之前刚将Tensorflow入门级模型,MINIST数据在PC端上训练,保存,恢复,以及用自己的图片来进行识别预测,效果都不错的完成了。于是想将这个模型再移植到android上。折腾一番后,终于搞定了。写此分享
1.首先获取Pb格式的模型,
MINIST的训练具体过程可以看我的这篇文章,如果只是想配置熟悉下这个移植过程,则略过那篇,直接用下面的代码训练
minist.py:
#coding=utf-8
# 载入MINIST数据需要的库
from tensorflow.examples.tutorials.mnist import input_data
# 保存模型需要的库
from tensorflow.python.framework.graph_util import convert_variables_to_constants
from tensorflow.python.framework import graph_util
# 导入其他库
import tensorflow as tf
import cv2
import numpy as np
#获取MINIST数据
mnist = input_data.read_data_sets(".",one_hot = True)
# 创建会话
sess = tf.InteractiveSession()
#占位符
x = tf.placeholder("float", shape=[None, 784], name="Mul")
y_ = tf.placeholder("float",shape=[None, 10], name="y_")
#变量
W = tf.Variable(tf.zeros([784,10]),name='x')
b = tf.Variable(tf.zeros([10]),'y_')
#权重
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
#偏差
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#卷积
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
#最大池化
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#相关变量的创建
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
#激活函数
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float",name='rob')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#用于训练用的softmax函数
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2,name='res')
#用于训练作完后,作测试用的softmax函数
y_conv2=tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2,name="final_result")
# res = tf.argmax(y_conv2,1,name="result")
#交叉熵的计算,返回包含了损失值的Tensor。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
#优化器,负责最小化交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
#计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
#初始化所以变量
sess.run(tf.global_variables_initializer())
# 保存输入输出,可以为之后用
tf.add_to_collection('res', y_conv)
tf.add_to_collection('output', y_conv2)
# tf.add_to_collection('result', res)
tf.add_to_collection('x', x)
#训练开始
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
#run()可以看做输入相关值给到函数中的占位符,然后计算的出结果,这里将batch[0],给xbatch[1]给y_
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#将当前图设置为默认图
graph_def = tf.get_default_graph().as_graph_def()
#将上面的变量转化成常量,保存模型为pb模型时需要,注意这里的final_result和前面的y_con2是同名,只有这样才会保存它,否则会报错,
# 如果需要保存其他tensor只需要让tensor的名字和这里保持一直即可
output_graph_def = tf.graph_util.convert_variables_to_constants(sess,
graph_def, ['final_result'])
#保存前面训练后的模型为pb文件
with tf.gfile.GFile("grf.pb", 'wb') as f:
f.write(output_graph_def.SerializeToString())
#保存模型
saver = tf.train.Saver()
saver.save(sess, "model_data/model")
print "test accracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
运行后,最终输出,一个文件夹(存放用Saver保存的数据,不用),还有一个grf.pb(我们要用的文件):

2.得到pb格式的模型后,移植便开始了
1)tensorflow库文件的获取
需要以下两个文件:
libtensorflow_inference.so
libandroid_tensorflow_inference_java.jar
可以自己编译tensorflow库获取(自己编译出的问题比较多,建议直接下载),
直接下载地址,想自己编译获取可以见这篇博客
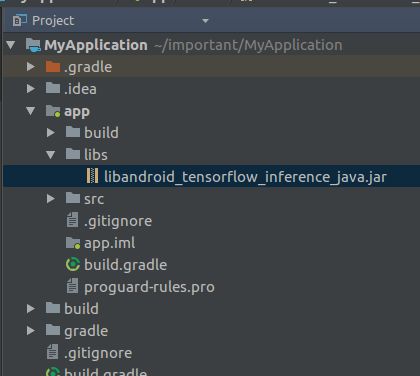
2)将库文件添加到自己android工程中(android studio)
