姓名:谢童 学号:16020188008 转自微信公众号 新智元
【新智元导读】2018年的最后一天,回顾 AI 技术发展,纵览一年 AI 事件。新智元创始人兼CEO杨静女士寄语:2019跨年之际,新智元继续与您一起探索不一样的天际线和地平线;穿越时空隧道,创造奇迹,突破 AI 极限!新智元感恩每一位 AI 智库专家、合作伙伴和人工智能产业链用户!预祝2019新年快乐!
再过几个小时,我们就将进入2019年。
新智元从2015年9月成立至今,一直聚焦AI行业,追踪业界、技术、学界的前沿发展。2018年12月,新智元微信公众号AI全产业链用户达35万。
上周,新智元发布了《2018,一文看尽 AI 发展真相》的上篇,在 state of the art.ai 网站收集的同行评议论文基础上,对目前为止 AI 在计算机视觉 (CV) 和自然语言处理 (NLP) 方面的 state-of-art 做了回顾。
在下篇当中,我们将介绍迄今 AI 在游戏、知识图谱和知识库、语音以及程序归纳和程序综合 (Program Induction & Program Synthesis) 方面取得的最优成果。最后,按照时间顺序,以全年AI事件纵览收尾。
游戏:AI攻克最难雅利达游戏,AlphaGo更强大!
说到“游戏”,自然是强化学习,有经典的雅达利 (Atari) 游戏和以国际象棋、围棋为代表的抽象策略游戏。
雅利达游戏:《蒙特祖玛的复仇》超越人类专家平均水平
雅达利游戏种类繁多,但基本都已被 AI 攻克。除了几个特别难的,比如:
《蒙特祖玛的复仇》要求玩家找到金字塔里的宝藏,中途有各种陷阱和机关
《陷阱》(PITFALL!) 玩家需要穿越丛林,克服众多危险,在20分钟内找到32个宝藏
《私人侦探》(PRIVATE EYE) 玩家需要追踪线索,追回被犯罪分子偷走的物品,并将罪犯逮捕归案
上述游戏对人类而言都是不小的挑战,在 AI 界则被称为“强化学习 AI 噩梦或试金石”。在这种稀疏环境奖励游戏中,使用基础的贪婪算法几乎无法过关,因为在分离奖励的帧数中,AI 可能的动作轨迹呈指数级增长。例如,在《蒙特祖玛的复仇》中,获得第一个环境奖励大约需要移动100步,也就是10018个可能的动作序列。即使随机遇到奖励,如果这个信号在特别长的时间范围内存在,那么强化学习算法也难以稳定地学习。
2018年5月,DeepMind 宣布让 AI 在《蒙特祖玛的复仇》、《陷阱》和《私人侦探》这三大超难雅利达游戏中首次令人信服地超越人类水平,方法是让 AI 观看人类玩这些游戏的 YouTube 视频。
DeepMind 表示,他们提出了全新的自监督目标,让智能体能从视频像素中学习域不变表征,还描述了一种少数据模仿 (one-shot imitation) 机制,在整个空间嵌入检查点来指导智能体进行探索。“将这些方法与标准的 IMPALA 智能体结合,我们展示了首个在《蒙特祖玛的复仇》《陷阱》以及《私人侦探》上具有人类水平的 AI。”

雅利达游戏《蒙特祖玛的复仇》,因其稀疏奖励环境,被誉为最难雅利达游戏之一,2018年首次被AI 玩过超越人类水平。
DeepMind 的结果发表几周后,OpenAI 也发布博文,描述了另一种训练智能体完成蒙特祖玛复仇第一关的方法。这种方法也依赖于人类的演示,但与 DeepMind 的稍有不同。这里有详尽的技术分析。
2018年11月底,Uber 在官方博客上介绍了他们提出的 Go-Explore 算法,不仅轻松通关蒙特祖玛,而且玩到了159 级,获得超过 200 万分,平均得分超过 40 万分!
