10.1 groupby机制
将数据集进行分组并对各组应用一个函数通常书数据分析工作中的重要环节
"split-apply-combine"(拆分-应用-合并):对pandans等对象的某一个轴拆分成多个组,在对各个组应用函数,将各组得到的结果合并到一个新的对象中
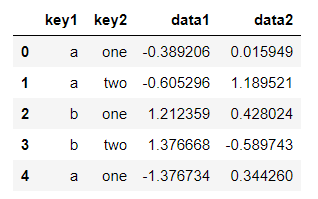
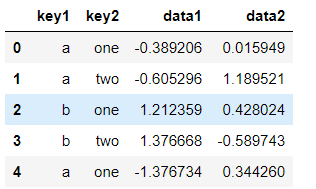
按照列key1进行分组,并求出每组的平均值
grouped=df.groupby('key1')
grouped.mean()
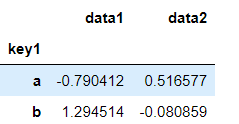
df
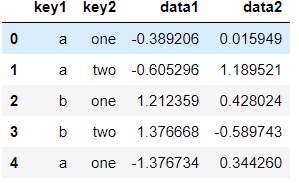
按照key1对data1的数据进行分组求平均值:
df['data1'].groupby(df['key1']).mean()

Series根据分组键进行聚合,再进行函数运算后返回一个新的Series对象
分组键也可以是列表
df['data1'].groupby([df['key1'],df['key2']]).mean()

实际上,分组键可以是任何长度适当的数组
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states,years]).mean()
直接对DataFrame进行分组聚合
df.groupby(['key1']).mean()
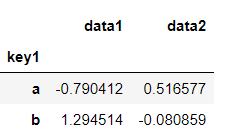
返回的结果中没有key2列,因为df['key2']不是数值列,所以被认为是‘麻烦列’,会在结果中自动滤除
返回各个分组大小的Series对象:groupby().size()
对分组进行迭代
for name,group in df.groupby(['key1','key2']):
print(name)
print('...seperator...')
print(group)

默认情况下分组是在0轴上进行的,也可以更改axis使之在1轴上传播。
如下,使得df根据每列的数据类型进行分组
grouped=df.groupby(df.dtypes,axis=1)
for key,value in grouped:
print(key)
print(value)
df.dtypes

选取一列或列的子集
通过字典或Series进行分组
传入字典,则可以在分组的同时,分配组名
mapping = {'a': 'red', 'b': 'red', 'c': 'blue',
....: 'd': 'blue', 'e': 'red', 'f' : 'orange'}
by_column=people.groupby(mapping,axis=1)
In [62]: by_column.sum()
Out[62]:
blue red
Joe 2.640600 0.535645
Steve -1.027999 -0.109327
Wes 1.114823 1.684028
Jim -1.004846 2.967557
Travis -0.546900 1.540500
通过函数进行分组
被当作分组键的函数会对所有索引都调用一次
people.groupby(len).sum()
根据索引级别分组
10.2 数据聚合
常见聚合运算

