我不想写一篇大而全的文章,也无力去查找那么多资料涵盖所有知识点,如果想了解更多信息,这里有几篇我认为写得不错的文章可以提供参考,本文也部分借鉴了其中的内容。
- 《字符编码的故事:ASCII,GB2312,Unicode,UTF-8,UTF-16》
- 《unicode,ansi,utf-8,unicodebigendian编码的区别》
基础概念
- 字符
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,甚至还可以包括无法显示的字符(比如ASCII标准定义了128个字符,其中33个字符无法显示)。 - 字符集
为了使计算机能够处理字符信息,首先要决定选取哪些字符。这样就形成了一个集合,或者说一个表,称为字符表(character repertoire)。当然,也可以认为这就是一个字符集(character set)。
例如,将所有的英文字母放在一起可以组成一个字符集,将所有的汉字放在一起可以组成一个字符集,等等。 - 编码字符集
对一个字符集中的所有字符进行编号,这种编号后的字符集叫做编码字符集(这里的编码仅仅指编号,不同于下文中的编码)。常见的编码字符集有ASCII、Unicode、GBK等。
可以这样来理解:字符串是由字符构成,字符在计算机硬件中通过二进制形式存储,这种二进制形式就是编码。如果直接使用 “字符串️字符️二进制表示(编码)” ,会增加不同类型编码之间转换的复杂性。所以引入了一个抽象层,“字符串️字符️与存储无关的表示️二进制表示(编码)” ,这样就可以用一种与存储无关的形式表示字符,不同的编码之间转换时可以先转换到这个抽象层,然后再转换为其他编码形式。
举个例子:Unicode 就是 “与存储无关的表示”,UTF-8 就是 “二进制表示”。
ASCII字符集
通常说的ASCII字符集不包括扩展集,只有128个字符,因此其编码的存储只需要使用7个bit,一个字节足够了最高位永远都是0。比如字符'0',其代码是十六进制的0x30,二进制表示为00110000。
这里说个和ASCII字符集有关的编码方案,GSM标准协议规定单条短信最多存储140个字节的内容,如果短信内容只包含ASCII字符,因为ASCII字符的数据首位必定是0,所以GSM标准中规定了7bit编码的短信格式,只用7个bit来连续存储ASCII字符,这样原本140个8bit的存储空间,就可以存储160个7bit的数据。如果谁现在手上还有NOKIA手机,可以拿起来看看只包含ASCII字符的短信是不是可以输入160个字符,如果短信中包含了非ASCII字符(比如中文),那么所有字符都会变成双字节存储的编码(UCS-2编码),一条短信的内容就恢复成只能发送70个字符。现如今的智能手机大多都支持短信拼接,并不是说单条短信的容量增加了,而是将你编写的超过单条短信容量的短信分成多条发送,运营商也是按多条短信计的。
GB系列字符集
中文环境下如果要正常显示字符,仅依靠ASCII字符集是不行的,因此我们国家制订了一系列的国标(GB),其中就包括GB2312、GB13000、GBK、GB18030......,最新的标准是GB18030,包含70244个字符。
Unicode字符集
Unicode字符集由多语言软件制造商组成的统一码联盟(Unicode Consortium)与国际标准化组织的ISO-10646工作组制订,为各种语言中的每个字符指定统一且唯一的代码点,以满足跨语言、跨平台转换和处理文本的要求。中、日、韩的三种文字占用了Unicode中0x3000到0x9FFF的部分 Unicode目前普遍采用的是UCS-2编码,它用两个字节来编码一个字符, 比如汉字"一"的编码是0x4E00。事实上Unicode对汉字支持不怎么好,这也是没办法的,简体和繁体总共有六七万个汉字,而UCS-2最多能表示65536个,所以Unicode只能排除一些几乎不用的汉字,好在GB2312字符集中常用的简体汉字也不过6763个,为了能表示所有汉字,Unicode也有UCS-4规范,就是用 4个字节来编码字符。
Unicode代码点范围为0x00x10FFFF,共计1114112个代码点,划分为编号016的17个字符平面,每个平面包含65536个代码点。其中编号为0的平面最为常用,称为基本多语种平面(Basic Multilingual Plane, BMP);其他平面则称为辅助语言平面。
为了描述一个代码点,可以采用U加十六进制整数的方法。比如,U+0041表示英文大写字母A,U+4E00表示汉字”一”。
