工作中,大部分都是使用Python和机器学习库进行建模,但是线上环境基本上都是Java开发的,所以如何将我们训练好的模型部署到线上始终是一个问题。PMML就是针对这一问题的解决办法。
1.PMML概述
PMML全称预测模型标记语言(Predictive Model Markup Language),利用XML描述和存储数据挖掘模型,是一个已经被W3C所接受的标准。MML是一种基于XML的语言,用来定义预测模型。通过使用标准的XML解析器对PMML进行解析,应用程序能够决定模型输入和输出的数据类型,模型详细的格式,并且按照标准的数据挖掘术语来解释模型的结果。PMML提供了一个灵活机制来定义预测模型的模式,同时支持涉及多个预测模型的模型选择和模型平衡(model averaging)。PMML既可以呈现用于从数据中了解模型的统计技术(如人工神经网络和决策树),也可以呈现原始输入数据的预处理以及模型输出的后处理。
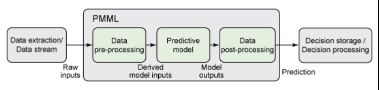
PMML文件的结构遵从了用于构建预测解决方案的常用步骤,包括:
1.数据词典,可以识别和定义哪些输入数据字段对于解决眼前的问题是最有用的,包括数值、顺序和分类字段。
2.挖掘架构,定义了处理缺少值和离群值的策略。这非常有用,因为通常情况,当将模型应用于实践时,所需的输入数据字段可能为空或者被误呈现。
3.数据转换,定义了将原始输入数据预处理至派生字段所需的计算。派生字段(有时也称为特征检测器)对输入字段进行合并或修改,以获取更多相关信息。例如,为了预测停车所需的制动压力,一个预测模型可能将室外温度和水的存在(是否在下雨?)作为原始数据。派生字段可能会将这两个字段结合起来,以探测路上是否结冰。然后结冰字段被作为模型的直接输入来预测停车所需的制动压力。
4.模型定义,定义了用于构建模型的结构和参数。PMML涵盖了多种统计技术。例如,为了呈现一个神经网络,它定义了所有的神经层和神经元之间的连接权重。对于一个决策树来说,它定义了所有树节点及简单和复合谓语。
5.输出,定义了预期模型输出。对于一个分类任务来说,输出可以包括预测类及与所有可能类相关的概率。
6.目标,定义了应用于模型输出的后处理步骤。对于一个回归任务来说,此步骤支持将输出转变为人们很容易就可以理解的分数(预测结果)。
7.模型解释,定义了将测试数据传递至模型时获得的性能度量标准。这些度量标准包括字段相关性、混淆矩阵、增益图及接收者操作特征(ROC)曲线图。
8.模型验证,定义了一个包含输入数据记录和预期模型输出的示例集。这是非常重要的一个步骤,因为在应用程序之间移动模型时,该模型需要通过匹配测试。这样就可以确保,在呈现相同的输入时,新系统可以生成与旧系统同样的输出。如果实际情况是这样的话,一个模型将被认为经过了验证,且随时可用于实践。
2.PMML深度解析
如上所述,PMML的结构反映了常用于创建预测解决方案的八大步骤,从在“数据词典”步骤中定义原始输入数据字段到在“模型验证”步骤中验证模型是否得到正确部署。
表1展示了一个含有三个字段的解决方案中PMML元素DataDictionary的定义,这三个字段是:数值型输入字段Value、分类输入字段Element和数值型输出字段Risk。
表1 DataDictionary元素
对于字段Value,范围从负无穷大到60的值是有效值。高于60的值被定义为无效值。考虑到字段Element是分类的,有效值被明确地列出。如果该特定字段的数据提要包含元素Iron,将该元素作为无效值处理。
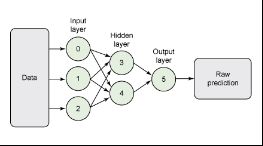
上图展示了神经网络模型的图形表示,其中输入层包含3个神经元,隐藏层包含2个神经元,输出层包含1个神经元。如您所期望的,PMML可以完全呈现这样一个结构。
表2展示了隐藏层及其神经元以及输入层(0、1和2)和隐藏层(3和4)中神经元的连接权重的定义。
表2 在PMML中定义神经层及其神经元
PMML不是一件艰难的事。其复杂程度反映了其呈现的建模技术的复杂程度。事实上,它揭开了许多人感到神秘的预测分析的秘密和黑匣子。利用PMML,任何预测解决方案都可以采用同样的顺序用同一种语言元素呈现。
3.SAX解析xml文件
SAX(simple API for XML)是一种XML解析的替代方法。相比于DOM,SAX是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。而且相比于DOM,SAX可以在解析文档的任意时刻停止解析,但任何事物都有其相反的一面,对于SAX来说就是操作复杂。
SAX是事件驱动型XML解析的一个标准接口,对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。
大多数SAX都会产生以下类型的事件:
1.在文档的开始和结束时触发文档处理事件。
2.在文档内每一XML元素接受解析的前后触发元素事件。
3.任何元数据通常由单独的事件处理。
4.在处理文档的DTD或Schema时产生DTD或Schema事件。
5.产生错误事件用来通知主机应用程序解析错误。
JAXB可以把xml对象转化为java对象,也可以把java对象转化为xml对象。这时候我们就得知道它的两个转化方法。一个是unmarshal(),一个是marshal()。marshal()是把java对象序列化为xml对象的一个过程。unmarshal()是把xml对象反序列化为我们需要的java对象的方法。
