
将每个分区里的元素都变成数组
5.union
将两个RDD进行合并,但是得保证两个RDD里面得数据类型得一样

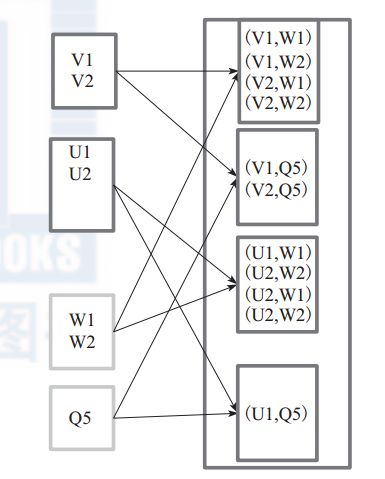
6. cartesian
对两个RDD内得所有数据进行笛卡尔积运算,也就是一个RDD内得任何元素与另一个RDD内的任何元素进行运算,如(1,2,3),(4,5,6),笛卡儿积之后: (14),(15),(16),(24),(25),(26),(34),(35),(36).
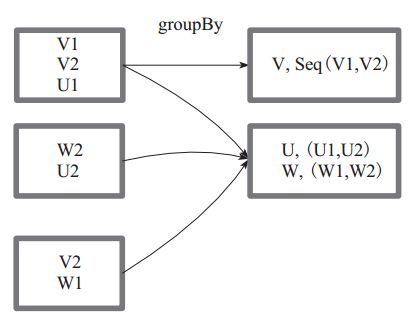
7.guoupBy
将RDD内的元素转换为Key,Value形式,元素相同的就是相同的key,再把元素相同的key分为一组
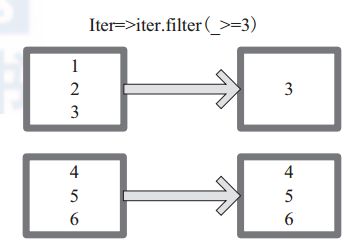
8.filter
通过提供的产生boolean条件的表达式来返回符合结果为True的新RDD

9.distinct
将RDD内的元素进行去重

10.subtract
类似两个RDD进行差运算,RDD1去除RDD1与RDD2共同的元素,得到一个新的RDD
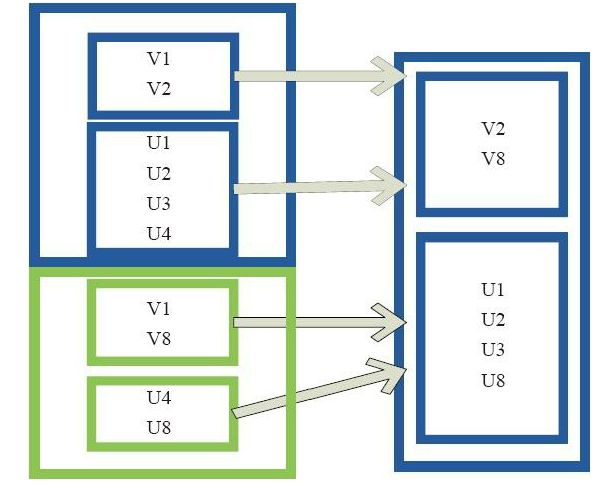
11.sample
sample 将 RDD 这个集合内的元素进行采样,获取所有元素的子集.用户可以设定是否有放回的抽样,百分比,随机种子,进而决定采样方式,内部实现是生成 SampledRDD(withReplacement, fraction, seed). withReplacement=true,表示有放回的抽样。false,表示无放回的抽样。
12.cache
通过cache将 RDD 元素从磁盘缓存到内存

13.mapValues
针对(Key, Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理.