Go-Explore 无需人类演示,智能体从领域知识 (domain knowledge) 中学习,凸显了算法利用最小先验知识的能力。即使没有任何领域知识,Go-Explore 也在蒙特祖玛中得到超过 3.5 万分,是当时最优水平的三倍多。
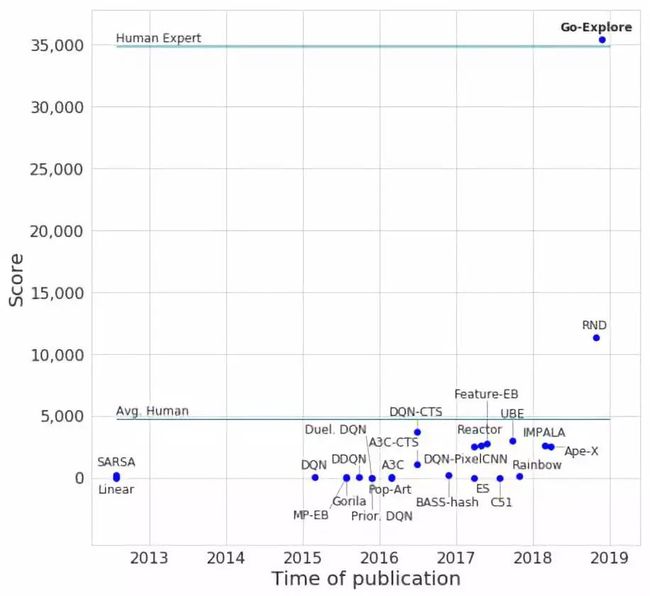
无领域知识的 Go-Explore 与其他强化学习算法在《蒙特祖玛的复仇》中比较。图中的每一点都代表了不同算法的得分。Go-Explore 平均得分为 35410,是之前最好成绩的 11347分的 3倍多,略高于人类专家平均水平的 34900分!
策略游戏:AlphaZero自弈胜率大涨16.5%
2018年12月7日,DeepMind的最强棋类算法 AlphaZero 作为 Science 封面论文发表,正式引入学界和公众的视野。去年底,AlphaZero 横空出世,将日本将棋、国际象棋和围棋统统拿下:从零开始训练,2小时击败最强将棋AI,4小时击败最强国际象棋AI,8小时击败最强围棋AI (李世石版AlphaGo)。
就在几天前,DeepMind 又在 Arxiv 贴出文章,用贝叶斯优化将人工调参改为自动,AlphaGo自我对弈的胜率从50%涨到66.5%,进一步刷新了AI围棋实力,而其见解将有助于开发具有MCTS的新版本的AI对弈智能体。
作为优化步骤函数的观察值和最大预期胜率的典型值
语音:中文语音识别准确率达到新高度
语音识别
2017年8月底,微软语音对话研究小组在Switchboard语音识别任务中,将错误率从之前的 5.9% 再一次降低到 5.1%,达到当时的最先进水平。微软全球技术Fellow、语音对话研究负责人黄学东在微软官方博客上称,这意味着微软创造了一种技术,可以在对话中识别词语,且与人类专业的速记员水平相当。
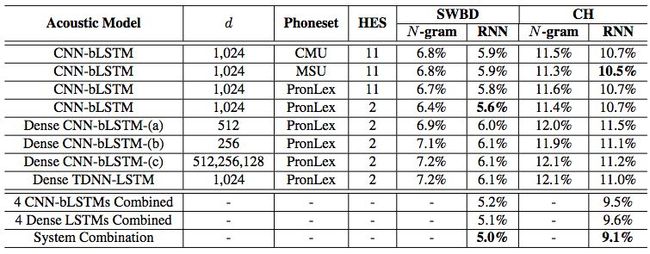
2018年,根据一篇发表在Arixv上的论文,The CAPIO 2017 Conversational Speech Recognition System,Kyu J. Han 等人宣布使用 Dense-LSTM 方法,在行业标准的NIST 2000 Hub5英语评估集上实现当前最佳性能。作者在论文中指出,他们还提出了一种声学模型自适应方案,通过在三个不同电话机上训练的5个系统上的RNN-LM重新校正和点阵组合,其CAPIO 2017语音识别系统分别在语音数据集 Switchboard 和 CallHome 上获得了5.0%和9.1%的词错率,这两者都是迄今英语语音识别方面文献汇报的最好的成绩。
在中文语音识别方面则出现了一个令人比较意外的结果,AI初创公司依图科技在年底宣布,他们在全球最大的中文开源数据库AISHELL-2中,依图短语音听写的字错率(CER)达到3.71%,相比原业内领先者提升约20%,大幅刷新现有纪录。
