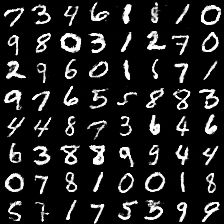补充
- Conditional Generative Adversarial Nets in TensorFlow
说明
Conditional GAN就是在GAN的基础上加了条件,在下面的代码中,使用cgan利用在mnist数据集上学习到的模型,生产手写数字图片,所加的条件就是指定的图片lable,用以控制生成器生成的数字
代码
代码分为三个文件:
- dcgan.py:程序入口,训练模型,保存训练过程
- ops.py:为DCGAN提供基础操作
- test.py:使用训练好的模型生成新的图片
cgan.py
# tensorflow 1.4 python 3.5
from tensorflow.examples.tutorials.mnist import input_data
from ops import *
import numpy as np
import os
# 如果当前文件夹中没有mnist数据,则会自动下载
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 使用独热编码,也就是标签是一个二维逻辑矩阵
train = mnist.train # train有两个属性:images: 55000*784 和 labels: 55000*10
global_step = tf.Variable(0, name='global_step', trainable=False)
y = tf.placeholder(tf.float32, [BATCH_SIZE, 10], name='y')
images = tf.placeholder(tf.float32, [BATCH_SIZE, 28, 28, 1], name='real_images')
z = tf.placeholder(tf.float32, [BATCH_SIZE, 100], name='z')
# G是生成的假图片
with tf.variable_scope(tf.get_variable_scope()) as scope:
G = generator(z, y)
D, D_logits = discriminator(images, y) # D、D_logits都是 BATCH_SIZE*1的
D_, D_logits_ = discriminator(G, y, reuse=True)
samples = sampler(z, y)
# 固定使用train.labels的前BATCH_SIZE个作为生成图片的标签,可以指定生成图片的数字
sample_labels = mnist.train.labels[0:BATCH_SIZE]
# 损失计算
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logits, labels=tf.ones_like(D)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logits_, labels=tf.zeros_like(D_)))
d_loss = d_loss_real + d_loss_fake
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logits_, labels=tf.ones_like(D_)))
# 生成器和判别器要更新的变量,用于 tf.train.Optimizer 的 var_list
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'd_' in var.name]
g_vars = [var for var in t_vars if 'g_' in var.name]
# 由于使用了tf.layers.batch_normalization,需要添加下面的两行代码
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
d_optim = tf.train.AdamOptimizer(0.0002, beta1=0.5).minimize(d_loss, var_list=d_vars, global_step=global_step)
g_optim = tf.train.AdamOptimizer(0.0002, beta1=0.5).minimize(g_loss, var_list=g_vars, global_step=global_step)
with tf.Session() as sess:
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for epoch in range(25):
for i in range(int(55000/BATCH_SIZE)):
batch = mnist.train.next_batch(BATCH_SIZE)
batch_images = np.array(batch[0]).reshape((-1, 28, 28, 1))
batch_labels = batch[1]
batch_z = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
sess.run([d_optim], feed_dict={images: batch_images, z: batch_z, y: batch_labels})
sess.run([g_optim], feed_dict={images: batch_images, z: batch_z, y: batch_labels})
sess.run([g_optim], feed_dict={images: batch_images, z: batch_z, y: batch_labels})
if i % 100 == 0:
errD = d_loss.eval(feed_dict={images: batch_images, y: batch_labels, z: batch_z})
errG = g_loss.eval({z: batch_z, y: batch_labels})
print("epoch:[%d], i:[%d] d_loss: %.8f, g_loss: %.8f" % (epoch, i, errD, errG))
# 在训练过程中得到生成器生成的假的图片并保存
if i % 100 == 1:
sample = sess.run(samples, feed_dict={z: batch_z, y: sample_labels})
samples_path = './pics/'
save_images(sample, [8, 8], samples_path + 'epoch_%d_i_%d.png' % (epoch, i))
print('save image')
# 定期保存模型
# if i == (int(55000/BATCH_SIZE)-1):
# checkpoint_path = os.path.join('./check_point/DCGAN_model.ckpt')
# saver.save(sess, checkpoint_path, global_step=i+1)
# print('save check_point')
ops.py
import tensorflow as tf
import scipy.misc
import numpy as np
BATCH_SIZE = 100
def weight_variable(shape, name, stddev=0.02, trainable=True):
dtype = tf.float32
var = tf.get_variable(name, shape, tf.float32, trainable=trainable,
initializer=tf.random_normal_initializer(
stddev=stddev, dtype=dtype))
return var
def bias_variable(shape, name, bias_start=0.0, trainable = True):
dtype = tf.float32
var = tf.get_variable(name, shape, tf.float32, trainable=trainable,
initializer=tf.constant_initializer(
bias_start, dtype=dtype))
return var
def conv2d(x, output_channels, name, k_h=5, k_w=5):
with tf.variable_scope(name):
x_shape = x.get_shape().as_list()
w = weight_variable(shape=[k_h, k_w, x_shape[-1], output_channels], name='weights')
b = bias_variable([output_channels], name='biases')
conv = tf.nn.conv2d(x, w, strides=[1, 2, 2, 1], padding='SAME') + b
return conv
def deconv2d(x, output_shape, name, k_h=5, k_w=5):
x_shape = x.get_shape().as_list()
with tf.variable_scope(name):
# 注意这里的W的格式为 [height, width, output_channels, in_channels]
w = weight_variable([k_h, k_w, output_shape[-1], x_shape[-1]], name='weights')
