在工作中遇到部门间数据合作,需跨不同版本集群拷贝数据,从hadoop 2.6.0-cdh5.7.0 拷贝数据到hadoop 2.7.1, 记录所碰到的问题及解决方案。
distcp基础用法
比如拷贝A集群(src集群)的A1目录到B集群(dest集群)的B1目录,
1.同版本集群拷贝(hdfs协议):
在dest集群(目标集群)运行命令:
hadoop distcp hdfs://10.190.11.303:3333/user/common/liming/A1/ hdfs://10.120.20.22/user/zhangsan/B1/
其中10.190.11.303是src集群的namenode地址, 3333是src集群的rpc端口(hdfs-site.xml中可查看)。10.120.20.22是dest集群的namenode IP地址
2.跨集群版本拷贝(hftp协议):
同样在dest集群(目标集群)运行命令:
hadoop distcp hftp://10.190.11.303:50070/user/common/liming/A1/ hdfs://10.120.20.22/user/zhangsan/B1/
类似hdfs,但是目标集群的开头要用hftp, 而且端口要变为http端口(hdfs-site.xml中可查看,如果未配置,则需要配置)。
注意:如果集群间版本跨度不大,比如hadoop 2.6.0和hadoop2.7.0则也可以使用hdfs协议。
问题一:Java.net.SocketTimeoutException: connect timed out
原因分析:日志显示连接超时, 我们用的是hftp协议拷贝,需要连接src集群10.190.11.303 的50070端口,而此时连接超时,说明相关权限未开通。
解决办法:联系运维开通dest集群到src集群所有namenode 的50070端口的防火墙。如果防火墙开通了,还是出现此问题,可以修改src集群的iptables,将dest集群的所有机器加入iptables。
问题二: org.apache.hadoop.ipc.StandbyException : //s.apache.org/sbnn-error
原因分析:搜索"s.apache.org/sbnn-error", 发现它是个网站,顺便访问了一下“ http://s.apache.org/sbnn-error ” , 自动跳转到apache的wiki页面, 显示:
3.17. What does the message "Operation category READ/WRITE is not supported in state standby" mean?
In an HA-enabled cluster, DFS clients cannot know in advance which namenode is active at a given time. So when a client contacts a namenode and it happens to be the standby, the READ or WRITE operation will be refused and this message is logged. The client will then automatically contact the other namenode and try the operation again. As long as there is one active and one standby namenode in the cluster, this message can be safely ignored.
大意是说,DFS的客户端不知道哪一个namenode是活跃(active)的,所以当客户端连接一个备用的(standby)namenode时,读或写操作会被拒绝,所以打出这个日志。客户端会自动连接另一个namenode,重新操作。
但事实上,在我们这并没有自动连接另一个namenode,我也不知道为什么。
解决办法:换一个namenode, 保证新的namenode是活跃的。即用 hadoop distcp hftp://活跃的namenode:50070/path ....
问题三:java.net.UnknowHostException
原因分析:图中可以看到,distcp job已经启动了,map 0%, 但是报了UnknowHostException:pslaves55,可能的原因是在从datanode取数据时,用的是host pslave55, 而这个host是src集群特有的,dest集群不识别,所以报UnknowHostException.
解决办法:在dest集群中配置hosts文件,将src集群中所有的host和ip的对应关系追加到dest集群中的hosts文件中,使得dest集群在访问host名时(如pslave55)能自动映射到ip。
问题四: map 100%之后连接超时Java.net.SocketTimeoutException: connect timed out
错误的分析:map 100% 完成了,说明数据读取完毕,但是没有写进目标集群,说明写目标集群有问题。
正确分析:由于在网上没找到相关资料,我下载了hadoop源码, 查看了RetriableFileCopyCommand.java的源码,报错的位置是302行,如下图。

继续查看代码,getInputStream方法中有可能报连接超时的就是fs.open(path)这一行代码。继续研究相关源码,以及在源码中增加调试信息,运行得知,该文件系统fs已经初始化完毕,正是HftpFileSystem,其他的变量,如path等均正确。所以是文件系统open src集群上的文件时连接超时,还有相关的端口没有打开。
在执行distcp时,用tcpdump 抓取实际运行map的机器到src集群 host的tcp连接情况,如下图,也能发现数据length =0 , 没有真正的拷贝数据。

解决方案:开通dest集群到src集群所有datanode的http相关端口(默认为50075)。
(在本次项目中,我们误打误撞开通了dest集群到src集群所有datanode的控制端口50010, 然后运行hdfs协议就能跨集群版本拷贝数据了,所以没有再开通50075端口。)
问题五: java.io.IOException:Check-sum mismatch
分析:该问题很常见,能在网上查到,是因为不同版本hadoop 的checksum版本不同,老版本用crc32,新版本用crc32c。
When we run distcp between source and destination clusters with different versions, we may get the below exception. This is because, distcp using MRV2(YARN) from older version to newer version, may fail with these checksum error messages. Each hadoop versions use different checksum versions. Older one uses CRC32 and newer versions use CRC32C.
来自:http://www.catchdba.com/2014/03/18/distcp-between-two-different-versions-of-hadoop/
解决办法:只要在distcp时增加两个参数(-skipcrccheck -update),忽略crc检查即可。注意-skipcrccheck参数要与-update同时使用才生效。
总结
要实现跨集群拷贝,如拷贝src集群的数据到dest集群,需要确认以下事情:
(1)确认dest集群机器都能ping通src集群所有ip。
(2)按需开通如下端口的防火墙,如使用hdfs协议需要开通1,2项;如使用hftp协议至少需要开通1,3,4项。
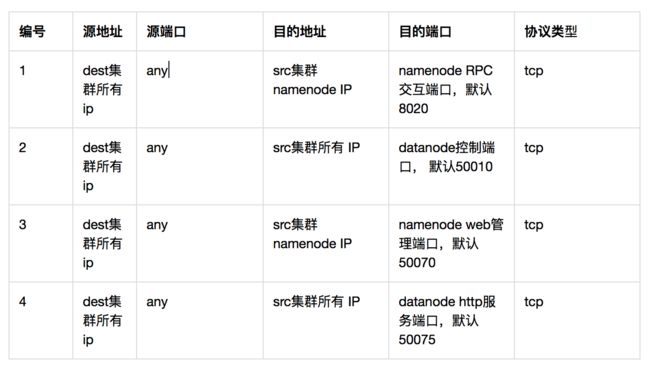
(3)如果部门间的端口防火墙已经开通,但还是telnet不同,请确认src集群的iptables已经加入了dest集群ip。
(4)如果在dest集群有UnknowHostException,则需要将src集群的host与ip映射关系追加到dest集群的hosts文件中。
(5)如果出现org.apache.hadoop.ipc.StandbyException, 换一个活跃的namenode试一试。
完。
附:常用HDFS端口配置

参考网页:
distcp 官方文档:https://hadoop.apache.org/docs/r1.0.4/cn/distcp.html , https://hadoop.apache.org/docs/r1.2.1/distcp.html
hdfs端口配置: http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html