将libandroid_tensorflow_inference_java.jar存放到/app/libs目录下:
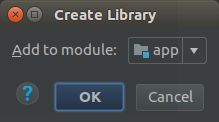
再右键libandroid_tensorflow_inference_java.jar 选择“add as Libary”,再点ok:
在/app/libs下新建armeabi文件夹,并将libtensorflow_inference.so放进去

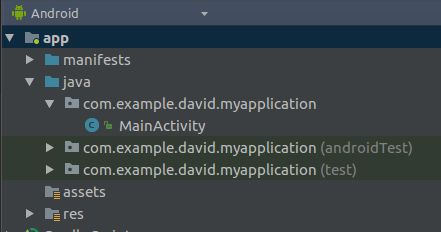
在工程根目录下新建assets(右键app->new->Folder->Assets Folader ->Finish):
再将上面生成grf.pb文件直接复制到assets目录下:
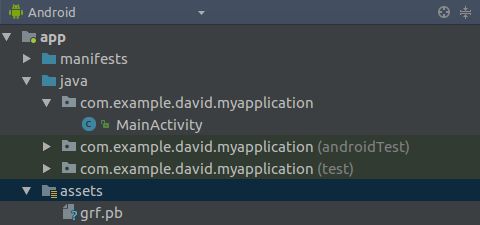
1.配置在app:gradle文件
在app:gradle文件中的android节点下添加soureSets,用于制定jniLibs的路径:
sourceSets {
main {
jniLibs.srcDirs = ['libs']
}
}
在defaultConfig节点下添加
defaultConfig {
ndk {
abiFilters "armeabi"
}
}
如图:
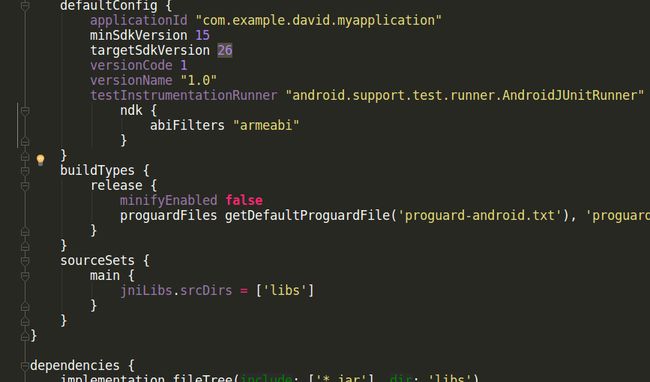
2.在gradle.properties中添加下面一行
android.useDeprecatedNdk=true
如图:
以上配置过程主要参考博客
接下来新建一个识别图像的类TF_MINIST:
/**
* Created by david on 12/3/17.
*/
import android.content.res.AssetManager;
import android.graphics.Bitmap;
import android.graphics.Color;
import android.graphics.Matrix;
import android.os.Trace;
import android.util.Log;
import android.widget.ImageView;
import android.widget.TextView;
import org.tensorflow.contrib.android.TensorFlowInferenceInterface;
import java.io.ByteArrayOutputStream;
import java.lang.reflect.Array;
public class TF_MINIST {
private static final String MODEL_FILE = "file:///android_asset/grf.pb"; //模型存放路径
//数据的维度
private static final int HEIGHT = 28;
private static final int WIDTH = 28;
private static final int MAXL = 10;
//模型中输出变量的名称
private static final String inputName = "Mul";
//用于存储的模型输入数据
private float[] inputs = new float[HEIGHT * WIDTH];
//模型中输出变量的名称
private static final String outputName = "final_result";
//用于存储模型的输出数据,0-9
private float[] outputs = new float[MAXL];
TensorFlowInferenceInterface inferenceInterface;
static {
//加载库文件
System.loadLibrary("tensorflow_inference");
}
TF_MINIST(AssetManager assetManager) {
//接口定义
inferenceInterface = new TensorFlowInferenceInterface(assetManager,MODEL_FILE);
}
/**
* 将彩色图转换为灰度图
* @param img 位图
* @return 返回转换好的位图
*/
public Bitmap convertGreyImg(Bitmap img) {
int width = img.getWidth(); //获取位图的宽
int height = img.getHeight(); //获取位图的高
int []pixels = new int[width * height]; //通过位图的大小创建像素点数组
img.getPixels(pixels, 0, width, 0, 0, width, height);
int alpha = 0xFF << 24;
for(int i = 0; i < height; i++) {
for(int j = 0; j < width; j++) {
int grey = pixels[width * i + j];
int red = ((grey & 0x00FF0000 ) >> 16);
int green = ((grey & 0x0000FF00) >> 8);
int blue = (grey & 0x000000FF);
grey = (int)((float) red * 0.3 + (float)green * 0.59 + (float)blue * 0.11);
grey = alpha | (grey << 16) | (grey << 8) | grey;
pixels[width * i + j] = grey;
}
}
Bitmap result = Bitmap.createBitmap(width, height, Bitmap.Config.RGB_565);
result.setPixels(pixels, 0, width, 0, 0, width, height);
return result;
}
//将int数组转化为float数组
public float[] ints2float(int[] src,int w){
float res[]=new float[w];
for(int i=0;ioutput[maxIndex]? i: maxIndex;
}
return maxIndex;
}