14.reduceByKey
reduceByKey就是对RDD中Key相同的元素的Value进行合并操作,然后与原RDD中的Key组成一个新的KV对。

15.partitionBy
partitionBy函数对RDD进行分区操作; 如果原有RDD的分区器和现有分区器(partitioner)一致,则不重分区,如果不一致,则相当于根据分区器生成一个新的ShuffledRDD。
行动算子(10)
1.foreach
foreach 对 RDD 中的每个元素都应用 f 函数操作,不返回 RDD 和 Array,而是返回Uint,就是遍历.
2.saveAsTextFile
函数将数据输出,存储到 HDFS 的指定目录.下面为 saveAsTextFile 函数的内部实现,其内部
通过调用 saveAsHadoopFile 进行实现:
this.map(x => (NullWritable.get(), new Text(x.toString))).saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path)
将 RDD 中的每个元素映射转变为 (null, x.toString),然后再将其写入 HDFS。
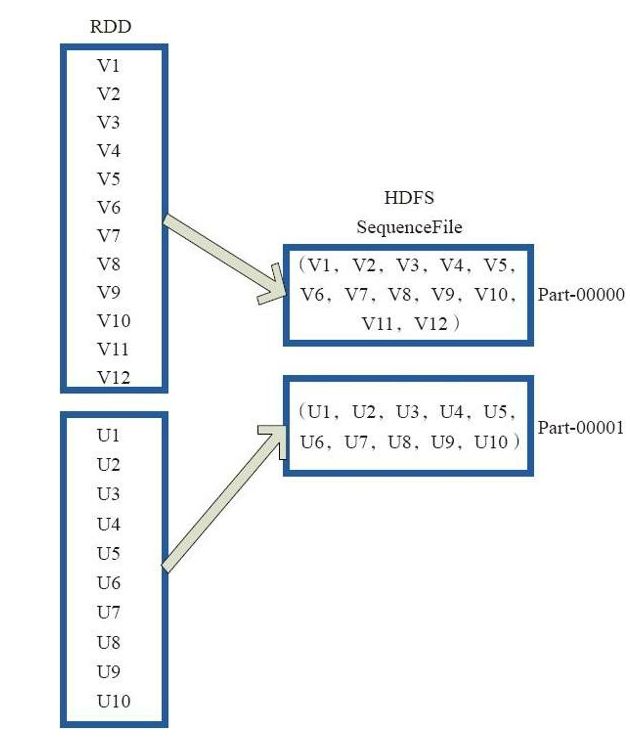
3.saveAsObjectFile
saveAsObjectFile将分区中的每10个元素组成一个Array,然后将这个Array序列化,映射为(Null,BytesWritable(Y))的元素,写入HDFS为SequenceFile的格式。
下面代码为函数内部实现。
map(x=>(NullWritable.get(),new BytesWritable(Utils.serialize(x)))
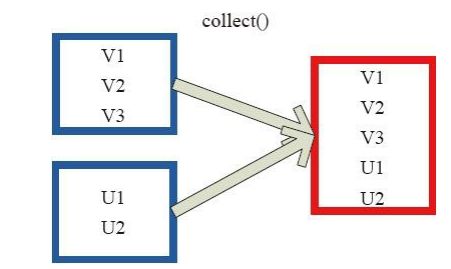
4.collect
collect 将数据集中所有的元素以Array形式返回。在这个数组上运用 scala 的函数式操作。
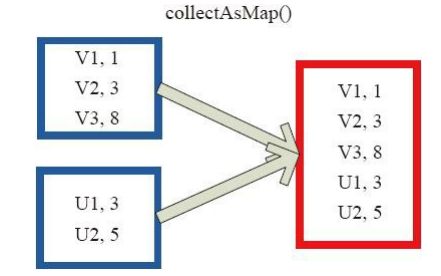
5.collectAsMap
collectAsMap对(K,V)型的RDD数据返回一个单机HashMap。 对于重复K的RDD元素,后面的元素覆盖前面的元素。
6.reduceByKeyLocally
实现的是先reduce再collectAsMap的功能,先对RDD的整体进行reduce操作,然后再收集所有结果返回为一个HashMap。
7.count
count 返回整个 RDD 的元素个数. 代码实现为:defcount():Long=sc.runJob(this,Utils.getIteratorSize_).sum

8.first
返回数据集中的第一个元素, 类似于take(1). 代码实现如下:
rdd1.first()
res10: Int = 1
9.task
Take(n)返回一个包含数据集中前n个元素的数组, 当前该操作不能并行。
代码实现如下: rdd1.take(3) res11: Array[Int] = Array(1, 2, 3)
10.reduce
reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止,比如累加.
比如 1 to10,然后从1+到10,一共等于55;