要使用自定义聚合函数只需将行数传入agg方法即可
grouped.agg(my_fun)
面向列的多函数应用
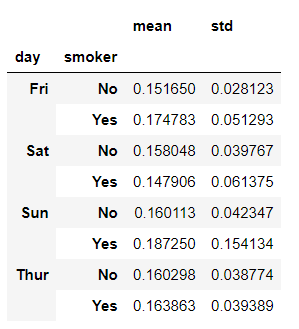
对于前面表的描述统计方法,可以函数名以字符串的形式传入(支持传入列表)
grouped_pct.agg(['mean','std'])
这样使得自定义函数可以和自带的聚合函数混合使用
也可由给聚合函数添加名字:传递元组
grouped_pct.agg([('平均值','mean'),('标准差','std')])
更方便的写法
functions=[('平均值','mean'),('标准差','std')]
grouped_pct.agg(functions)
10.3 apply:一般性的“拆分-应用-合并
相比agg,agg只是对每个分组使用聚合运算,而app则是将分组中的每块DataFrame对象进行运算,因此更具一般性。
使用范例:
def top(df,n=5,column='tip_pct'):
return df.sort_values(by=column)[-5:]
tips.groupby('day').apply(top)
groupby对象的apply方法:
groupby对象的每一块都是一个DataFrame对象,对其用apply就相当于将参数函数应用到每一个DataFrame块,因此要求参数函数也要能返回一个DataFrame对象。
apply和agg方法的区别:
agg方法是对一组数据执行的操作,而apply是对一块数据(DataFrame对象)执行的操作
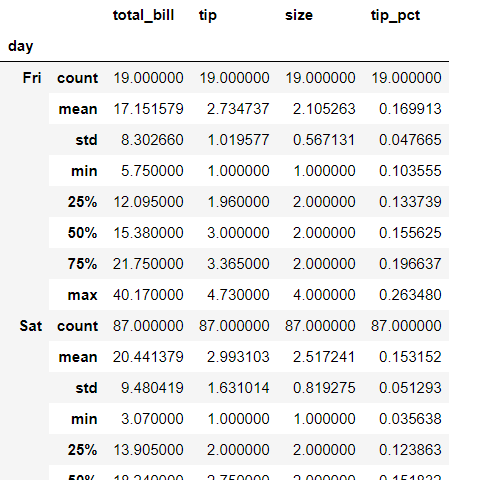
ps:实际上对groupby对象调用describe方法等价于:
tips.groupby('day').apply(lambda x:x.describe())
禁止分组键
使用参数:group_keys=Flase即可禁止分组键
tips.groupby('day',group_keys=False).apply(lambda x:x.describe())
分位数和桶分析
按数值区间分类
pd.cut
按个数区间分类
pd.qcut
示例1:对特定的分组填充不同的值
使用groupby+apply+填充函数
示例2: 随机采样和排列
创建一个德州扑克Series对象
suits=['H','S','C','D']
card_val=(list(range(1,11))+[10]*3)*4
base_names=['A']+list(range(2,11))+['J','K','Q']
for suit in suits:
cards.extend(str(num)+suit for num in base_names)
In [139]: deck.head(10)
Out[139]:
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
使用sample随机选取5张扑克:
deck.sample(5)
从每种花色中随机抽取两张牌
分组标准:卡名的最后一个字母即花色。
def fun(se):
return se.sample(2)
grouped=deck.groupby([x[-1] for x in deck.index])
grouped.apply(fun)
示例:分组加权平均数和相关系数
分组加权平均数
先分组,再对groupby对象调用average函数(可接收权重参数的mean)即可
分组相关系数
先分组,再对groupby对象调用corrwith
示例3:组级别的线性回归
10.4 透视表和交叉表
df.pivot_table:可以实现和groupby的相同功能,但简化了使用方式。
回到之前的消费的例子
In [254]: df.head(10)
Out[254]:
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.059447
1 10.34 1.66 No Sun Dinner 3 0.160542
2 21.01 3.50 No Sun Dinner 3 0.166587
3 23.68 3.31 No Sun Dinner 2 0.139780
4 24.59 3.61 No Sun Dinner 4 0.146808
5 25.29 4.71 No Sun Dinner 4 0.186240
6 8.77 2.00 No Sun Dinner 2 0.228050
7 26.88 3.12 No Sun Dinner 4 0.116071
8 15.04 1.96 No Sun Dinner 2 0.130319
9 14.78 3.23 No Sun Dinner 2 0.218539
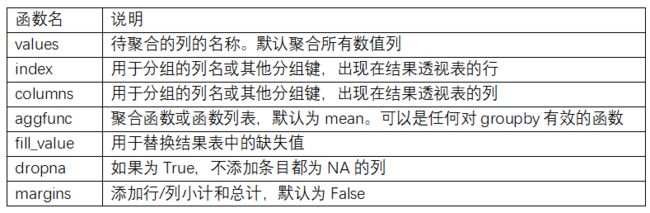
In [258]: df.pivot_table(['tip_pct','size'],index=['time','day'],columns='smoker')
Out[258]:
size tip_pct
smoker No Yes No Yes
time day
Dinner Fri 2.000000 2.222222 0.139622 0.165347
Sat 2.555556 2.476190 0.158048 0.147906
Sun 2.929825 2.578947 0.160113 0.187250
Thur 2.000000 NaN 0.159744 NaN
Lunch Fri 3.000000 1.833333 0.187735 0.188937
Thur 2.500000 2.352941 0.160311 0.163863
交叉表:crosstab
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表。