4.sklearn训练模型
这里训练一个很简单的分类模型,然后将模型导出为pmml文件。
安装sklearn2pmml:pip install sklearn2pmml。
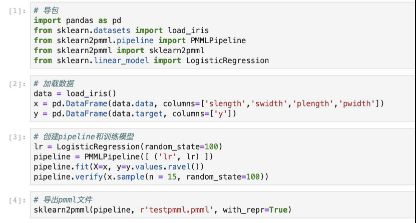
# 导包
import pandas as pd
from sklearn.datasets import load_iris
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml import sklearn2pmml
from sklearn.linear_model import LogisticRegression
# 加载数据
data = load_iris()
x = pd.DataFrame(data.data, columns=['slength','swidth','plength','pwidth'])
y = pd.DataFrame(data.target, columns=['y'])
# 创建pipeline和训练模型
lr = LogisticRegression(random_state=100)
pipeline = PMMLPipeline([ ('lr', lr) ])
pipeline.fit(X=x, y=y.values.ravel())
pipeline.verify(x.sample(n = 15, random_state=100))
# 导出pmml文件
sklearn2pmml(pipeline, r'testpmml.pmml', with_repr=True)
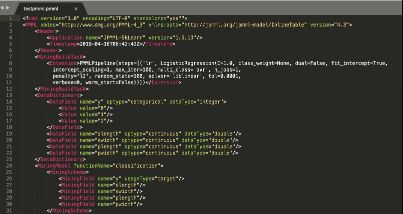
导出的pmml文件具体内容如下:通过DataDictionary可以看出,该分类问题为3分类问题,4个特征分别为slength、swidth、plength和pwidth。
5. idea创建springboot项目
5.1 创建新项目

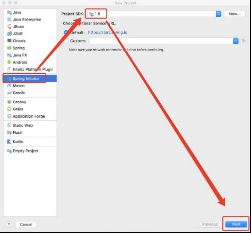
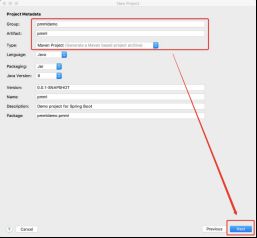
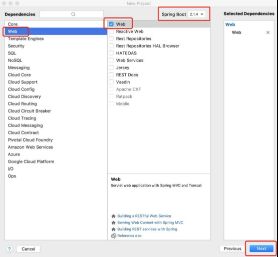
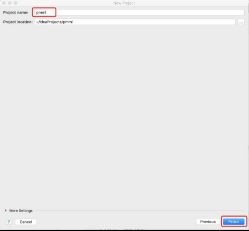
5.2 在pom.xml中添加dependency
jpmml是java解析pmml的类库,fastjson是阿里巴巴开源的解析json是类库,org.glassfish.jaxb是jpmml依赖的一个类库,以前是标准类库,后来被移除了,要求手动添加。
第一次添加dependency之后,需要下载这些依赖库,点击刷新按钮,等依赖库下载完成即可。
org.jpmml
pmml-evaluator
1.4.5
org.jpmml
pmml-evaluator-extension
1.4.5
com.alibaba
fastjson
1.2.54
org.glassfish.jaxb
jaxb-runtime
2.3.0
com.jayway.jsonpath
json-path
5.3 新建一个PmmlPredict.java类
PmmlPredict.java类要做的只有两件事,1是在springboot启动时加载pmml并初始化模型,2是定义一个预测函数,方便http调用,然后返回预测值。
package pmmldemo.pmml;
import com.alibaba.fastjson.JSONObject;
import org.dmg.pmml.FieldName;
import org.jpmml.evaluator.*;
import org.xml.sax.SAXException;
import javax.xml.bind.JAXBException;
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class PmmlPredict {
//将模型定义为全局变量,springboot启动时加载pmml并初始化
public static Evaluator evaluator;
//模型初始化方法,springboot启动时执行该方法,然后初始化上面的Evaluator
public static void initModel() throws IOException, SAXException, JAXBException {
File file = new File("/Users/a5210/testpmml.pmml");
evaluator = new LoadingModelEvaluatorBuilder().load(file).build();
evaluator.verify();
}
//定义一个实用函数,就是python中的print函数,没别的意思
public static void print(Object... args){
Arrays.stream(args).forEach(System.out::print);
