高可用
当使用云或自托管基础设施时,实例可能是短暂的。在devops的上下文中,“发生的事情”可以翻译为“我可以获得大量的流量,并且我的一个服务将会中断”。高可用性意味着设置SKIL以提供最佳性能级别。
“高可用性”是指应用程序的连续工作,即使你丢失了一个节点或在集群内遭受网络拆分。要使SKIL部署具有HA功能,你需要以HA方式配置基础结构。
故障维修点
为了消除故障并实现高可用性,必须将每一个基础设施堆叠起来以实现冗余。当SKIL在大型基础设施中用作微服务时,这些基础设施元素通常会导致停机:
- 负载均衡
- 数据存储
- DNS/寻址
- 单主节点
- 环境(电力、火灾、洪水)
高可用的SKIL设置
在SKIL的上下文中,以下是高可用设置的一些指导方针:
- 多主机故障转移配置中的MySQL设置
- 配置奇数个ZooKeeper集群节点(取决于skil集群大小)
- 创建具有3个以上节点的SKIL集群
- 部署规模大于2的模型、转换或KNN
1. 使用NDB 7.3设置mysql集群
“NDB” 代表 “网络数据库”。NDB 与 NDBCLUSTER 这两个名称都是支持MySQL集群的存储引擎的名称。
你可以在这里找到一些关于NDB的常见问题。
基本节点概念
下面是从上面的FAQ链接中获取的一些基于节点的重要概念。mysql集群由四种节点组成,即:
- 管理节点: 此节点为整个集群提供管理服务,包括启动、关闭、备份和其他节点的配置数据。
- 数据节点: 这种类型的节点用于存储和复制数据。
- SQL节点: 这只是MySQL服务器的一个实例,它为支持NDBCLUSTER存储引擎连接到NDB集群管理服务器而构建。
- API节点: API节点是直接使用集群数据节点进行数据存储和检索的任何应用程序。因此,可以将SQL节点视为使用MySQL服务器向集群提供SQL接口的API节点类型。
NDB自动安装程序
设置NDB集群的最简单方法是使用“自动安装程序”。它是一个基于Web GUI的MySQL集群配置安装程序。你可以在这里找到更多关于它的信息。
这里提到了正确使用自动安装程序的要求。
在遵循安装说明之前,需要注意的其他一些先决条件是:
- 使用 NDB v7.3.
- 对于Linux环境,只需使用linux-generic发行版即可。因为只有这个会有“/bin”目录,所以你需要找到自动安装程序脚本ndb_setup.py。
- 需要在集群的“SQL节点”中安装Perl Data Dumper。你可以在这里找到它。
- 有时,“mariadb-libs”与安装过程冲突。在Centos中,可以使用
yum remove mariadb-libs。
使用NDB集群配置SKIL
成功安装后,可以通过将以下行添加到/etc/skil/skil-env.sh配置文件中并重新启动SKIL服务器来使用已安装的NDB集群配置SKIL实例。
TEXT
SKIL_USE_EMBEDDED_DB=false
SKIL_DB_DRIVER=com.mysql.jdbc.Driver
SKIL_DB_URL= jdbc:mysql://sql_node1_host:3306,sql_node1_host:3307,sql_node2_host:3306,sql_node2_host:3307/skil_migrations
SKIL_DB_USER=skil
SKIL_DB_PASSWORD=skil
这里,变量SKIL_DB_URL的逗号分隔字符串定义了NDB集群中的SQL节点实例。在这个示例场景中,我们在两个主机(sql_node1_host 与sql_node2_host)内部署了两个SQL节点,在每个主机的端口3306和3307上运行。
你可以在这里了解更多关于故障转移连接字符串的信息。
2. 重复的多节点ZooKeeper设置
要在重复模式下运行ZooKeeper,必须遵循ZooKeeper安装页面中描述的相同步骤,但需要对配置文件进行少许更改。
复制模式的ZooKeeper文档中提到了所需的配置更改。必须将这个配置文件保存在ZooKeeper集成的每个节点中。
对于HA,确保在集成中保留奇数个ZooKeeper节点。这对于防止“Split-brain”和“Tie-breaking”事件的发生是必要的。可以在这里进一步了解这些术语。
