最近一直有研究solr源码,所以也做一个分享吧,网上的话对SolrCloud的分享比较少,后续会对SolrCloud的分布式特性做一个介绍,如果有时间的话。由于没有牵扯到代码,所以只是流程上的分析。后续如果有时间的话,再对代码做一个详细的解释。请多多指出批评意见。
1. 首先是solrcloud的结构
这个在网上差不多都能找到相应的分析,基本就是这个概念,没有更多新的东西。
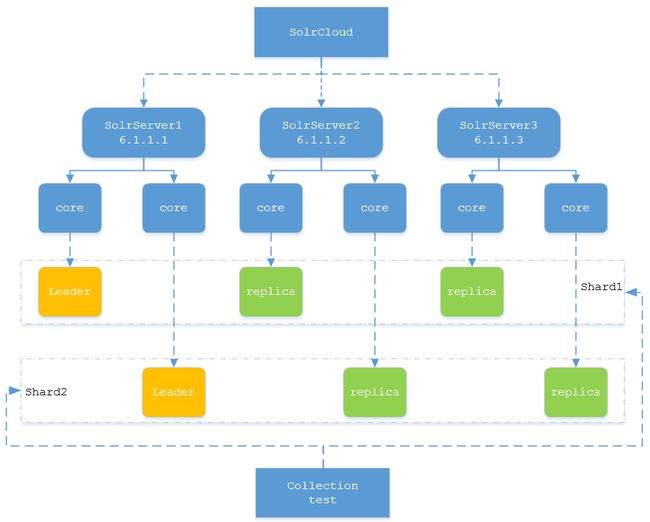
图中就是一个collection基本结构的展示。虚线的部分可以理解为一个逻辑结构,实线部分就是一个物理结构,一个SolrServer就是一个完整的solr结构,可以进行单独的运行,在cloud的逻辑中使结合zk的使用,实现一个分布式的功能,其中比较重要的一点就是OverSeer的结构,后续会进行详细说明。根据概念可以知道,一个shard只保存一份数据,leader和replica之间进行数据的同步(PeerSync以及Replication,后续也会进行说明),存储的数据是相同的。
2. colction级别的一个请求下发
请求下发的时候,就要用到OverSeer这个关键的概念了,因为每个SolrServer都是一个完整的solr代码在运行,那么既然有cloud的特性就一定需要,单个节点的相互协调,Overseer就起到了这个这作用。
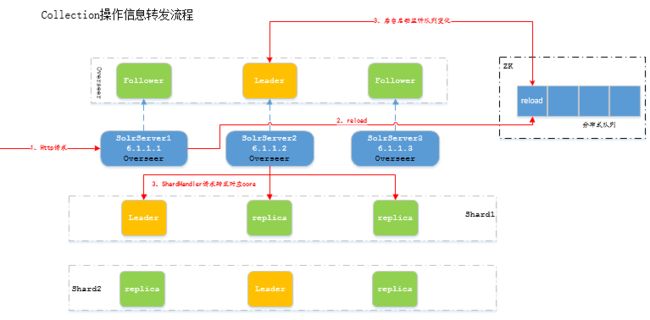
简单做一下解释,就是cloud的单个节点启动的时候,各个节点的OverSeer会在zk进行注册,然后需要选出leader做集中做分布式系统的消息处理。代码中使有一个while循环,一直等待着分布式队列的数据输入。一旦有节点的插入就开始处理相关数据,图中是以reload的请求为例。
3. 索引添加流程
索引添加的时候,需要考虑的几个重要的问题。
1、各个replica之间的数据同步问题
2、分布式请求转发的问题
3、为了保证数据的安全性,日志如何处理
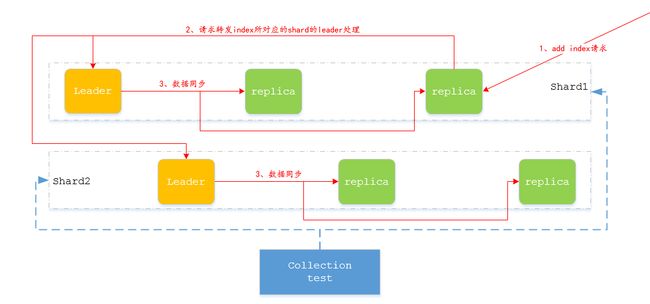
下面对问题进行简单的分析,此部分的分布式请求和solr查询的流程类似,所以在查询流程上详细展开。
1、添加索引时会进行TranssactionLog的持久化写入,出现意外情况的时候可进行恢复。
2、tlog通过一个version信息进行标示,为主节点写入数据的时间戳,再转发给子节点。
3、如果是replica节点接收到数据会转发给Leader节点进行处理。
4、leader节点接收到数据会转发给相应的replica。
5、solr内部使用hash算法保证index的平均分配,所以转发时只转发给目标shard。
4. 索引查询流程
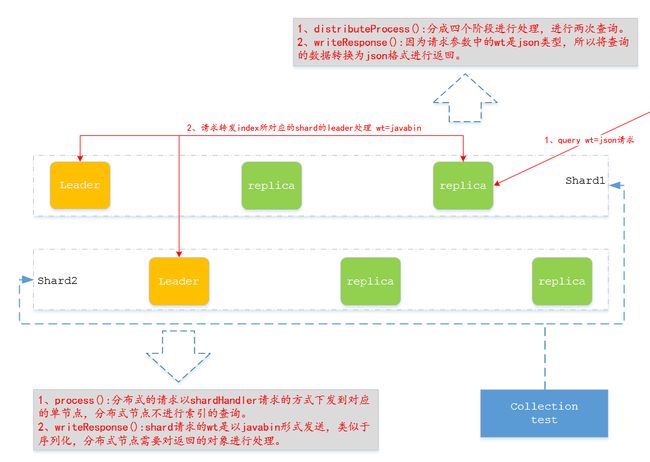