编码
关于编码方式,当然可以采用类似ASCII字符集的编码方式——代码点等值转换法(这是我自己起的名字)。既然Unicode代码点的值的范围是0~0x10FFF,那么可以用一个21bit的编码单元来编码,直接把代码点等值转换成21bit的二进制序列。
但是这存在一个空间使用的问题,例如对于使用英语的人而言,ASCII基本可以满足使用。如果使用ASCII码,只需要1个字节来存储字符,但是若使用刚才的思路,需要将近3个字节来存储,这显然是浪费空间的。
如果需要支持的字符集再少一些,仅支持编号0的平面,那至少也有65535个字符,需要16bit的空间(2字节)来存储一个字符,即UCS-2编码,这种编码用来存储ASCII字符也是一种浪费。
Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。UTF-8就是在互联网上使用最广的一种Unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII 码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是Unicode一个中文字符占2个字节,而UTF-8一个中 文字符占3个字节)。从Unicode到UTF-8并不是直接的对应,而是要过一些算法和规则来转换。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
举个例子:
还是用中文“一”,其Unicode值为0x4E00,落在0800-FFFF的范围内,事实上中文基本上都在这个区域。0x4E00的二进制表示为01001110 00000000,转换成UTF-8就是11100100 10111000 10000000,对应的十六进制表示是0xE4 0xB8 0x80。
UTF-16
UTF-16的编码单元是16bit,对于每个代码点,采用1个或者2个编码单元来表示,因此这是一个变长表示。
UTF-32
UTF-32采用代码点等值转换法,将每个代码点编码为1个32bit的编码单元(四字节),因此空间效率较低,不如其它Unicode编码应用广泛。
工具推荐
这里有个网站提供的转码效果非常好,比起某些站长工具更标准。
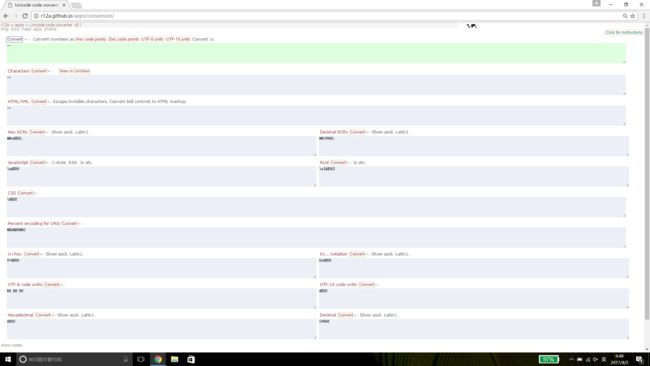
上图是使用该网站查找中文字符“一”的结果,可以看到其Unicode值为U+4E00,UTF-8编码为0xE4 0xB8 0x80,在URL中需要转码为%E4%B8%80,在js脚本中则是\u4e00......。
举几个栗子
有道翻译
用有道翻译的API来做演示,我们通过API获取单词"word"的中文翻译。
GET http://fanyi.youdao.com/openapi.do?keyfrom=WoxLauncher&key=1247918016&type=data&doctype=json&version=1.1&q=word
返回的JSON如下所示:
{
"translation": [
"词"
],
"basic": {
"us-phonetic": "wɝd",
"phonetic": "wɜːd",
"uk-phonetic": "wɜːd",
"explains": [
"n. [语] 单词;话语;消息;诺言;命令",
"vt. 用言辞表达",
"n. (Word)人名;(英)沃德"
]
},
"query": "word",
"errorCode": 0,
"web": [
{
"value": [
"单词",
"字",
"字 (计算机)"
],
"key": "word"
},
{
"value": [
"构词法",
"造词法",
"词性转换"
],
"key": "Word Formation"
},
{
"value": [
"关键字",
"中心词",
"关键词"
],
"key": "key word"
}
]
}
返回的内容包含中文,从响应头我们可以看到返回的JSON使用了UTF-8编码:

用Wireshark抓包看看具体内容:
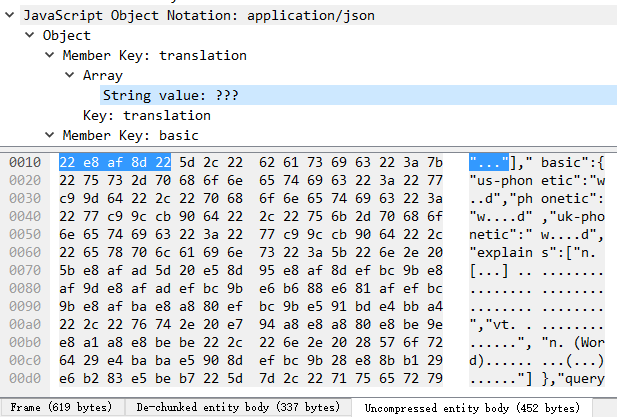
如上图所示,translation这个key对应的数组内容应该是"词",所以我们看到高亮区域的内容是22 E8 AF 8D 22,0x22对应ASCII字符",0xE8 0xAF 0x8D正是中文词的UTF-8编码。
ONE·一个
这个API是通过抓包抓出来的,谁让他们不走https呢?
