主成分分析(Principal Component Analysis, PCA)
一个优秀的模型应该是用尽可能少的特征来涵盖尽可能多的信息。对于多元线性回归模型,除了对全部特征进行筛选和压缩——这些都是针对原特征本身,那么是否可以把多个特征组合成少数的几个新特征,使模型更加简洁?特别是多个特征之间往往还存在多重共线性关系。
主成分分析的核心思想就是降维,把高维空间上的多个特征组合成少数几个无关的主成分,同时包含原数据中大部分的变异信息。举个例子,在二维平面中,如果大部分的点都在一条直线附近,是不是就可以直接用这条直线当作一维坐标轴来反映原始数据?在三维空间中,如果大部分的点都在一个平面附近,是不是就可以直接用这个平面当作二维平面来反映原始数据?
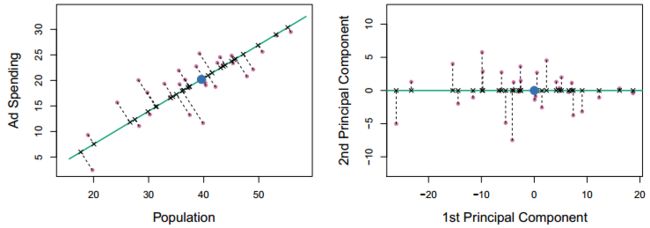
以上概念中的变异信息就用方差来衡量,第一主成分是高维空间上的一个向量,所有的点沿着这条线波动最大,或者说所有的点到直线的距离的平方和最小。如下图所示,所有的点沿着绿色直线的波动最大,它就代表着第一主成分向量。

有了第一主成分,还可以依次往后选择主成分,各主成分之间是相互正交的向量。如下左图所示,右图是左图的旋转,以第一主成分作为x轴,第二主成分作为y轴与之垂直。
以上是主成分的几何意义,那么它的数学意义是什么?如何去求解主成分向量?
首先,我们定义主成分是原特征的线性组合,即:
找到一组Φ(其平方和为1),使Z1的方差最大,它的优化问题变成:
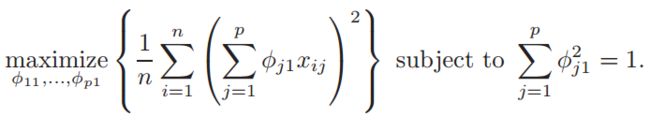
第一主成分确定之后,如果是二维空间那么第二主成分就可以通过正交关系直接确定;对于高维空间,一个向量的正交向量可以有无数个,则在其正交向量中继续优化上式至最大值;之后的主成分依次类推。
以下以美国的犯罪记录数据为例,对特征进行PCA:
> library(ISLR)
> apply(USArrests,2,mean) # 各变量均值差异很大
Murder Assault UrbanPop Rape
7.788 170.760 65.540 21.232
> apply(USArrests,2,var) # 各变量方差差异也很大
Murder Assault UrbanPop Rape
18.97047 6945.16571 209.51878 87.72916
>
> ## 必须要对变量进行标准化,否则主成分就由Assault一个变量决定
>
> pr.out = prcomp(USArrests,scale. = T)
> names(pr.out)
[1] "sdev" "rotation" "center" "scale" "x"
> pr.out$center # 标准化之后的均值
Murder Assault UrbanPop Rape
7.788 170.760 65.540 21.232
> pr.out$scale # 标准化之后的标准差
Murder Assault UrbanPop Rape
4.355510 83.337661 14.474763 9.366385
>
> pr.out$rotation # 主成分负荷,这个矩阵列向量两两数量积都近似于0,可见主成分负荷向量的确是正交的
PC1 PC2 PC3 PC4
Murder -0.5358995 0.4181809 -0.3412327 0.64922780
Assault -0.5831836 0.1879856 -0.2681484 -0.74340748
UrbanPop -0.2781909 -0.8728062 -0.3780158 0.13387773
Rape -0.5434321 -0.1673186 0.8177779 0.08902432
> biplot(pr.out,scale = 0)