使用ZooKeeper集成配置SKIL
成功配置ZooKeeper集群后,可以通过将以下行添加到/etc/skil/skil-env.sh 配置文件并重新启动SKIL服务器来配置SKIL实例以使 用它。
TEXT
ZOOKEEPER_EMBEDDED=false
ZOOKEEPER_HOST=zk_host_1:2181,zk_host_3:2181,zk_host_3:2181
其中,zk_host是指配置ZooKeeper集群的节点的主机地址。
3. 多服务器SKIL设置
在为SKIL设置负载均衡器和多主机冗余之前,请阅读如何执行多服务器安装,或者你可以在此处查看博客文章。这些说明将涵盖典型SKIL实例冗余所需的大部分知识。
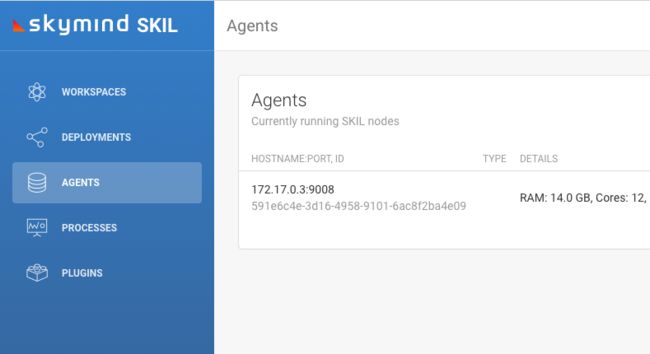
一旦将多个服务器连接在一起形成一个集群,每个SKIL节点将显示为一个“代理”。如果你最近刚将一个新的SKIL节点加入集群,请单击刷新按钮以查看列表中的新节点。
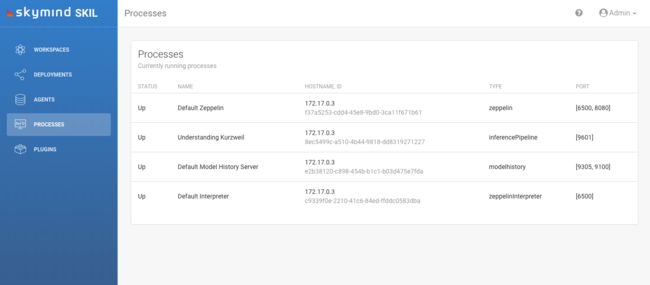
所有SKIL节点都有几个相关联的进程,集群中的所有进程都将显示在SKIL用户界面的进程列表中。这有助于可视化集群的拓扑结构。
4. 规模大于2的部署
在SKIL中部署模型时,为了获得高可用性,需要指定大于2的“scale”参数,如下图所示。
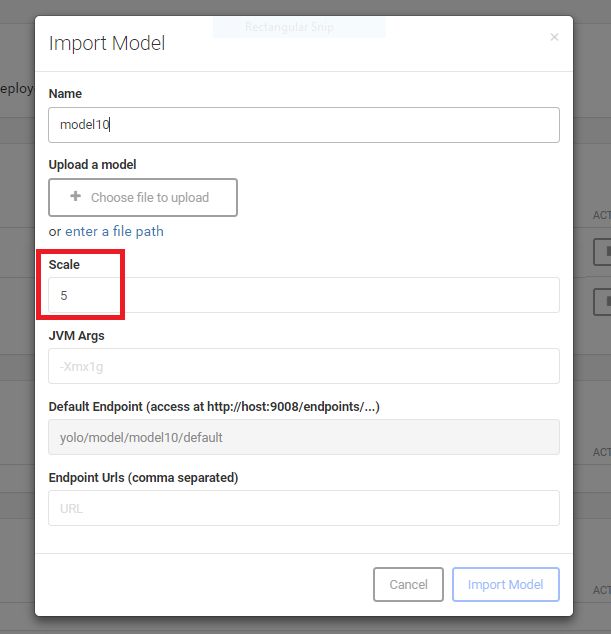
部署规模大于1
可以在“部署与生产”中进一步了解如何在SKIL中部署模型。
应用程序端
如果应用程序是硬编码的以访问单个SKIL服务器,那么如果该特定服务器发生故障,它将停止工作。可以通过以下方法之一解决此问题:
- 将所有SKIL集群主机名添加到应用程序中,如果出现错误,请使用其它主机重试请求。
- 在SKIL集群前面放置一个活动的备用负载均衡器(如F5 Big IP或HAProxy),并将其配置为在所有SKIL集群节点之间进行负载均衡。
1. 在应用程序中列出群集主机名
当以大于1的规模创建部署时,连接的SKIL实例能够为模型服务对传入HTTP请求实现内部的负载均衡。不过,我们需要在应用程序中指定SKIL主机节点的列表,这样,如果其中一个节点出现故障,我们的应用程序仍然可以工作。
Java中的示例代码看起来是这样的:
Java
// 导入
import org.datavec.spark.transform.client.DataVecTransformClient;
import org.datavec.spark.transform.model.SingleCSVRecord;
import java.text.MessageFormat;
// ----------------------------------------------------------------
// 要执行的代码
public class Main {
public static void main(String[] args) {
String[] SKIL_HOSTS = new String[]{ //替换为skil主机地址
"host1:port1",
"host2:port2",
"host3:port3"
};
String deploymentName = ""; // 部署的名称
String transformName = ""; // 转换的名称
SingleCSVRecord output = null;
for (String SKIL_HOST: SKIL_HOSTS) {
try {
DataVecTransformClient dataVecTransformClient = new DataVecTransformClient(
MessageFormat.format(
"http://{0}/endpoints/{1}/datavec/{2}/default",
SKIL_HOST,
deploymentName,
transformName
)
);
output = dataVecTransformClient.transformIncremental(
