论文名称:Aggregated Residual Transformations for Deep Neural Networks
论文作者:Saining Xie Ross Girshick Piotr Doll´ar Zhuowen Tu Kaiming He
论文链接:https://arxiv.org/abs/1611.05431
1.综述
本文提出了ResNet网络升级版——ResNeXt网络;以往提高模型准确率的方法都是加深网络或者加宽网络,例如WRN,16层的WRN性能好于之前的ResNet的效果。然而随着超参数数量的增加,网络设计的难度和计算开销也会增加。所以本文提出了 ResNeXt 结构,该结构可以在不增加参数复杂度的前提下提高模型的准确率,同时也可减少超参数数量。
2.研究背景与内容
2.1 研究背景
作者在论文中首先提到VGG,VGG主要采用堆叠网络来实现,之前的 ResNet 也借用了同样的思想。该网络提出了一种简单有效的方式来构建深层神经网络。文中还提到 Inception 系列网络,Inception 模型证明了精心设计的网络拓扑结构可以在较低理论复杂度的情况下获得较好的效果。Inception网络重要的策略之一就是split-transform-merge策略,但是Inception 系列网络有以下问题与难题:网络的超参数设定的针对性比较强,即滤波器的数量都是特制的,虽然这些模块组合会有优异的模型表现,但是当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
于是作者在这篇论文中提出网络 ResNeXt,同时采用了VGG 堆叠的思想和 Inception的split-transform-merge 思想,可扩展性有了很大改善,在增加准确率的基础上不改变模型的复杂度。
2.2 模型的理解

该文章构建了一个基本“Block”,并在此“Block”基础上引入了一个新的维度“基数”。深度网络的另外两个维度分别为宽度和深度。它与Inception 模块非常类似,都遵循“拆分-转换-合并“的范式,区别只在于ResNeXt 这个变体中,不同路径的输出通过将相加在一起来合并,并且所有路径共享相同的拓扑。左边是标准残差网络“Block”,右图是作者引入的“Block”。这新的Block的优势在于达到大型、紧凑深度网络的准确率的同时,降低模型的计算复杂度。Fig.1右边就是就是采用split-transform-merge策略构建的。
实验表明,通过增加“基数”提高准确度相比让网络加深或扩大来提高准确度更有效。基数是衡量神经网络在深度和宽度之外的另一个重要因素。
作者总结了以下两个设计原则:
(1)如果“Block”输出的特征图的空间尺寸相同,那么它们具有相同的超参数;
(2)如果特征图的空间维度减半,那么Block的宽度加倍。
除此之外,所有的“Block”具有相同的拓扑结构。

该模型有以上等价的形式(Fig.2)——下文具体讲述如何理解。
2.3 模块机理


将其中的w_i*x_i替换成更一般的函数,这里用了一个很形象的词:Network in Neuron,式子如下:

其中C就是 cardinality,T_i有相同的拓扑结构(本文中就是三个卷积层的堆叠)。
看上图Fig.2,这里作者展示了三种相同的 ResNeXt blocks。Fig2.a 就是前面所说的aggregated residual transformations。 Fig2.b 则采用两层卷积后 concatenate,再卷积,类似于 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构。Fig2.c采用的是grouped convolutions,这个 group 参数就是caffe的卷积层的 group 参数,用来限制本层卷积核和输入channels的卷积,最早应该是 AlexNet 上使用,可以减少计算量。这里 Fig2.c 采用32个 group,每个 group 的输入输出 channels 都是4,最后把channels合并。这张图的 Fig2.c 和 Fig1 的左边图很像,差别在于Fig2.c的中间 filter 数量(此处为128,而Fig.1中为64)更多。
相应的残差函数可以写为:

其中,y是输出。
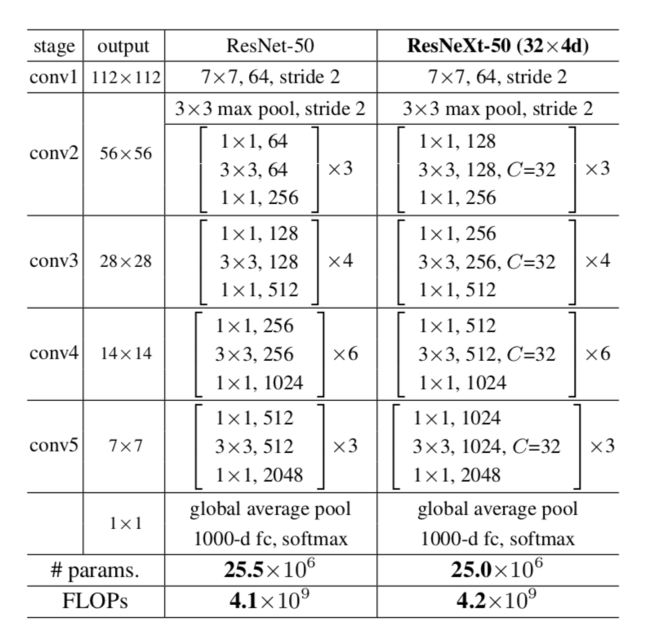

表1列举了ResNet-50 和 ResNeXt-50 的内部结构,最后两行说明二者之间的参数复杂度差别很小。表2主要列举了一些参数,来说明 Fig.1 的左右两个结构的参数复杂度差不多。第二行的d表示每个path的中间channels数量,最后一行则表示整个block的宽度,是第一行C和第二行d的乘积。
2.4 模型的效果
2.4.1 在ImageNet-1K上效果
在实验中ResNeXt和ResNet-50/101的区别仅仅在于其中的block,其他都不变。实验结果:相同层数的ResNet和ResNeXt的对比:(32*4d表示32个paths,每个path的宽度为4,如fig3)。实验结果表明ResNeXt和ResNet的参数复杂度差不多,但是其训练误差和测试误差都降低了。


该表3说明了增加Cardinality和增加深度或宽度的区别,增加宽度就是简单地增加filter channels。第一个是基准模型,增加深度和宽度的分别是第三和第四个,可以看到误差分别降低了0.3%和0.7%。但是第五个加倍了Cardinality,则降低了1.3%,第六个Cardinality加到64,则降低了1.6%。显然增加Cardianlity比增加深度或宽度更有效。
2.4.2 在ImageNet-5K上的效果

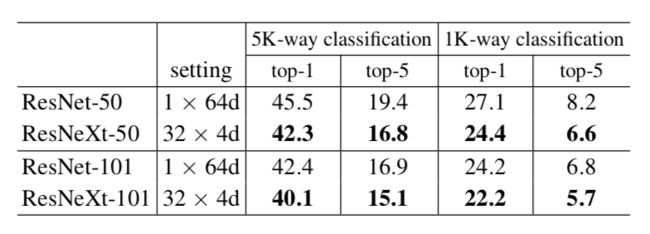
从Fig.4中观察在ImageNet-5K数据集中,ResNeXt-101的错误率比ResNet-101低。从Table 4中观察到在imageNet-5K数据集中训练得到的模型,ImageNet-1K(22.2%/5.7%)上的分类效果比在imageNet-1K数据集上训练得到的模型(21.2%/5.6%)的分类效果要好。
2.4.3 在CIFAR上的效果


Fig.6与Table 6表明本文提出的模型优于Wide ResNet。该方法在CIFAR-10上的测试错误率达到3.58%,在CIFAR-100达到17.31%。
2.4.4 在COCO对象检测的效果

结果显示ResNeXt-50效果均有提升而没有增加复杂性。 ResNeXt-101显示出较小的改进。 作者认为更多的培训数据将导致更大的差距,正如在ImageNet-5K上所观察到的。ResNeXt已经被Mask R-CNN采用,它在COCO实例分割和对象检测任务上实现了最新的结果。
3. 总结
文章的创新点在于用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。