这张图是主成分分析的双坐标图,略复杂。这里解释一下:这个图是二维的,所以它只展示第一和第二主成分,PC1和PC2侧的坐标轴(即矩形下方和左方两个)映射的是主成分得分,而上侧和右侧的两个坐标轴(即刻度是红色的)映射的主成分负荷。图中每一个黑色的单词代表一个观测数据,它的位置对应着该观测数据在第一和第二主成分上的得分或负荷。红色的箭头是各个特征在第一和第二主成分上的负荷向量,该向量在右上侧的坐标系下的投影即为主成分负荷。
从这张图中能看出什么?
-
Assault、Murder、Rape这三个特征在第一主成分负荷向量上的权重大致相同,而UrbanPop的权重较小; -
UrbanPop在第二主成分负荷向量上的权重较大,而其他三个特征权重较小; - 三个与犯罪相关的变量位置较近,相关性强;
UrbanPop与其他三个变量相关性较弱。
接下来就看各个主成分所占方差比(即解释数据变异的程度),来确定选择几个主成分。
> pr.var = pr.out$sdev ^ 2 # 样本在四个主成分的方差
> pr.var
[1] 2.4802416 0.9897652 0.3565632 0.1734301
> pve = pr.var/sum(pr.var) # 各主成分的方差解释比例
> pve # 第一主成分解释了数据62%的方差,第二主成分解释了24.7%的方差
[1] 0.62006039 0.24744129 0.08914080 0.04335752
>
> plot(pve,xlab="Principal Component",ylab = "Proportion of Variance Explained",ylim = c(0,1),type="b")
> plot(cumsum(pve),xlab="Principal Component",ylab = "Cumulative Proportion of Variance Explained",ylim = c(0,1),type="b")

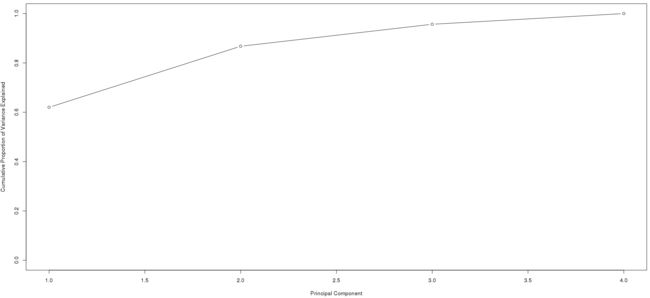
由图中可见,选择前两个或前三个主成分,已经足以解释数据大部分的变异信息了。
主成分回归(Principal Component Regression, PCR)
所谓主成分回归,就是基于以筛选出的主成分作为特征来构建回归模型。这里依然以 Hitters数据集为例,构建PCR模型。
library(ISLR)
library(pls)
Hitters = na.omit(Hitters)
x = model.matrix(Salary~.,Hitters)[,-1]
y = Hitters$Salary
y.test = y[test]
set.seed(2)
train = sample(1:nrow(x),nrow(x)/2)
test = -train
pcr.fit = pcr(Salary~.,data=Hitters,subset=train,scale=T,validation="CV") # 10折交叉验证
summary(pcr.fit)
validationplot(pcr.fit,val.type="MSEP")

