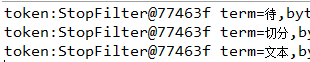
比较不同分词器的分词结果:
- CJKAnalyzer二元覆盖的方式分词
Analyzer analyzer=new CJKAnalyzer();
TokenStream tokenStream=analyzer.tokenStream("myfiled", new StringReader("待切分文本"));
tokenStream.reset();
while(tokenStream.incrementToken()){
//取得下一个分词
System.out.println("token:"+tokenStream);
}
analyzer.close();
结果:
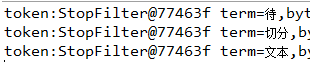
- SmartChineseAnalyzer
Analyzer analyzer=new SmartChineseAnalyzer();
TokenStream tokenStream=analyzer.tokenStream("myfiled", new StringReader("待切分文本"));
tokenStream.reset();
while(tokenStream.incrementToken()){
//取得下一个分词
System.out.println("token:"+tokenStream);
}
analyzer.close();
结果:
- StandardAnalyzer单字切分
Analyzer analyzer=new StandardAnalyzer();
TokenStream tokenStream=analyzer.tokenStream("myfiled", new StringReader("待切分文本"));
tokenStream.reset();
while(tokenStream.incrementToken()){
//取得下一个分词
System.out.println("token:"+tokenStream);
}
analyzer.close();
结果:

自己动手写Analyzer
由于6.1.0版本相比于以前有很多改动,参照[1]中p148的例子,以及结合lucene6.1.0的文档,写一个简单的分词器例子。
文档里面说,构建一个自己的分词器是非常简单的(I doubt that!),自己构建的分词器要继承Analyzer类,并且可以用现存的analysis components——CharFilter(可选),一个Tokenizer,以及TokenFilter(可选)——或者使用自己构建的组建,或者是混合来用。
- 一个Whitespace tokenization的例子
参照文档里面的一个例子(例子里面还用到了Version,但是在6.1.0里面似乎都已经摒弃这个了,所以就直接将其删掉):
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.WhitespaceTokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class MyAnalyzer extends Analyzer {
public MyAnalyzer(){}
@Override
protected TokenStreamComponents createComponents(String fieldName) {
return new TokenStreamComponents(new WhitespaceTokenizer());
}
public static void main(String[] args) throws IOException {
// text to tokenize
final String text = "This is a demo of the TokenStream API";
MyAnalyzer analyzer = new MyAnalyzer();
TokenStream stream
= analyzer.tokenStream("field", new StringReader(text));
// get the CharTermAttribute from the TokenStream
CharTermAttribute termAtt
= stream.addAttribute(CharTermAttribute.class);
try {
stream.reset();
// print all tokens until stream is exhausted
while (stream.incrementToken()) {
System.out.println(termAtt.toString());
}
stream.end();
} finally {
stream.close();
}
}
}
MyAnalyzer类是Analyzer的子类,实现了createComponents方法,然后在主方法中,对stream进行循环,通过WhitesSpaceTokenizer中提供的CharTermAttirbute,打印出token中的term text
(这段话原文:
In main() a loop consumes the stream and prints the term text of the tokens by accessing the CharTermAttribute that the WhitespaceTokenizer provides.)。
Tokenizer的子类需要重写incrementToken方法,通过incrementToken方法遍历Tokenizer分析出的词,当还有词可以获取时,返回true;已经遍历到结尾时,返回false。
上面应该是基于属性的方法(CharTermAttribute),将无用的词特征和想要的词特征分隔开。每个TokenStream在构造时,增加它想要的属性。在TokenStream的整个生命周期中都保留一个属性的引用。这样在获取所有和TokenStream实例相关的属性时,可以保证属性的类型安全。
上面代码得到的结果是:

