【自然语言处理(NLP)】NLTK的使用(分句、分词、词频提取)
文章目录
- 介绍
- NLTK
-
- 主要功能模块
- 安装
- 使用
-
- 分句
- 分词
- 去除标点符号
- 去除停用词 stopword 噪音单词,
- 词频提取
个人主页:道友老李
欢迎加入社区:道友老李的学习社区
介绍
自然语言处理(Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究的是人类(自然)语言与计算机之间的交互。NLP的目标是让计算机能够理解、解析、生成人类语言,并且能够以有意义的方式回应和操作这些信息。
NLP的任务可以分为多个层次,包括但不限于:
- 词法分析:将文本分解成单词或标记(token),并识别它们的词性(如名词、动词等)。
- 句法分析:分析句子结构,理解句子中词语的关系,比如主语、谓语、宾语等。
- 语义分析:试图理解句子的实际含义,超越字面意义,捕捉隐含的信息。
- 语用分析:考虑上下文和对话背景,理解话语在特定情境下的使用目的。
- 情感分析:检测文本中表达的情感倾向,例如正面、负面或中立。
- 机器翻译:将一种自然语言转换为另一种自然语言。
- 问答系统:构建可以回答用户问题的系统。
- 文本摘要:从大量文本中提取关键信息,生成简短的摘要。
- 命名实体识别(NER):识别文本中提到的特定实体,如人名、地名、组织名等。
- 语音识别:将人类的语音转换为计算机可读的文字格式。
NLP技术的发展依赖于算法的进步、计算能力的提升以及大规模标注数据集的可用性。近年来,深度学习方法,特别是基于神经网络的语言模型,如BERT、GPT系列等,在许多NLP任务上取得了显著的成功。随着技术的进步,NLP正在被应用到越来越多的领域,包括客户服务、智能搜索、内容推荐、医疗健康等。
NLTK
NLTK全称是Natural Language Toolkit(自然语言处理工具包),它是一个用于构建处理人类语言数据的Python程序的领先平台。NLTK提供了简单易用的接口以及丰富的工具和资源,广泛应用于文本处理、信息检索、情感分析、机器翻译等众多自然语言处理(NLP)任务中。
主要功能模块
- 语料库(Corpora)
- NLTK包含了大量的语料库,这些语料库涵盖了多种语言和文本类型。例如,古腾堡语料库(Project Gutenberg Corpus)包含了许多经典文学作品的文本。通过这些语料库,研究人员可以获取大量的文本数据用于训练模型、进行语言分析等。
- 像布朗语料库(Brown Corpus)是第一个百万词级的英语语料库,它被标注了词性等信息,有助于研究英语的词汇、语法和语义等方面的规律。
- 词汇资源(Lexical Resources)
- 提供了如词汇表、同义词集等资源。WordNet是NLTK中一个重要的词汇数据库,它将英语单词按照语义关系组织起来,包括同义词、反义词、上位词(hypernyms)和下位词(hyponyms)等关系。例如,“car”(汽车)的上位词可能是“vehicle”(交通工具),它的同义词可能有“automobile”“motor vehicle”等。这种词汇资源对于词义消歧、文本生成等任务非常有帮助。
- 分类器(Classifiers)
- NLTK支持多种分类算法,用于文本分类任务。例如,可以使用朴素贝叶斯分类器来进行垃圾邮件过滤。先从大量的已标记为垃圾邮件和非垃圾邮件的文本中提取特征(如单词频率等),然后利用朴素贝叶斯分类器进行训练。在对新邮件进行分类时,根据邮件中的单词特征,通过训练好的分类器判断它是否为垃圾邮件。
- 标记器(Tokenizers)
- 用于将文本分割成单词、句子等单元,也就是标记(tokens)。例如,单词标记器(word tokenizer)可以将句子“This is a sample sentence.”分割成“This”“is”“a”“sample”“sentence”这些单词。句子标记器(sentence tokenizer)则可以将一段文本分割成一个个句子,这是文本预处理中非常重要的一步,为后续的词性标注、语法分析等任务打下基础。
- 词性标注器(Part - of - Speech Taggers)
- 能够为文本中的单词标注词性,如名词、动词、形容词等。例如,对于句子“The dog runs fast.”,词性标注器可以标注出“The”为冠词(DT),“dog”为名词(NN),“runs”为动词(VBZ),“fast”为副词(RB)。这些标注信息对于理解句子的语法结构和语义非常有帮助,并且可以用于文本生成、语法检查等应用。
- 命名实体识别(Named Entity Recognition)
- 用于识别文本中的人名、地名、组织机构名等命名实体。例如,在句子“Barack Obama visited China.”中,它能够识别出“Barack Obama”是人名,“China”是地名。这在信息提取、问答系统等领域有重要的应用,比如从新闻文章中提取关键人物和地点信息。
安装
- 可以通过Python的包管理工具pip来安装NLTK。在命令行中输入“pip install nltk”即可安装。安装完成后,还需要下载相关的语料库和其他资源。例如,在Python脚本中可以使用“nltk.download()”命令打开NLTK下载器,从中选择需要的语料库、模型等资源进行下载。
使用
分句
import nltk
nltk.download('punkt_tab')
from nltk.tokenize import sent_tokenize
paragraph = 'You must follow me carefully. I shall have to controvert one or twoideas that are almost universally accepted. The geometry, forinstance, they taught you at school is founded on a misconception.'