从图中可见7个主成分时,测试集的均方差最小。以下以7个主成分开始建立PCR模型。
> pcr.pred = predict(pcr.fit,x[test,],ncomp = 7)
> mean((pcr.pred-y.test)^2)
[1] 289676.6
>
> prc.fit = pcr(y~x,scale=T,ncomp=7)
> summary(prc.fit)
Data: X dimension: 263 19
Y dimension: 263 1
Fit method: svdpc
Number of components considered: 7
TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps 5 comps 6 comps 7 comps
X 38.31 60.16 70.84 79.03 84.29 88.63 92.26
y 40.63 41.58 42.17 43.22 44.90 46.48 46.69
7个主成分已经可以概括92.26%的方差,不过这7个主成分都是所有特征线性组合而来,没有进行变量筛选,也没有估计特征系数,所以可解释性也不好。
偏最小二乘回归(Partial Least Squares Regression, PLSR)
PCA是一种无监督式学习,所以PCR中响应变量也没有参与指导主成分的构造,所以PCR有一个弊端:无法保证很好地解释预测变量的方向同样可以很好地预测响应变量。
PLSR则是一种监督式的指导PCR的替代方法,它把m个主成分作为新的变量集,在此基础上进行最小二乘回归,所以响应变量起到了调整各主成分参数的作用。
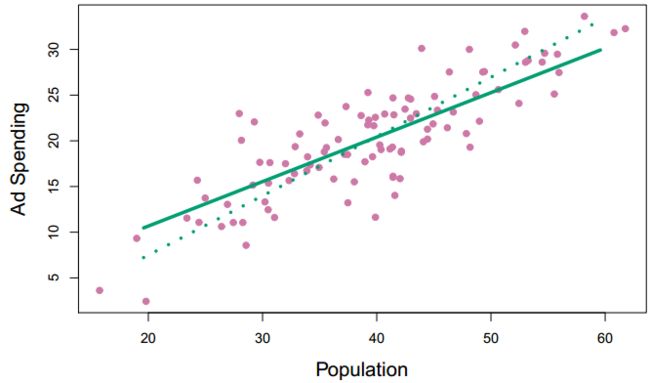
如上图所示,实线代表第一PLS方向,虚线代表第一主成分方向。直观地看PLS比PCA拟合得更好,即所有的点到PLS方向上的MSE更小。
所以较之PCR,PLSR实质上是以提升一部分方差为代价来减小偏差。
> set.seed(1)
> pls.fit = plsr(Salary~.,data=Hitters,subset=train,scale=T,validation="CV")
> summary(pls.fit)
Data: X dimension: 131 19
Y dimension: 131 1
Fit method: kernelpls
Number of components considered: 19
VALIDATION: RMSEP
Cross-validated using 10 random segments.
(Intercept) 1 comps 2 comps 3 comps 4 comps 5 comps 6 comps
CV 478.9 402.2 405.5 408.4 411.9 424.2 428.0
adjCV 478.9 401.5 403.8 406.2 409.5 420.5 423.8
7 comps 8 comps 9 comps 10 comps 11 comps 12 comps 13 comps
CV 427.4 429.1 433.0 424.5 424.6 424.3 424.9
adjCV 423.1 424.2 427.7 420.1 420.1 419.7 420.2
14 comps 15 comps 16 comps 17 comps 18 comps 19 comps
CV 421.3 424.6 426.1 425.1 425.4 426.8
adjCV 416.9 419.9 421.3 420.4 420.7 422.0
TRAINING: % variance explained
1 comps 2 comps 3 comps 4 comps 5 comps 6 comps 7 comps 8 comps
X 37.35 50.47 66.85 74.86 78.96 85.30 89.10 91.28
Salary 34.72 40.24 42.21 43.52 45.14 45.83 46.59 47.62
9 comps 10 comps 11 comps 12 comps 13 comps 14 comps 15 comps
X 93.13 94.93 96.25 97.86 98.23 98.65 99.06
Salary 48.15 48.47 48.75 48.89 49.06 49.22 49.36
16 comps 17 comps 18 comps 19 comps
X 99.63 99.79 99.99 100.00
Salary 49.42 49.46 49.48 49.57
> validationplot(pls.fit,val.type = "MSEP") # m=2时,交叉验证误差最小

> pls.pred = predict(pls.fit,x[test,],ncomp=2)
> mean((pls.pred-y.test)^2)
[1] 253697
>
> # 最后在整个数据集上建立PLSR模型
> pls.fit = plsr(Salary~.,data=Hitters,scale=T,ncomp=2)
> summary(pls.fit) # 2个主成分解释了响应变量的46.4%的方差,与上面PCR 7个主成分回归的结果差不多
Data: X dimension: 263 19
Y dimension: 263 1
Fit method: kernelpls
Number of components considered: 2
TRAINING: % variance explained
1 comps 2 comps
X 38.08 51.03
Salary 43.05 46.40