欢迎大家关注我的专题:爬虫修炼之道
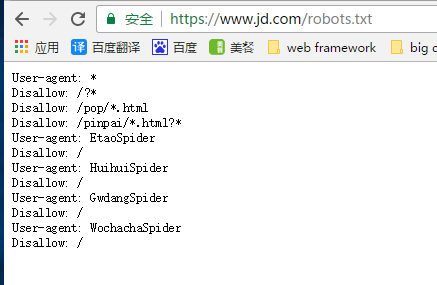
robots.txt
robots.txt 一般指robots协议,robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt文件一般都在网站的根目录,例如,京东的首页url为 https://www.jd.com,则robots.txt存放在 https://www.jd.com/robots.txt 。
sitemap(网站地图)
sitemap 可方便网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页。最简单的 Sitemap 形式,就是XML 文件,在其中列出网站中的网址以及关于每个网址的其他元数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度为何等),以便搜索引擎可以更加智能地抓取网站。
估算网站大小
如果要爬取一个网站时,我们首先需要了解该网站的大小是多少。我们可以使用 百度的高级搜索 或者 谷歌的高级搜索 来实现。
例如想要估算smzdm.com域名所包含的网页大小,我们可以在百度高级搜索的“站内搜索”输入框输入smzdm.com:

然后回车,得到如下页面:
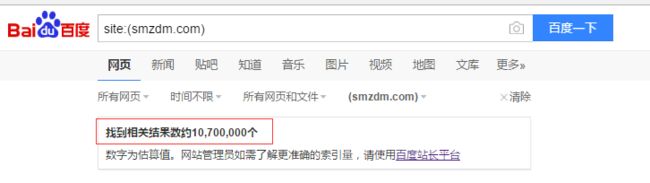
从图中可以看出,百度估算该网站拥有10,700,000个网页。
如果我们想要得到指定于域名下特定条件的筛选结果,只需将URL拼接起来就可以了,比如想要得到smzdm.com/p网页的个数,这儿我们使用百度高级搜索来搜索,发现没有得到结果:

改用谷歌高级搜索来实现:
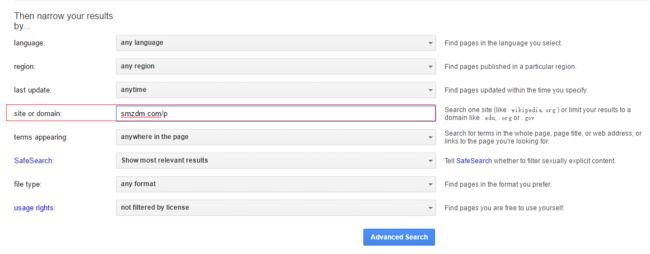
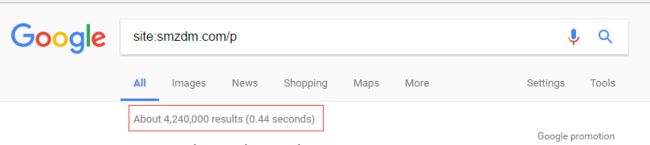
回车得到结果:
识别网站所用技术
构建网站时采用的技术会对我们之后如何进行爬取数据产生影响,python有一个可以查看网站构建的技术类型的模块——builtwith 。安装方法如下:
pip install builtwith
使用方法如下:
In [1]: import builtwith
In [2]: builtwith.builtwith("http://www.smzdm.com/")
Out[2]:
{u'advertising-networks': [u'DoubleClick for Publishers (DFP)'],
u'tag-managers': [u'Google Tag Manager']}
此外,也可以使用 wappalyzer 工具来进行分析。该工具可以作为chrome或firefox的插件使用。下图为将该工具安装在chrome之后检测“http://www.smzdm.com”使用技术的结果:

可以看出,使用wappalyzer插件得到的结果比python的builtwith模块得到的结果更详细。
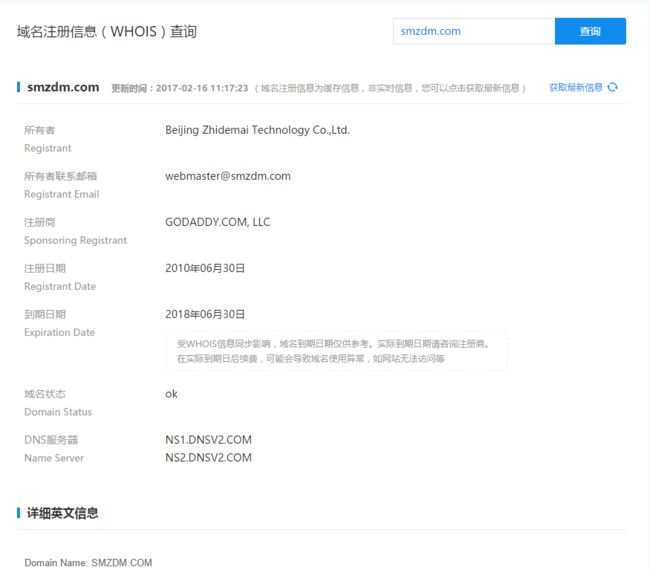
寻找网站所有者
有时候我们可能需要得到某个网站的所有者,python有一个可以查看whois的模块——python-whois 。
pip install python-whois
使用方法如下:
In [13]: import whois
In [14]: print whois.whois("smzdm.com")
{
"updated_date": "2017-02-09 00:00:00",
"status": [
"ok https://icann.org/epp#ok",
"ok http://www.icann.org/epp#ok"
],
"name": "guodong sui",
"dnssec": "unsigned",
"city": "beijing",
"expiration_date": [
"2018-06-30 00:00:00",
"2018-06-30 07:49:04"
],
"zipcode": "100000",
"domain_name": "SMZDM.COM",
"country": "CN",
"whois_server": "whois.godaddy.com",
"state": "Beijing",
"registrar": "GoDaddy.com, LLC",
"referral_url": "http://www.godaddy.com",
"address": "fengtaiqu",
"name_servers": [
"NS1.DNSV2.COM",
"NS2.DNSV2.COM"
],
"org": "Beijing Zhidemai Technology Co.,Ltd.",
"creation_date": [
"2010-06-30 00:00:00",
"2010-06-30 07:49:04"
],
"emails": [
"[email protected]",
"[email protected]"
]
}
此外,还可以使用一些在线whois查询,例如,百度云的 域名注册信息查询 。下图为使用该工具查询“smzdm.com”域名的注册信息:
下篇我们将讲解如何使用python来下载一个页面:爬虫修炼之道——编写一个爬取单页面的网络爬虫
欢迎大家关注我的专题:爬虫修炼之道