成果展示
详情页链接
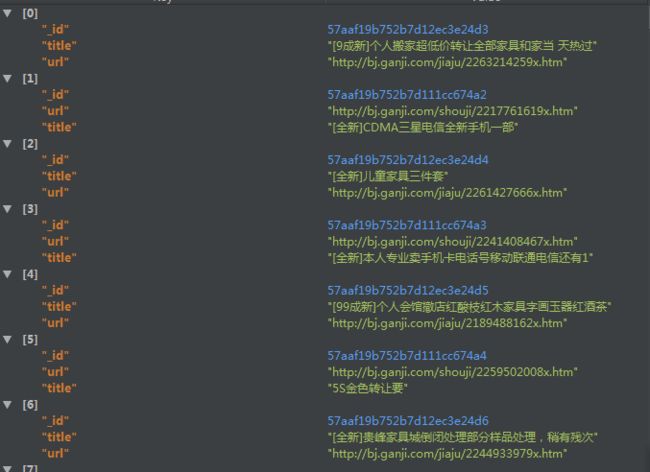
Paste_Image.png
商品信息

Paste_Image.png
我的代码
主函数(main.py)
#-*- coding:utf-8 -*-
from multiprocessing import Pool
from channel_extact import channel_list
from ganji_url_info import get_url_link,url_links,get_goods_info,goodsinfo
#断点续传判断
download_Y = [item['url'] for item in goodsinfo.find()] # 相关链接数据已下载至数据库
download_N = [item['url'] for item in url_links.find()] # 完整数据链接
Y = set(download_Y) #集合化
N = set(download_N) #集合化
need_to_download = N-Y # 还未下载的链接
#def get_all_links(channel):
# for page in range(1,101):
# get_url_link(channel,page)
if __name__ == '__main__':
# 利用多进程来爬取
#pool = Pool()
#pool.map(get_url_link,channel_list)
#pool.map(get_goods_info,need_to_download)
#pool.close()
#pool.join()
#不用pool,直接爬取
#for url in need_to_download:
# get_goods_info(url)
获取代理(My_proxies.py)
import requests
from bs4 import BeautifulSoup
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
}
def get_proxies():
url = 'http://www.xicidaili.com/nn'
proxies_list = [] # 存储代理IP
wb_data = requests.get(url, headers=headers).text
soup = BeautifulSoup(wb_data, 'lxml')
ips = soup.select('tr.odd > td:nth-of-type(2)') # ip地址
ports = soup.select('tr.odd > td:nth-of-type(3)') # 端口号
speeds = soup.select('tr > td:nth-of-type(7) > div > div') # 速度
connect_times = soup.select('tr > td:nth-of-type(8) > div > div') # 连接速度
# 信息合并,且筛选出速度快的代理
for ip, port, speed, connect_time in zip(ips, ports, speeds, connect_times):
if speed.get('class')[1] == 'fast' and connect_time.get('class')[1] == 'fast':
proxies_list.append('http://' + str(ip.text) + ':' + str(port.text))
else:
continue
print(proxies_list)
get_proxies()
取得分类链接 (channel_extact.py)
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
url = 'http://bj.ganji.com/wu/'
url_host = 'http://bj.ganji.com'
def get_channel_link(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
channel_links = soup.select('dl.fenlei > dt > a')
#print(channel_links)
for channel in channel_links:
print(url_host + channel.get('href'))
channel_list ='''
http://bj.ganji.com/jiaju/
http://bj.ganji.com/rirongbaihuo/
http://bj.ganji.com/shouji/
http://bj.ganji.com/bangong/
http://bj.ganji.com/nongyongpin/
http://bj.ganji.com/jiadian/
http://bj.ganji.com/ershoubijibendiannao/
http://bj.ganji.com/ruanjiantushu/
http://bj.ganji.com/yingyouyunfu/
http://bj.ganji.com/diannao/
http://bj.ganji.com/xianzhilipin/
http://bj.ganji.com/fushixiaobaxuemao/
http://bj.ganji.com/meironghuazhuang/
http://bj.ganji.com/shuma/
http://bj.ganji.com/laonianyongpin/
http://bj.ganji.com/xuniwupin/
'''
#以下三项分类格式与上面的不统一
#http://bj.ganji.com/qitawupin/
#http://bj.ganji.com/ershoufree/
#http://bj.ganji.com/wupinjiaohuan/
#get_channel_link(url)
取各分类链接列表并取得详情页信息(ganji_url_info.py)
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
import pymongo
import time , random
import requests.exceptions
client = pymongo.MongoClient('localhost', 27017)
ganji = client['ganji']
url_links = ganji['url_links_2']
url_links_zz = ganji['url_links_zz_2']
goodsinfo = ganji['goodsinfos']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
}
# http://www.xicidaili.com/wn
proxy_list =['http://121.193.143.249:80',
'http://42.159.251.84:41795',
'http://119.6.136.122:80',
'http://101.201.235.141:8000',
'http://118.180.15.152:8102',
'http://123.57.190.51:7777'
]