bias = bias_variable([output_shape[-1]], name='biases')
deconv = tf.nn.conv2d_transpose(x, w, output_shape, strides=[1, 2, 2, 1], padding='SAME') + bias
return deconv
def fully_connect(x, channels_out, name):
shape = x.get_shape().as_list()
channels_in = shape[1]
with tf.variable_scope(name):
weights = weight_variable([channels_in, channels_out], name='weights')
biases = bias_variable([channels_out], name='biases')
return tf.matmul(x, weights) + biases
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
def conv_cond_concat(value, cond):
value_shapes = value.get_shape().as_list()
cond_shapes = cond.get_shape().as_list()
return tf.concat([value, cond * tf.ones(value_shapes[0:3] + cond_shapes[3:])], 3)
def relu(value):
return tf.nn.relu(value)
# 定义生成器,z:?*100, y:?*10
def generator(z, y, training=True):
yb = tf.reshape(y, [BATCH_SIZE, 1, 1, 10], name="yb") # y:?*1*1*10
z = tf.concat([z, y], 1) # z:?*110
# 进过一个全连接、 batch_norm、和relu
h1 = fully_connect(z, 1024, name='g_h1_fully_connect')
h1 = tf.nn.relu(tf.layers.batch_normalization(h1, training=training, name='g_h1_batch_norm'))
h1 = tf.concat([h1, y], 1) # h1: ?*1034
h2 = fully_connect(h1, 128*49, name='g_h2_fully_connect')
h2 = tf.nn.relu(tf.layers.batch_normalization(h2, training=training, name='g_h2_batch_norm'))
h2 = tf.reshape(h2, [BATCH_SIZE, 7, 7, 128]) # h2: ?*7*7*128
h2 = conv_cond_concat(h2, yb) # h2: ?*7*7*138
h3 = deconv2d(h2, output_shape=[BATCH_SIZE, 14, 14, 128], name='g_h3_deconv2d')
h3 = tf.nn.relu(tf.layers.batch_normalization(h3, training=training, name='g_h3_batch_norm')) # h3: ?*14*14*128
h3 = conv_cond_concat(h3, yb) # h3:?*14*14*138
h4 = deconv2d(h3, output_shape=[BATCH_SIZE, 28, 28, 1], name='g_h4_deconv2d')
h4 = tf.nn.sigmoid(h4) # h4: ?*28*28*1
return h4
def discriminator(image, y, reuse=False, training=True):
# with tf.variable_scope(tf.get_variable_scope(),reuse=reuse):
if reuse:
tf.get_variable_scope().reuse_variables()
yb = tf.reshape(y, [BATCH_SIZE, 1, 1, 10], name='yb') # BATCH_SIZE*1*1*10
x = conv_cond_concat(image, yb) # image: BATCH_SIZE*28*28*1 ,x: BATCH_SIZE*28*28*11
h1 = conv2d(x, 11, name='d_h1_conv2d')
h1 = lrelu(tf.layers.batch_normalization(h1, name='d_h1_batch_norm', training=training, reuse=reuse)) # h1: BATCH_SIZE*14*14*11
h1 = conv_cond_concat(h1, yb) # h1: BATCH_SIZE*14*14*21
h2 = conv2d(h1, 74, name='d_h2_conv2d')
h2 = lrelu(tf.layers.batch_normalization(h2, name='d_h2_batch_norm', training=training, reuse=reuse)) # BATCH_SIZE*7*7*74
h2 = tf.reshape(h2, [BATCH_SIZE, -1]) # BATCH_SIZE*3626
h2 = tf.concat([h2, y], 1) # BATCH_SIZE*3636
h3 = fully_connect(h2, 1024, name='d_h3_fully_connect')
h3 = lrelu(tf.layers.batch_normalization(h3, name='d_h3_batch_norm', training=training, reuse=reuse)) # BATCH_SIZE*1024
h3 = tf.concat([h3, y], 1) # BATCH_SIZE*1034
h4 = fully_connect(h3, 1, name='d_h4_fully_connect') # BATCH_SIZE*1
return tf.nn.sigmoid(h4), h4
def sampler(z, y, training=False):
tf.get_variable_scope().reuse_variables()
return generator(z, y, training=training)
def save_images(images, size, path):
# 图片归一化,主要用于生成器输出是 tanh 形式的归一化
img = (images + 1.0) / 2.0
h, w = img.shape[1], img.shape[2]
# 产生一个大画布,用来保存生成的 batch_size 个图像
merge_img = np.zeros((h * size[0], w * size[1], 3))
# 循环使得画布特定地方值为某一幅图像的值
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
if j >= size[0]:
break
merge_img[j * h:j * h + h, i * w:i * w + w, :] = image
# 保存画布
return scipy.misc.imsave(path, merge_img)
test.py
from ops import generator, save_images
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import numpy as np
BATCH_SIZE = 100
checkpoint_dir = './check_point/'
# ----------
y = tf.placeholder(tf.float32, [BATCH_SIZE, 10])
z = tf.placeholder(tf.float32, [BATCH_SIZE, 100])
G = generator(z, y)
# -----------
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 使用独热编码,也就是标签是一个二维逻辑矩阵
train = mnist.train
sample_z = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
sample_labels = train.labels[120: 120+BATCH_SIZE]
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
saver = tf.train.Saver(tf.all_variables())
sess = tf.Session()
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
saver.restore(sess, os.path.join(checkpoint_dir, ckpt_name))
images = sess.run(G, feed_dict={z: sample_z, y: sample_labels})
save_images(images, [8, 8], 'test.png')
sess.close()
结果
由于指定了固定的label,所以在获取训练模型效果的时候生成的数字都是一致的