由于RxJava1.x版本已经在2018.3.31不再更新了,因此本文是基于的2.x版本的源码。至于2.x和1.x有什么不同可以去他们Github主页了解。
RxJava 中常用的几种线程,通过 Schedulers 入口创建
- newThread():一个新线程
- io():异步IO线程
- computation():计算密集型线程
还有一个Android中主线程(UI线程) - AndroidSchedulers.mainThread()
newThread()
通过Schedulers来调用(精简后):
#Schedulers.java
public static Scheduler newThread() {
Scheduler default = new NewThreadScheduler();
return default;
}
返回的 NewThreadScheduler,继承自Scheduler,NewThreadScheduler内部里有一个自定义的ThreadFactory:RxThreadFactory,给线程起了名字并且设置了优先级。
为什么要使用线程工厂来创建线程呢? 目的有4个:
- 可以给线程起名字(方便debug/profile时做分析)
- 可以选择线程类型,daemon or user thread
- 设定线程优先级
- 按需处理未捕获的异常
#NewThreadScheduler.java
public final class NewThreadScheduler extends Scheduler {
...
...
@Override
public Worker createWorker() {
return new NewThreadWorker(threadFactory);//此行打断点A
}
}
NewThreadScheduler 中最重要的方法是重写 createWorker() 返回了 NewThreadWorker,2.x把原先1.x的Subscription 重命名为 Disposable 了,因此现在的 NewThreadWorker 是实现自 Disposable 接口.
#NewThreadWorker.java
public class NewThreadWorker extends Scheduler.Worker implements Disposable {
private final ScheduledExecutorService executor;
public NewThreadWorker(ThreadFactory threadFactory) {
executor = SchedulerPoolFactory.create(threadFactory);//断点A的调转
}
}
SchedulerPoolFactory 以工厂模式来生成ScheduledExecutorService(一个单线程的线程池),同时把每个单线程的线程池放入到一个集合ConcurrentHashMap中,并且启动了一个PURGE线程(也是个ScheduledExecutorService)通过定时任务来遍历这个集合中的executors,如果是isShutdown == true就把它从集合中删除,如果没有shutdown就调用purge()方法,但是这个purge方法只能用于移除队列中已被取消的通过submit()转化的Future类型任务。
ScheduledExecutorService extends ThreadPoolExecutor implements ExecutorService,是一个可以执行定时任务的线程池。
#SchedulerPoolFactory.java
public final class SchedulerPoolFactory {
//内部维护一个放创建ScheduledExecutorService的HashMap
static final Map POOLS =
new ConcurrentHashMap();
//断点A的最终调转方法:create(),每次都生成新的含有单线程的线程池并且放入POOL里,
public static ScheduledExecutorService create(ThreadFactory factory) {
final ScheduledExecutorService exec = Executors.newScheduledThreadPool(1, factory);
ScheduledThreadPoolExecutor e = (ScheduledThreadPoolExecutor) exec;
POOLS.put(e, exec);
return exec;
}
//开启purge线程(非完整源码),此方法在SchedulerPoolFactory的static块中调用
public static void start() {
ScheduledExecutorService next = Executors.newScheduledThreadPool(1, new RxThreadFactory("RxSchedulerPurge"));
next.scheduleAtFixedRate(new ScheduledTask(), PURGE_PERIOD_SECONDS, PURGE_PERIOD_SECONDS, TimeUnit.SECONDS);
}
static final class ScheduledTask implements Runnable {
@Override
public void run() {
for (ScheduledThreadPoolExecutor e : new ArrayList(POOLS.keySet())) {
if (e.isShutdown()) {
POOLS.remove(e);
} else {
e.purge();
}
}
}
}
工厂生成了 ScheduledExecutorService 了以后回给 NewThreadWorker,NewThreadWorker主要重写了schedulerXXX(Runnable, delayTime, TimeUnit),方法内部根据delaytime将异步任务submit 或者 schedule 。
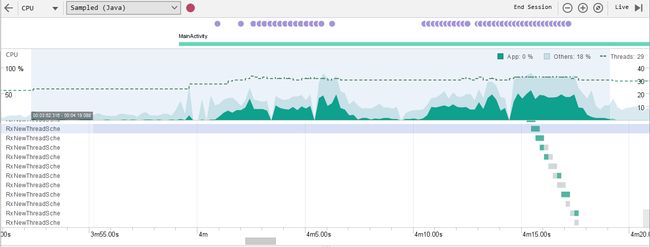
总结:打断点可以分析到,上层每次调用Schedulers.newThread()时,都会生成新的线程池,而创建线程池是很耗费内存开销的。打开Profile来观察下频繁地调用Schedulers.newThread()的CPU及内存情况,可以看到此时有29个线程存在,有一大部分是RxNewThreadScheduler,内存也很吃紧,而且如源码看到的那样,每个线程只执行一个任务而且也没有被及时清除。

io()
依然通过Schedulers来调用(精简后):
#Schedulers.java
public static Scheduler io() {
Scheduler default = new IoScheduler();
return default;
}
IoScheduler内部的缓存了threads in pool / thread in pools,可以对空闲thread进行复用,而不是像Schedulers.newThread()那样每次创建新线程来执行异步任务。
#IoScheduler .java
public final class IoScheduler extends Scheduler {
final AtomicReference pool;
...