System.out.println("");
}
// 定义预测函数,htt请求该函数,然后返回预测值
// 传入的参数是一个json,字段要求和模型的字段保持一致
public static Integer predict(JSONObject feature){
// 获取模型定义的特征
List inputFields = evaluator.getInputFields();
print("模型的特征是:", inputFields);
// 获取模型定义的目标名称
List targetFields = evaluator.getTargetFields();
print("目标字段是:",targetFields);
// 示例传进来的json数据
// String json = "{\"slength\": 1.0, \"swidth\": 1.0, \"plength\": 1.0, \"pwidth\": 1.0}";
// JSONObject feature = JSONObject.parseObject(json);
// 将json转成evaluator要求的map格式,其实就是对key和value再做一层包装而已
Map arguments = new LinkedHashMap<>();
for(InputField inputField: inputFields){
FieldName inputName = inputField.getName();
String name = inputName.getValue();
Object rawValue = feature.getDoubleValue(name);
FieldValue inputValue = inputField.prepare(rawValue);
arguments.put(inputName, inputValue);
}
// 得到特征数据后就是预测了
Map results = evaluator.evaluate(arguments);
Map resultRecord = EvaluatorUtil.decode(results);
Integer y = (Integer) resultRecord.get("y");
// 打印结果会更加了解其中的封装过程
print("预测结果:");
print(results);
print(resultRecord);
print(y);
return y;
}
}
5.4 新建一个InitializingModel.java类
InitializingModel.java.java类负责初始化模型,并对外提供接口路径。
package pmmldemo.pmml;
import com.alibaba.fastjson.JSONObject;
import org.springframework.web.bind.annotation.*;
@RestController
public class InitializingModel {
// 定义index页,也是为了测试网络是否通畅
@RequestMapping("/")
public String index() {
return "hello spring for test";
}
// 定义一个接口,从http中接受RequestBody中的字符串,这是一个json的字符串,用fastjson解析成json后直接调用预测函数PmmlPredict.predict进行预测
@RequestMapping(value="/predict", method=RequestMethod.POST, produces="application/json;charset=UTF-8")
public @ResponseBody
String getModel(@RequestBody String feature) {
// 将字符串解析成json
JSONObject json = JSONObject.parseObject(feature);
// 调用PmmlPredict.initModel()
try {
PmmlPredict.initModel();
} catch (Exception e) {
e.printStackTrace();
}
// 预测
double y = PmmlPredict.predict(json);
// 返回
return String.valueOf(y);
}
}
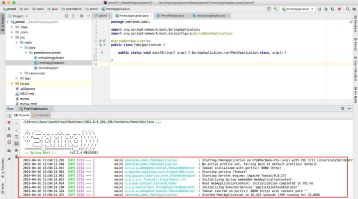
5.5 启动springboot
6.使用postman进行测试
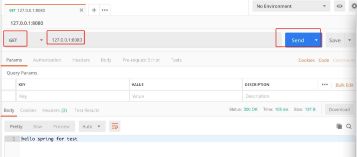
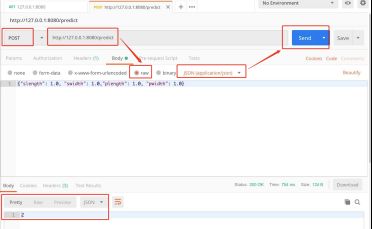
查看预测函数的打印输出,如下所示,可以看到,对于分类模型,会输出各个类别的预测概率,然后返回概率最大的一个类作为预测的概率。