//将图像像素数据转为一维数组,isReverse判断是否需要反化图像
public int[] getGrayPix_R(Bitmap bp,boolean isReverse){
int[]pxs=new int[784];
int acc=0;
for(int m=0;m<28;++m){
for(int n=0;n<28;++n){
if(isReverse)
pxs[acc]=255-Color.red(bp.getPixel(n,m));
else
pxs[acc]=Color.red(bp.getPixel(n,m));
Log.d("12","gray_"+acc+":"+pxs[acc]+"_");
++acc;
}
}
return pxs;
}
//灰化图像
public Bitmap gray(Bitmap bitmap, int schema)
{
Bitmap bm = Bitmap.createBitmap(bitmap.getWidth(),bitmap.getHeight(), bitmap.getConfig());
int width = bitmap.getWidth();
int height = bitmap.getHeight();
for(int row=0; row> 16) &0xff
int green = Color.green(pixel); // same as (pixel >> 8) &0xff
int blue = Color.blue(pixel); // same as (pixel & 0xff)
int alpha = Color.alpha(pixel); // same as (pixel >>> 24)
int gray = 0;
if(schema == 0)
{
gray = (Math.max(blue, Math.max(red, green)) +
Math.min(blue, Math.min(red, green))) / 2;
}
else if(schema == 1)
{
gray = (red + green + blue) / 3;
}
else if(schema == 2)
{
gray = (int)(0.3 * red + 0.59 * green + 0.11 * blue);
}
Log.d("12","gray:"+gray);
bm.setPixel(col, row, Color.argb(alpha, gray, gray, gray));
}
}
return bm;
}
//获得预测结果
public int getAddResult(Bitmap bitmap) {
int width = bitmap.getWidth();
int height = bitmap.getHeight();
float scaleWidth = ((float)WIDTH) / width;
float scaleHeight = ((float) HEIGHT) / height;
Matrix matrix = new Matrix();
//调整图像大小为28x28
matrix.postScale(scaleWidth, scaleHeight);
Bitmap newbm = Bitmap.createBitmap(bitmap, 0, 0, width, height, matrix, true);
//灰化图片,注意这里虽然是灰化,但只是将R,G,B的值都变成一样的,所以本质上还是RGB的三通道图像
newbm=gray(newbm,2);
//这里的isReverse,true则获得反化的图像数据,否则不是,返回为一维数组
int pxs[]=getGrayPix_R(newbm,true);
//输入图像到模型中
Trace.beginSection("feed");
inferenceInterface.feed(inputName, ints2float(pxs,784),1, 784);
Trace.endSection();
//获得模型输出结果
Trace.beginSection("run");
String[] outputNames = new String[] {outputName};
inferenceInterface.run(outputNames);
Trace.endSection();
//将输出结果存放到outputs中
Trace.beginSection("fetch");
inferenceInterface.fetch(outputName, outputs);
Trace.endSection();
//类似于tf.argmax()的功能,寻找output中最大值的index
return argmax(outputs);
}
}
注意:
1.这里的inputName要和minist.py里的x = tf.placeholder("float", shape=[None, 784], name="Mul")的name一致,作为输入,
outputName需和output_graph_def = tf.graph_util.convert_variables_to_constants(sess,
graph_def, ['final_result']) 的name一致,作为运算和输出
2.如果图片为白底黑字,getGrayPix_R(Bitmap bp,boolean isReverse)的第二个参数isReverse需要为true来反转的像素数据,否则为false,因为MINIST库是黑底白字的图片
最后只要在自己的工程里调用getAddResult(Bitmap bitmap),传进bitmap就可以识别照片中的数字了,如我在MainActivity里面加的:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TF_MINIST m=new TF_MINIST(getAssets());
Bitmap bitmap= BitmapFactory.decodeResource(getResources(),R.drawable.e);
TextView tv=findViewById(R.id.DOutput);
ImageView im=findViewById(R.id.DImg);
im.setImageBitmap(bitmap);
tv.append("The digit is "+m.getAddResult(bitmap));
}
运行结果:

附:android工程源码地址
主要参考:将tensorflow训练好的模型移植到android