public IoScheduler(ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
CachedWorkerPool update = new CachedWorkerPool(60, TimeUnit.SECONDS, threadFactory);
}
@Override
public Worker createWorker() {
return new EventLoopWorker(pool.get());
}
}
IoScheduler 的构造函数中创建了一个CachedWorkerPool,创建线程的方式是返回一个EventLoopWorker(CachedWorkerPool pool),也是继承自Scheduler.Worker,创建时传入了一个参数 pool.get(),参数的类型是CachedWorkerPool implements Runnable,get() 方法的代码如下
#IoScheduler .java
static final class CachedWorkerPool implements Runnable {
...
...
ThreadWorker get() {
if(allWorkers.isDisposed()) {
return SHUTDOWN_THREAD_WORKER;
}
while (!expiringWorkerQueue.isEmpty()) {
ThreadWorker threadWorker = expiringWorkerQueue.poll();
if (threadWorker != null) {
return threadWorker;
}
}
// No cached worker found, so create a new one.
ThreadWorker w = new ThreadWorker(threadFactory);
allWorkers.add(w);
return w;
}
}
CachedWorkerPool的获得是先试图从一个 expiringWorkerQueue 中取得,如果有缓存的 worker 则 poll()(队头的ThreadWorker,Queue:FIFO),如果没有(1.初始时 2.queque 中的 worker 都被 pool() 出去执行任务但是还没执行完)则新建一个ThreadWorker返回用以去执行异步任务。
expiringWorkerQueue 的类型是ConcurrentLinkedQueue
#IoScheduler .java
static final class EventLoopWorker extends Scheduler.Worker {
...
...
@Override
public void dispose() {
if (once.compareAndSet(false, true)) {
tasks.dispose();
//更新expirationTime +60s
threadWorker.setExpirationTime(now() + keepAliveTime);
//将更新完的threadWorker放回队列中
expiringWorkerQueue.offer(threadWorker);
}
}
}
而 CachedWorkerPool 内部维护了一个60秒执行的定时任务去循环 expiringWorkerQueue 中的 ThreadWorker ,将它的 expirationTime 跟当前时间比,如果小于当前时间(证明已过期)就将它从 expiringWorkerQueue 移除,且从 allWorkers 移除。ConcurrentLinkedQueue是一个线程安全的无边界的queque,如果并发的任务足够多且每个已缓存的 worker 都被 poll() 出去执行任务了,那么便会不断地 new ThreadWorker(),队列也会越来越长,通过定时任务来清理掉已经过期的worker避免占用内存。代码如下:
static final class CachedWorkerPool implements Runnable {
...
...
CachedWorkerPool(long keepAliveTime, TimeUnit unit, ThreadFactory threadFactory) {
ScheduledExecutorService evictor = Executors.newScheduledThreadPool(1, EVICTOR_THREAD_FACTORY);
Future task = evictor.scheduleWithFixedDelay(this, this.keepAliveTime, this.keepAliveTime, TimeUnit.NANOSECONDS);
}
@Override
public void run() {
if (!expiringWorkerQueue.isEmpty()) {
long currentTimestamp = now();
for (ThreadWorker threadWorker : expiringWorkerQueue) {
if (threadWorker.getExpirationTime() <= currentTimestamp) {
if (expiringWorkerQueue.remove(threadWorker)) {
allWorkers.remove(threadWorker);
}
} else {
break;
}
}
}
}
}
值得注意的是,由于ThreadWorker是继承自NewThreadWorker的,而每一个NewThreadWorker的是通过SchedulerPoolFactory生成并且用PURGE线程来对它们进行管理的。
通过Profile可以看到,缓存的线程得到了复用,且复用线程来执行任务时,CPU/MEMORY较上一种Schedulers.newThread()每次都创建新线程得到了很大的改善。
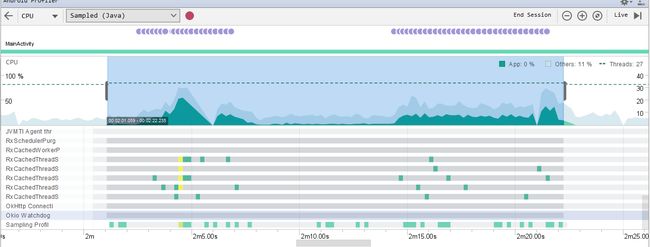
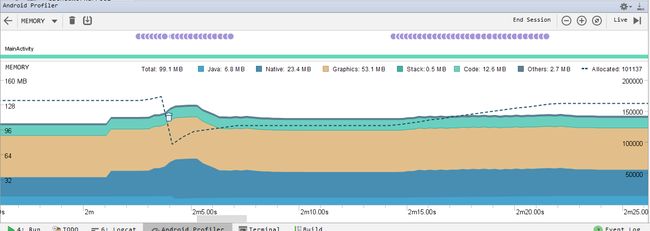