AISHELL-2是AISHELL Foundation和希尔贝壳创建的开源数据库,含有1000小时中文语音数据,由1991名来自中国不同口音区域的说话者参与录制,经过专业语音校对人员转写标注,通过了严格质量检验,数据库文本正确率在96%以上,录音文本涉及唤醒词、语音控制词、智能家居、无人驾驶、工业生产等12个领域。
扬声器测量(Speaker Diarization)
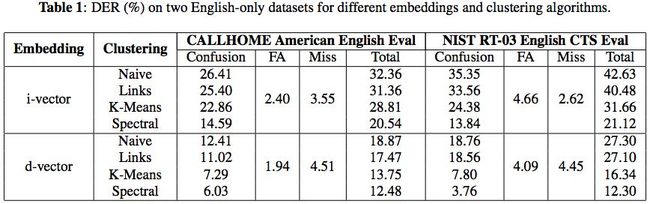
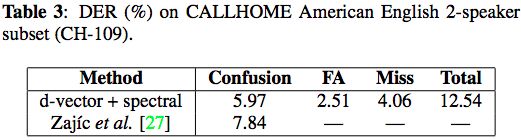
语音领域顶会 ICASSP 2018,谷歌和CMU团队发表论文,汇报了他们在扬声器测量 (Speaker Diarization) 方面的进展。具体说,作者将基于LSTM的d矢量音频嵌入与最近在非参数聚类中的工作相结合,从而获得了最先进的扬声器二值化系统。
扬声器测量是指根据说话者身份将输入音频流划分为同类段的过程。它可以通过将音频流结构化为扬声器转弯来增强自动语音转录的可读性,并且当与扬声器识别系统一起使用时,通过提供说话者的真实身份。
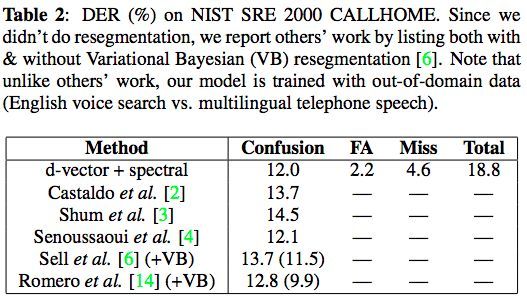
在三个标准公共数据集 (见下) 评估结果表明,基于d矢量的二值化系统与传统的基于i-vector的系统相比具有明显的优势。在使用语音搜索领域外数据进行训练的情况下,模型在NIST SRE 2000 CALLHOME上实现了12.0%的错误率。
知识图谱和知识库
聚类
在聚类 (Clustering) 方面,根据 stateoftheart 网站,AI 做到最好的成绩是 Mukherjee 等人在 2017 年 NeurIPS 论文《论网络数据的聚类》中得到的。作者将网络概括为一个高维特征向量,然后对这些特征向量进行聚类。他们提出了两种方法,分别适用于有节点的网络和没有节点的网络。

在一系列结果中,错误率最低为 0 的情况下时间 25 秒,时间最短 2.7 秒的情况下错误率 0.1。
图 (Graph) 生成
至于图 (Graph) 生成,则是 IBM 研究院的 Tengfei Ma、Jie Chen 和 Cao Xiao 在今年 NeurIPS 发表的论文Constrained Generation of Semantically Valid Graphs via Regularizing Variational Autoencoders中,他们提出了一个变分自编码器的正则化框架,作为实现语义有效性的第一步。然后,专注于图的矩阵表示,并规范解码器的输出分布,以鼓励满足有效性约束。实验结果证实,与此前文献报道的其他方法相比,我们的方法在采样有效图的准确率要高得多。
具体说,他们所提出的方法,在 QM9 与 ZINC 两大数据集上,分别与此前最好结果相比,都得到了显著提升。
链路预测
今年的ICLR,Rajarshi Das 等人提出了一种名叫 Minerva 的算法,有效解决了回答关系已知但只有一个实体的问题。作者提出了一种神经强化学习方法,能够学习如何根据输入的查询条件在图中导航,从而找到预测路径。这种方法在几个数据集上获得了最先进的结果,明显优于先前的方法。