模型的特征是:[InputField{name=slength, displayName=null, dataType=double, opType=continuous}, InputField{name=swidth, displayName=null, dataType=double, opType=continuous}, InputField{name=plength, displayName=null, dataType=double, opType=continuous}, InputField{name=pwidth, displayName=null, dataType=double, opType=continuous}]
目标字段是:[TargetField{name=y, displayName=null, dataType=integer, opType=categorical}]
预测结果:
{y=ProbabilityDistribution{result=2, probability_entries=[0=0.20617333796640783, 1=0.24651265148432944, 2=0.5473140105492628]}, probability(0)=0.20617333796640783, probability(1)=0.24651265148432944, probability(2)=0.5473140105492628}
{y=2, probability(0)=0.20617333796640783, probability(1)=0.24651265148432944, probability(2)=0.5473140105492628}
2
也可以使用python代码发送数据,并返回结果。
import requests
url = 'http://127.0.0.1:8080/predict'
data = {"slength": 1.0, "swidth": 1.0,"plength": 1.0, "pwidth": 1.0}
r = requests.post(url, json=data)
print(r.text)

7.aiohttp并发测试
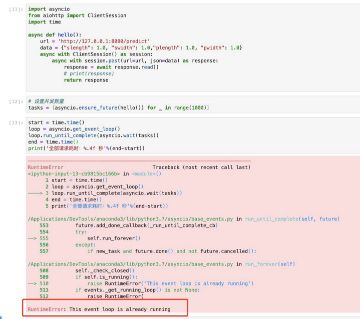
为解决RuntimeError: This event loop is already running问题,先安装nest_asyncio:pip install nest_asyncio。
import asyncio
from aiohttp import ClientSession
import time
import nest_asyncio
nest_asyncio.apply()
async def hello():
url = 'http://127.0.0.1:8080/predict'
data = {"slength": 1.0, "swidth": 1.0,"plength": 1.0, "pwidth": 1.0}
async with ClientSession() as session:
async with session.post(url=url, json=data) as response:
response = await response.read()
# print(response)
return response
# 设置并发数量
tasks = [asyncio.ensure_future(hello()) for _ in range(1000)]
start = time.clock()
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.clock()
print('全部请求耗时:%.4f 秒'%(end-start))
8.PMML总结与思考
PMML的确是跨平台的利器,但也有如下缺点:
第一个就是PMML为了满足跨平台,牺牲了很多平台独有的优化,所以很多时候我们用算法库自己的保存模型的API得到的模型文件,要比生成的PMML模型文件小很多。同时PMML文件加载速度也比算法库自己独有格式的模型文件加载慢很多。
第二个就是PMML加载得到的模型和算法库自己独有的模型相比,预测会有一点点的偏差,当然这个偏差并不大。比如某一个样本,用sklearn的决策树模型预测为类别1,但是如果我们把这个决策树落盘为一个PMML文件,并用JAVA加载后,继续预测刚才这个样本,有较小的概率出现预测的结果不为类别1。
第三个就是对于超大模型,比如大规模的集成学习模型,比如xgboost,随机森林,或者tensorflow,生成的PMML文件很容易得到几个G,甚至上T,这时使用PMML文件加载预测速度会非常慢,此时推荐为模型建立一个专有的环境,就没有必要去考虑跨平台了。
此外,对于TensorFlow,不推荐使用PMML的方式来跨平台。可能的方法一是TensorFlow serving,自己搭建预测服务,但是会稍有些复杂。另一个方法就是将模型保存为TensorFlow的模型文件,并用TensorFlow独有的JAVA库加载来做预测。
9.补充参考
https://www.ibm.com/developerworks/cn/opensource/ind-PMML1/
https://zhuanlan.zhihu.com/p/53729084
https://www.cnblogs.com/pinard/p/9220199.html