总结:如上面提到的,内部维护的ConcurrentLinkedQueue是一个线程安全但无边界的queque,如果并发足够多就会大量创建线程(池),因此这种方式如同它的名字Schedulers.io()一样,适合做非CPU敏感型的IO操作,比如访问文件系统、执行网络请求、数据库操作等等。
computation()
Schedulers.computation()是一个线程池,池内线程数(准确来说是单线程的ScheduledExecutorService)为CPU核数,且采用轮询调度分配算法(a round-robin fashion)来分配池中的线程。构造方法的代码如下:
#Schedulers.java
public static Scheduler computation() {
Scheduler default = new ComputationScheduler();
return default;
}
#ComputationScheduler.java
public final class ComputationScheduler extends Scheduler implements SchedulerMultiWorkerSupport {
...
static {
//CPU核数
MAX_THREADS = cap(Runtime.getRuntime().availableProcessors(), Integer.getInteger(KEY_MAX_THREADS, 0));
}
public ComputationScheduler(ThreadFactory threadFactory) {
//线程池的大小是固定的(CPU核数)
FixedSchedulerPool update = new FixedSchedulerPool(MAX_THREADS, threadFactory);
}
}
FixedSchedulerPool就这个线程池,源码很简单,创建MAX_THREADS个PoolWorker,并且 createWorker() 就是以轮询调度 pool 中 PoolWorker,去执行各种异步的即时/定时任务。
static final class FixedSchedulerPool implements SchedulerMultiWorkerSupport {
final int cores;
final PoolWorker[] eventLoops;
long n;
FixedSchedulerPool(int maxThreads, ThreadFactory threadFactory) {
// initialize event loops
this.cores = maxThreads;
this.eventLoops = new PoolWorker[maxThreads];
for (int i = 0; i < maxThreads; i++) {
this.eventLoops[i] = new PoolWorker(threadFactory);
}
}
//createWorker(worker)中,参数worker就是通过这个方法调用获得
public PoolWorker getEventLoop() {
int c = cores;
if (c == 0) {
return SHUTDOWN_WORKER;
}
// simple round robin, improvements to come
return eventLoops[(int)(n++ % c)];
}
}
总结:Schedulers.computation()的源码倒是挺简单的,如文档所说适合做一些CPU密集的操作,比如大量数据的解析和图片的处理等。
除了newThread()、io()、computation()外,RxJava还提供了
- single():一个单线程在主线程上执行
- trampoline():在当前的主线程执行,所有任务被排列等候上一个任务执行完再执行。
AndroidSchedulers.mainThread()
#AndroidSchedulers.java
public static Scheduler mainThread() {
Scheduler default = new HandlerScheduler(new Handler(Looper.getMainLooper()));
return default;
}
可以看到调用AndroidSchedulers.mainThread()是返回了一个以mainLooper为参数构造的HandlerScheduler。根据名字也能猜想的到是用的Handler机制来更新主线程UI。
createWorker() 方法返回了HandlerWorker(handler),这个handler就是刚才外部传进来的那个 new Handler(Looper.getMainLooper())。HandlerWorker源码如下:
private static final class HandlerWorker extends Worker {
private final Handler handler;
HandlerWorker(Handler handler) {
this.handler = handler;
}
@Override
public Disposable schedule(Runnable run, long delay, TimeUnit unit) {
//根据RxJavaPlugins的源码,这句只是把run包了一层try..catch..
run = RxJavaPlugins.onSchedule(run);
//ScheduledRunnable 是个内部类,主要功能就是当dispose()时执行handler.removeCallbacks(runnable)
ScheduledRunnable scheduled = new ScheduledRunnable(handler, run);
Message message = Message.obtain(handler, scheduled);
message.obj = this; // Used as token for batch disposal of this worker's runnables.
handler.sendMessageDelayed(message, unit.toMillis(delay));
return scheduled;
}
}