程序归纳与程序综合
在发表于今年 ICLR 的一项工作中,佐治亚大学和微软研究院的研究人员联合提出了一种叫“神经引导演绎搜索”(NGDS)的方法,这是一种混合程序综合技术,结合了符号逻辑和统计模型的优点。因此,NGDS 能通过构造生成满足所提供规范的程序,并且很好地概括了类似于数据驱动系统的看不见的样本。

论文作者提出的这一的技术,有效地利用演绎搜索框架,将神经元件的学习问题简化为简单的监督学习场景。此外,这可用现实世界数据,又可以利用强大的递归神经网络编码器。与最先进的系统相比,通过综合精确的程序,整体速度提高了12倍,准确率68.5%。
当然,对于程序综合与程序生成,在条件程序生成领域,还必须提一下今年的EMNLP,Murali 等人提出的一个模型,结合深度学习和程序综合技术,能够自动学习将简单的手绘图转换为用 \LaTeX 图形程序。
论文作者学习了一个卷积神经网络,后者能提出解释图的合理绘图基元,可以纠正深层网络所产生的错误,通过使用类似的高级几何结构来测量图形之间的相似性,并推断出图程序。总之,这是朝向智能体从感知输入中归纳出有用的、人类可读的程序又一进步。

2018 年人工智能大事件回顾
看完技术在聚焦产业。尽管AI技术为谷歌和Facebook这样的大公司的盈利颇丰,但今年,这些公司已经越来越意识到AI技术的一些陷阱:比如AI很容易陷入偏见,缺乏固定的技术道德准则,而且,过早地将AI技术引入现实世界可能是浪费时间。
今年关于AI技术应用的争议中,有很大一部分是由Uber自驾车事故致行人死亡事件引起的。此外,人工智能技术可能存在滥用的报道也引发了新的关注。
以下是新智元呈现的2018年AI大事件年度盘点,其中一些事件凸显出当前AI技术中存在的重要问题:
1月
中国公司正在占领CES,官方数据显示,单是名字中含有“深圳”的参展公司就有482家,占了将近10%,算上其他来自中国的公司,2018年的CES已经成为“中国消费电子展”。
教育部:人工智能进入全国高中新课标,2018秋季学期执行
2月
美国国会举行关于AI技术的听证会,发言人警告称,AI领域长期存在偏见,特别是对有色人种的偏见。
工业界和学术界专家于2月的一份报告中强调了AI技术在数字、物理和政治领域可能被武器化,并存在被滥用的多种方式。
研究人员Joy Buolamwini和Timnit Gebru发表论文,显示AI面部识别的准确性在白人和有色人种间存在巨大差异。
谷歌重拳开放Cloud TPU,GPU最强对手上线
3月
Uber实验性自动驾驶汽车在亚利桑那州撞死了一名行人
中国两会:总理报告再提新一代人工智能
体系结构宗师John Hennessy、David Patterson获图灵奖
【新智元峰会】德国AI教皇盛赞中国人工智能,25位AI领袖强势打造中国新智极
4月
Facebook 20 亿用户数据均可能泄露,扎克伯格仍不打算辞职
5月
谷歌首次出现集体请辞,抗议军方合作项目,300多名学者发联名信
提升AI公平性的工具开始开发