查询流程在分布式的思维上与添加流程类似。SolrCloud提供的就是一个分布式的结构,所以solr的整体框架很大程度上就是提供一个分布式的完整性的实现。
分布式节点:
1、分布式节点流程上只处理,分布式请求的下发和数据的汇总。
2、请求的下发不是特定发往leader节点而是通过一个LB进行分发,因为一个shard的所有节点都保存相同的数据。
3、分布式的流程上分为四个阶段,第三个阶段负责数据的查询,向下发送查询请求。如果row为默认的10,也就是在每个shard查询10条数据,然后分布式节点会根据返回的score进行合并成最终的10个id,这个阶段获去到的数据只有一个id和score,不包含其它属性的数据。然后进行第四个节点的RETURN_FIELDS的请求下发,这次会将对应的*ids*发送,只查询这些id对应的所有数据。
4、writeResponse再对第四个阶段返回的数据,根据wt的类别写入到最终的response中,进行返回。
本地节点:
1、第一次接收到的请求是查询符合条件的doc,QueryComponent的process方法中进行处理。返回的数据是DocListAndSet,只包含id和score。再经过writeResponse方法构造最终的response,以javabin的形式进行返回。
2、第二次请求的时候,请求参数中有ids这个属性,在process处理之后,也只是一个DocListAndSet。wirteResponse阶段会对docList进行遍历,*关注一下DocStream类的next方法,会对id再进行一次查询*,这次才生成最终返回的SolrDocumentList,包含了所有的数据信息。不是很明白为什么不在查询的时候直接返回,而是在writeResponse的时候再一次查询,但是代码流程就是这样。最终的返回值就以javabin的形式写入到response,交给分布式节点进行处理。
3、总结一下,本地节点是要进行两次查询。
5. 添加replica流程
添加replica目的就是创建一个core备份,重点还是在数据恢复上。
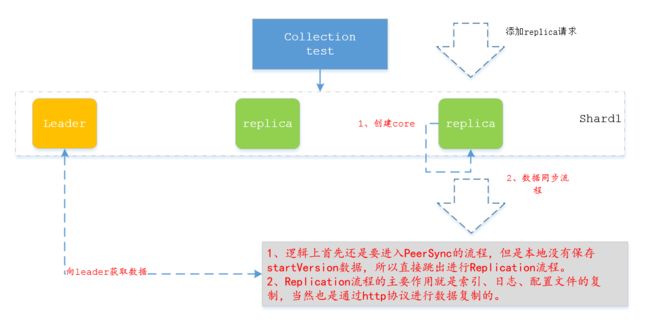
1、PeerSync流程主要是用于leader节点数据不多的情况,进行数据的恢复,依靠日志就可以进行恢复。
2、如果数据较多的情况下,就直接进行Replication操作,这部分的逻辑上还是有点复杂的。可以关注一下ReplicationHandler的http请求处理方式。这里面包含了获取待同步的文件列表,获取version信息等等的请求回复处理流程。
3、如果在recoverying的时候还有数据的添加操作,replication结束之后还会进行tlog的replay操作,将恢复时未写入的这部分数据进行写入。
4、创建core的流程就是走一个分布式的请求,重点还是在数据恢复上。当然还有一些其他的选举操作等等。