tokenized_text = sent_tokenize(paragraph)
tokenized_text
['You must follow me carefully.',
'I shall have to controvert one or twoideas that are almost universally accepted.',
'The geometry, forinstance, they taught you at school is founded on a misconception.']
分词
# 分词
from nltk import word_tokenize
text = 'You must follow me carefully.'
tokenized_text = word_tokenize(text)
['You', 'must', 'follow', 'me', 'carefully', '.']
去除标点符号
方法一:
import string
string.punctuation
text.translate(str.maketrans(string.punctuation, ' ' * len(string.punctuation)))
'You must follow me carefully '
方法二:对tokenized_text过滤
punctuation = list(string.punctuation)
[word for word in tokenized_text if word not in punctuation]
['You', 'must', 'follow', 'me', 'carefully']
去除停用词 stopword 噪音单词,
没有意义, 常用英文停用词: is, am, a, are the, an, to , for…
nltk.download('stopwords')
from nltk.corpus import stopwords
# 加载英文停用词
stop_words = stopwords.words('english')
text = 'I shall have to controvert one or twoideas that are almost universally accepted.'
tokenized_text = word_tokenize(text)
tokenized_text
# 过滤标点
tokenized_text = [word for word in tokenized_text if word not in punctuation]
tokenized_text
# 过滤停用词
tokenized_text = [word for word in tokenized_text if word not in stop_words]
tokenized_text
词频提取
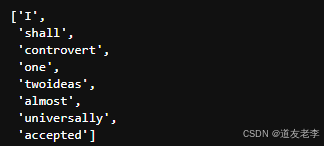
tokenized_text = nltk.word_tokenize(paragraph)
tokenized_text = [word for word in tokenized_text if word not in punctuation]
tokenized_text
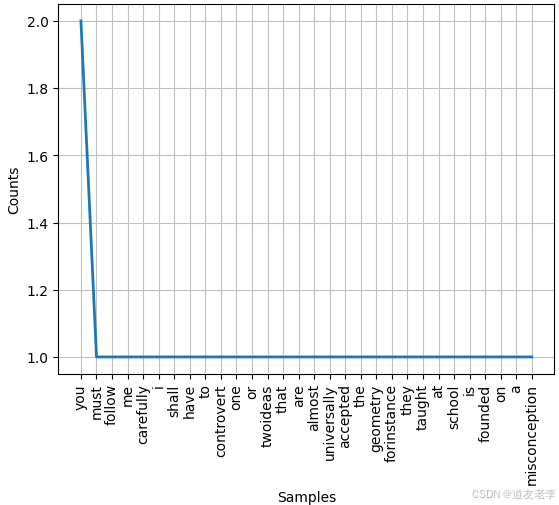
word_freqs = nltk.FreqDist(w.lower() for w in tokenized_text)
# 画出词频
word_freqs.plot()
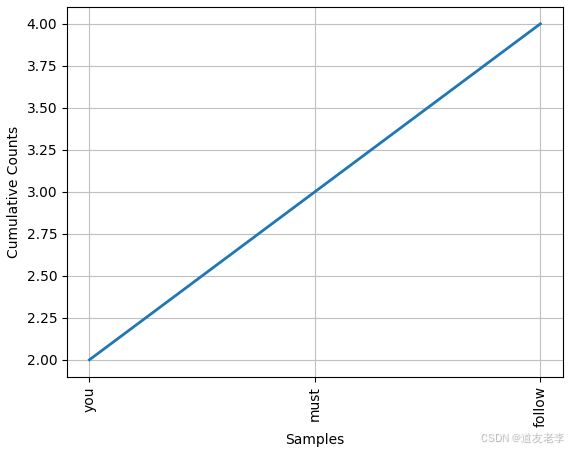
出现频率最高的几个词.
# 出现频率最高的几个词.
word_freqs.plot(3, cumulative=True)