Facebook发布用于识别数据偏见的工具,并开始测试相关算法
6月
谷歌中止Maven军事合作,曾打算帮国防部监控地球建筑
7月
马斯克联名2000多AI专家誓言禁绝杀人机器人
8月
Open AI完虐Dota2准职业玩家,推塔如割草
六项世界第一!余承东发布7纳米“超级恐怖”芯片,麒麟980让世界颤抖
亚马逊Alexa和微软Cortana完成整合,挑战苹果Siri
9月
更多旨在提升AI公平性的工具面世,美国国会进一步关注AI公平性问题
Google和IBM陆续发布了用于识别数据偏见的工具。
有国会议员致函FBI和平等就业机会委员会等联邦机构,询问它们是否制定了旨在缓解AI技术偏见的工具或政策。
阿里成立独立芯片公司——平头哥
AI world 2018 世界人工智能峰会在北京举行

10月
亚马逊打击有偏见AI的报道。路透社报道称,亚马逊正在测试一种对女性存在偏见的AI招聘工具。
NLP历史突破!谷歌BERT模型狂破11项纪录,全面超越人类
MIT宣布10亿美元成立全新计算与人工智能学院,重塑70年来结构
11月
新闻联播8分钟:中央强调AI要有“头雁”效应,要勇闯无人区
北大建立人工智能新校区,规划用地1025亩
谷歌无人车老大承认遥遥无期,全自动驾驶寒冬将至?
12月
微软发表官方博文,推动对面部识别算法的偏见进行监管。
Science:AlphaZero达成终极进化体,史上最强棋类AI降临
专家表示,AI背后社会科学基础并不像宣传的那样扎实,并提出了监管AI技术的意见。
谷歌翻译声称,已在翻译中修复可能存在偏见的性别代词
欧盟公布AI技术道德准则草案,同时实现了AI投资200亿美元的目标
AI Index 2018 公布
世界最大AI创新应用园揭幕:首钢老厂区将变身新北京“AI World”
总体来看,2018年AI整个行业在中美及世界其他地区仍然呈现蓬勃发展的态势,但各国立法机构和行业团体对“奇点降临”和“终结者末日”等噱头话题的关注明显降温,而更多关注AI技术的贸然落地可能给政府和私营部门带来的潜在危害。
由于偏见或缺乏道德上的顶层设计,公众需要对AI的潜在缺点有更深入的了解,在这种思路的指引下,将AI研究快速转化为AI产品的路线,可能会在未来遇到更大的阻力。
在新智元年终微信群访谈“独见”中,小 i 机器人CEO朱频频表示,今年最大的 AI 产业事件是11月19日,美国商务部工业与安全局提出了一份针对关键技术和相关产品的出口管制框架方案,文件列出了14个考虑进行管制的领域,包括生物技术、人工智能、数据分析、量子计算、机器人、脑机接口等前沿技术。
“无论是长期的积极影响还是短期的负面影响,[对中国AI] 影响都是深远而巨大的。”朱频频说。
作为语音与自然语言处理领域的专家,朱频频认为谷歌BERT模型的推出是2018年最重要的学术新闻,“未来十年是NLP的黄金十年,即使不出现BERT模型,也会出现其他有效的NLP模型,”朱频频表示:“因为认识智能的发展是未来发展的趋势。”
此外,情感计算和交互以及AIoT等方面的发展也值得期待。