- 添加LengthFilter:
如果我们需要去除长度小于等于2的tokens,我们可以通过添加LengthFilter来实现,只需要对createComponets()方法做一些改动:
protected TokenStreamComponents createComponents(String fieldName) {
final Tokenizer source=new WhitespaceTokenizer();
TokenStream result=new LengthFilter(source, 3,Integer.MAX_VALUE);
return new TokenStreamComponents(source,result);
}
结果如下:
看一下LengthFilter类的源码:
public final class LengthFilter extends FilteringTokenFilter {
private final int min;
private final int max;
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
public LengthFilter(TokenStream in, int min, int max) {
super(in);
if (min < 0) {
throw new IllegalArgumentException("minimum length must be greater than or equal to zero");
}
if (min > max) {
throw new IllegalArgumentException("maximum length must not be greater than minimum length");
}
this.min = min;
this.max = max;
}
@Override
public boolean accept() {
final int len = termAtt.length();
return (len >= min && len <= max);
}
}
可以看到在LengthFilter类里面,CharTermAttribute被添加以及存储到termAtt实例中,因为只能存在一个CharTermAtribute的实例(in the chain,这里的chain应该是说TokenStream的生命周期中),所以例子中的addAttribute()方法引用的就是LengthFilter返回的已经存在的CharTermAttribute。
通过查看在CharTermAttribute中的term text,去除掉过长或者过短的tokens。(CharTermAttribute就是对应Token中的词)
添加custom Attribute(自己定制一个Attribute)
定义一个part-of-speech tagging(词性标注)的Attribute,名为PartOfSpeechAttribute,首先需要为这个Attribute定义接口:
import org.apache.lucene.util.Attribute;
public interface PartOfSpeechAttribute extends Attribute {
public static enum PartOfSpeech {
Noun, Verb, Adjective, Adverb, Pronoun, Preposition, Conjunction, Article, Unknown
}
public void setPartOfSpeech(PartOfSpeech pos);
public PartOfSpeech getPartOfSpeech();
}
然后写一个实现类,值得注意的是,在Lucene中,会默认检查一个Attribute的名字是否有后缀Impl,所以我们在这里实现类的名字为PartOfSpeechAttributeImpl。
当然也可以实现AttributeFactory,这个工厂类接收Atrribute的接口作为参数,然后返回一个实例。
import org.apache.lucene.util.AttributeImpl;
import org.apache.lucene.util.AttributeReflector;
public final class PartOfSpeechAttributeImpl extends AttributeImpl implements PartOfSpeechAttribute{
private PartOfSpeech pos=PartOfSpeech.Unknown;
@Override
public void setPartOfSpeech(PartOfSpeech pos) {
this.pos=pos;
}
@Override
public PartOfSpeech getPartOfSpeech() {
return pos;
}
@Override
public void clear() {
pos=PartOfSpeech.Unknown;
}
@Override
public void reflectWith(AttributeReflector reflector) {
}
@Override
public void copyTo(AttributeImpl target) {
((PartOfSpeechAttribute)target).setPartOfSpeech(pos);
}
}
上面这个类只存在一个变量,用来存储词性的token,它继承了AttributeImpl类并实现了里面的抽象方法。现在我们需要一个TokenFilter(Token过滤器),在这个例子中,我们设置一个很简单的filter:如果一个单词的首字母是大写,则标记为‘Noun’,其他标记为‘Unknown’.
import java.io.IOException;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class PartOfSpeechTaggingFilter extends TokenFilter {
PartOfSpeechAttribute posAtt
= addAttribute(PartOfSpeechAttribute.class);
CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
protected PartOfSpeechTaggingFilter(TokenStream input) {
super(input);
}
public boolean incrementToken() throws IOException {
if (!input.incrementToken()) {return false;}
posAtt.setPartOfSpeech(
determinePOS(termAtt.buffer(), 0, termAtt.length()));
return true;
}
// determine the part of speech for the given term
protected PartOfSpeechAttribute.PartOfSpeech
determinePOS(char[] term, int offset, int length) {
// naive implementation that tags every uppercased word as noun
if (length > 0 && Character.isUpperCase(term[0])) {
return PartOfSpeechAttribute.PartOfSpeech.Noun;
}
return PartOfSpeechAttribute.PartOfSpeech.Unknown;
}
}
下面将这个filter运用到the chain in MyAnalyzer,同样是修改createComponents()方法:
protected TokenStreamComponents createComponents(String fieldName) {
final Tokenizer source=new WhitespaceTokenizer();
TokenStream result=new LengthFilter(source, 3,Integer.MAX_VALUE);
result=new PartOfSpeechTaggingFilter(result);
return new TokenStreamComponents(source,result);
}
得到的结果如下:

似乎跟之前相比没有改变。这表明了在TokenStream/Filter chain添加一个定制的attribute不会影响已经存在的consumers(TokenStream是生产者,产生Token,生成词索引程序的是消费者,调用TokenStream的increamentToken()方法得到一个Token),这是因为他们并不知道新的Attribute。现在需要让consumer来运用PartOfSpeechAttribute来打印:
public static void main(String[] args) throws IOException {
// text to tokenize
final String text = "This is a demo of the TokenStream API";
MyAnalyzer analyzer = new MyAnalyzer();
TokenStream stream
= analyzer.tokenStream("field", new StringReader(text));
// get the CharTermAttribute from the TokenStream
CharTermAttribute termAtt
= stream.addAttribute(CharTermAttribute.class);
//get the PartOfSpeechAttribute from TokenStream
PartOfSpeechAttribute posAtt
= stream.addAttribute(PartOfSpeechAttribute.class);
try {
stream.reset();
// print all tokens until stream is exhausted
while (stream.incrementToken()) {
System.out.println(termAtt.toString()+":"
+posAtt.getPartOfSpeech());
}
stream.end();
} finally {
stream.close();
}
}
得到的结果如下:

每个词都被标注上了PartOfSpeech的标签。
参考文献:
[1]罗刚. 解密搜索引擎技术实战--LUCENE & JAVA精华版(第3版)[M]. 电子工业出版社, 2016.