proxy = random.choice(proxy_list) # 随机选择代理
proxies = {'http': proxy}
#爬取网页链接
def get_url_link(channel, page, who_sells='o'):
try:
url_link = '{}{}{}/'.format(channel, str(who_sells), str(page))
wb_data = requests.get(url_link, headers=headers)
time.sleep(1)
soup = BeautifulSoup(wb_data.text, 'lxml')
except (requests.exceptions.ProxyError, requests.exceptions.ConnectionError,requests.exceptions.ReadTimeout) as e:
print('This is a error raise')
# 判断该网页是否有效
url_right = soup.select('ul.pageLink.clearfix') == []
if url_right:
pass
else:
data_1 = soup.select('li.js-item > a') # 赶集网相关链接信息所在
#print(data_1)
data_2 = soup.select('div.zz-til > a') # 58转转相关链接信息所在
# 将标题及对应链接存入url_links
for data in data_1:
if 'biz.click.ganji.com' not in data.get('href'):
url_links.insert_one({'title': data.get_text(strip=True), 'url': data.get('href')})
print({'title': data.get_text(strip=True), 'url': data.get('href')})
# 将标题及对应链接存入url_links_zz
for data in data_2:
url_links_zz.insert_one({'title': data.get_text(strip=True), 'url': data.get('href')})
# print({'title': data.get_text(strip=True), 'url': data.get('href').split('?')[0]})
#爬取详情信息
def get_goods_info(url):
try:
wb_data = requests.get(url, headers=headers, proxies=proxies).text
soup = BeautifulSoup(wb_data, 'lxml')
# 判断页面是否正常,若页面商品信息已删除或无效,跳过
if soup.select('div.error'):
print(url)
print('This page is Not Found!')
else:
title = soup.select('h1.title-name')[0].get_text() if soup.select('h1.title-name') else None # 标题
# 发布时间
if soup.select('i.pr-5'):
published = soup.select('i.pr-5')[0].get_text(strip=True)
else:
published = None
goods_types = soup.select('div > ul.det-infor > li:nth-of-type(1) > span > a')
goods_type = [i.get_text(strip=True) for i in goods_types] # 商品类型
locations = soup.select('div > ul.det-infor > li:nth-of-type(3) > a')
location = [i.get_text(strip=True) for i in locations] # 交易地点
price = soup.select('i.f22.fc-orange.f-type')[0].get_text() \
if soup.select('i.f22.fc-orange.f-type') else None # 价格
if len(soup.select('body > div > div > div.h-crumbs > div > a')) >= 3:
classfy = soup.select('body > div > div > div.h-crumbs > div > a')[2].text
else:
classfy = None
# 判断是否有该字段值
if soup.find(text='新旧程度:'):
degree = soup.select('ul.second-det-infor.clearfix > li')[0].get_text().split()[-1] # 新旧程度
else:
degree = None
#print(title,published,goods_type,location,price,classfy)
# 保存数据至数据库
# 爬取不到关键信息,信息不入数据库,待下次处理
if title or published or price:
goodsinfo.insert_one({'title': title,
'published': published,
'goods_type': goods_type,
'location': location,
'price': price,
'degree': degree,
'url': url, # 用于后面判断还未下载的链接,
'classfy': classfy
})
print(
{'title': title,
'published': published,
'goods_type': goods_type,
'location': location,
'price': price,
'degree': degree,
'url': url,
'classfy': classfy
}
)
else:
pass
except (requests.exceptions.ProxyError, requests.exceptions.ConnectionError,requests.exceptions.ReadTimeout) as e:
print('This is a error raise')
#url='http://bj.ganji.com/yingyouyunfu/2285918732x.htm'
#get_goods_info(url)
总结:
- 设计过程中不断的遇到问题,不断的在代码添加新功能解决,使程序尽量完善,主要问题如下:
|- 同一IP访问次数过多,被网站封了,设计了一个从代理网站获取代理IP的程序,来解决代理IP的问题;
|- 爬取过程中各种请求失效,超时等报错影响程序运行的连续,利用try-except,将此种报错获取,暂时跳过此网页,继续往下运行,后面再来处理这些未成功的网页
|- 加入了判断页面已失效(404)或 页面内容读取失败的判断,跳过这些页面,增加效率
|- 爬取的详情页链接中,存在许多跳转到转转的链接,将此类链接另外存于Mongo的另一集合中,因页面不同,如需获得这些链接的详情,需另设计函数来获取此类链接详情信息