new SingleCSVRecord("1", "20", "Existing Customer - Replacement", "Phone Inquiry", "1")
);
break;
} catch (Exception e) {
e.printStackTrace();
}
}
//这里使用"output"
}
}
上述代码片段将在每次失败时重试使用部署转换服务器的请求。
将需要以下依赖项来执行上述代码:
XML
org.datavec
datavec-spark-inference-client
LATEST
请参见身认验证获取<auth_token>。
2. HAProxy 负载均衡器设置
如果不想将主机列表保存在应用程序中,并且只想使用一个主机URL,那么你必须配置像HAProxy这样的负载均衡器。
HAProxy提供了一个免费的、开源的、高可用的负载均衡器,用于管理传入的请求,并根据配置的主机列表将它们转发到所需的目标。如果我们只想在一个地方维护主机列表(在本例中,是我们部署了haproxy的机器),那么这很有用。这样,我们就不必手动维护每个应用程序中的主机列表,而只需为HAProxy主机使用一个前端URL。
可以按照本文在Centos7中配置一个HAProxy负载均衡器。
SKIL的HAProxy配置
需要为SKIL更改的配置将显示在/etc/haproxy/haproxy.cfg文件中,如下所示:
Text
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend http_front
bind *:80
stats uri /haproxy?stats
default_backend http_back
backend http_back
balance roundrobin
server :9008 check
server :9008 check
server :9008 check
server :9008 check
server :9008 check
默认的后端http_back将处理每个请求,并根据均衡方法将它们转发到适当的目的地(在本例中为RoundRobin)。
如果需要连接到负载均衡器,则需要指定前端内部配置的URL(在本例中为http_front)。使用的端口将是端口“80”。
现在,Java客户端代码看起来会像这样:
Java
// Imports
import org.datavec.spark.transform.client.DataVecTransformClient;
import org.datavec.spark.transform.model.SingleCSVRecord;
import java.text.MessageFormat;
// ----------------------------------------------------------------
// 要执行的代码
public class Main {
public static void main(String[] args) {
String SKIL_HOST = ":80";
String deploymentName = ""; //部署名称
String transformName = ""; // 转换名称
DataVecTransformClient dataVecTransformClient = new DataVecTransformClient(
MessageFormat.format(
"http://{0}/endpoints/{1}/datavec/{2}/default",
SKIL_HOST,
deploymentName,
transformName
)
);
SingleCSVRecord output = dataVecTransformClient.transformIncremental(
new SingleCSVRecord("1", "20", "Existing Customer - Replacement", "Phone Inquiry", "1")
);
//这里使用"output"
}
}
这样,就不必维护SKIL实例的主机列表,也可以消除请求重试的for循环。