GET http://v3.wufazhuce.com:8000/api/reading/index
返回数据太多,仅截取一小段进行分析。
{
"res": 0,
"data": {
"essay": [
{
"content_id": "2176",
"hp_title": "软糖| “白日梦” _ 初夏的味道",
"hp_makettime": "2017-04-03 06:00:00",
"guide_word": "我们每周会选择一个主题,由七个作者绘制不同风格的短篇漫画,每天一幅。",
"start_video": "",
"author": [
{
"user_id": "7742828",
"user_name": "双麒_宋 ",
"desc": "因爱而画,美好的作品产生于最压抑的欲望。",
"wb_name": "",
"is_settled": "0",
"settled_type": "0",
"summary": "因爱而画,美好的作品产生于最压抑的欲望。",
"fans_total": "574",
"web_url": "http://image.wufazhuce.com/FoPpyeue8ajoRlZ4Fy39a56o4NO-"
}
],
......
}
......
}
返回的内容包含中文,但从响应头我们看不到返回的JSON使用了什么编码格式:
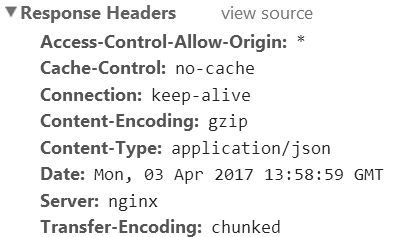
用Wireshark抓包看看具体内容:
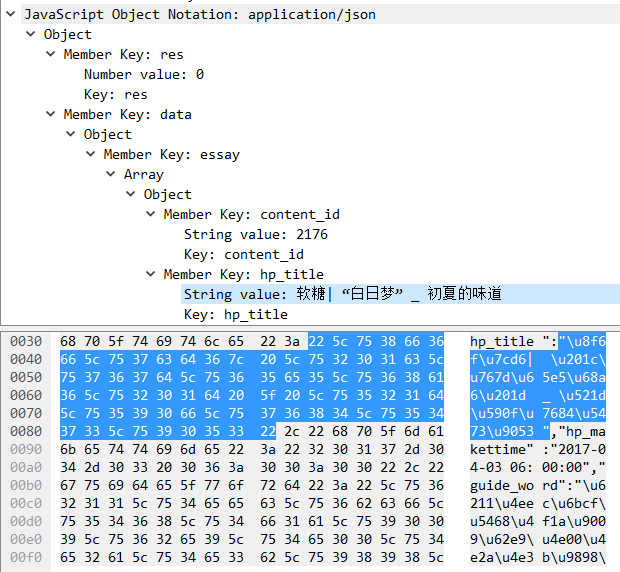
如上图所示,这个API请求返回的JSON数据输出的是中文的Unicode转义字符,这其实也是JS对中文的标准处理方式,猜测后台可能是NodeJS实现的。
我是咕咕鸡,一个还在不停学习的全栈工程师。
热爱生活,喜欢跑步,家庭是我不断向前进步的动力。