java基础解析系列(五)---HashMap并发下的问题以及HashTable和CurrentHashMap的区别
HashMap造成的死循环
resize分析
void resize(int newCapacity) {
472 Entry[] oldTable = table;
473 int oldCapacity = oldTable.length;
474 if (oldCapacity == MAXIMUM_CAPACITY) {
475 threshold = Integer.MAX_VALUE;
476 return;
477 }
478
479 Entry[] newTable = new Entry[newCapacity];
480 transfer(newTable);
481 table = newTable;
482 threshold = (int)(newCapacity * loadFactor);
483 }
void transfer(Entry[] newTable) {
489 Entry[] src = table;
490 int newCapacity = newTable.length;
491 for (int j = 0; j < src.length; j++) {
492 Entry e = src[j];
493 if (e != null) {
494 src[j] = null;
495 do {
496 Entry next = e.next;//用于判断后面循环是否继续
497 int i = indexFor(e.hash, newCapacity);
498 e.next = newTable[i];
499 newTable[i] = e;
500 e = next;
501 } while (e != null);
502 }
503 }
504 }
- 当hashmap大小超过阈值的时候,会进行扩容
- 看看第497到500行代码做了什么
- 取出原table中的一个Entry e
- 计算该Entry e的在新表的新下标,然后将新table该下标的Entry从新table拿出来,作为Entry e的next,再把将e放到newTable,newTable[i]=e
- 那么其实他做的就是在原table的Entry取出来,计算他的新下标,然后将这个Entry放入新的table,放入新table的时候,是做为链头,原来的Entry接在后面,实际上就相当于链表的头插法
并发情况下的resize
- put完成之后的结果

- 如果此时有两个线程,线程一完成resize,结果如下
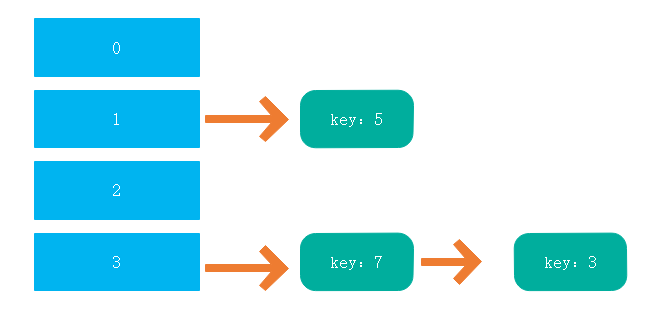
此前线程二之前只执行了第一层Entry
执行497到501的代码

- while(e!=null),此时e为7,e不为空,进入第二次循环
- next=e.next,即next为7的next(这个是判断后面循环是否终止),也就是3(线程一的结果),把7放到链表前头

- while(e!=null),此时e=3,e不等于null,进入第三次循环
next=e.next(这个是判断后面循环是否终止),即3的next,也就是null(造成后面循环终止)
放置3这个Entry,3的next设为7(e.next = newTable[i];),而上一步7的next是3,这样就造成了一个循环

- while(e!=null),e为null循环终止
- 那么如果此时get一个键,如果这个键的hash值刚好和3相同,那么这个时候就会遍历链表进行查找,而这个链表是个循环链表,就会造成死循环
- 因此hashmap并不是线程安全
HashTable
对比
public synchronized V get(Object key){}
public synchronized V put(K key, V value) {}
public synchronized V remove(Object key){}
- 用一个表来描述HashMap和HashTable的主要区别
| 对比 | HashMap | HashTable |
|---|---|---|
| 键值 | 键和value允许null | 不行 |
| synchronized | 非synchronzied | synchronized |
| 单线程情况下速度 | 快 | 慢 |
| 扩容方式 | 2倍 | 2倍+1 |
| 容量 | 初始为16,必须为2的n次方 | 初始为11 |
缺点
- 单线程情况下,也会加锁
ConcurrentHashMap
HashEntry类
static final class HashEntry {
219 final K key;
220 final int hash;
221 volatile V value;
222 final HashEntry next;
223
224 HashEntry(K key, int hash, HashEntry next, V value) {
225 this.key = key;
226 this.hash = hash;
227 this.next = next;
228 this.value = value;
229 }
230
231 @SuppressWarnings("unchecked")
232 static final HashEntry[] More ...newArray(int i) {
233 return new HashEntry[i];
234 }
235 }
Segment类
static final class Segment extends ReentrantLock implements Serializable {
transient volatile HashEntry[] table
315 final float loadFactor;
316
317 Segment(int initialCapacity, float lf) {
318 loadFactor = lf;
319 setTable(HashEntry.newArray(initialCapacity));
320 }
321
231 @SuppressWarnings("unchecked")
232 static final HashEntry[] newArray(int i) {
233 return new HashEntry[i];
234 }
Sets table to new HashEntry array. Call only while holding lock or in constructor.
330
331 void setTable(HashEntry[] newTable) {
332 threshold = (int)(newTable.length * loadFactor);
333 table = newTable;
334 }
- Segment继承了ReentrantLock显示锁
- 一个Segement对象维护这一个HashEntry数组
- 构造方法里面调用了newArray方法,这个方法用于创建一个HashEntry数组
CurrentHashMap构造方法
612 public .ConcurrentHashMap(int initialCapacity,
613 float loadFactor, int concurrencyLevel) {
614 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
615 throw new IllegalArgumentException();
616
617 if (concurrencyLevel > MAX_SEGMENTS)
618 concurrencyLevel = MAX_SEGMENTS;
619
620 // Find power-of-two sizes best matching arguments
621 int sshift = 0;
622 int ssize = 1;
623 while (ssize < concurrencyLevel) {
624 ++sshift;
625 ssize <<= 1;
626 }
627 segmentShift = 32 - sshift;
628 segmentMask = ssize - 1;
629 this.segments = Segment.newArray(ssize);
630
631 if (initialCapacity > MAXIMUM_CAPACITY)
632 initialCapacity = MAXIMUM_CAPACITY;
633 int c = initialCapacity / ssize;
634 if (c * ssize < initialCapacity)
635 ++c;
636 int cap = 1;
637 while (cap < c)
638 cap <<= 1;
639
640 for (int i = 0; i < this.segments.length; ++i)
641 this.segments[i] = new Segment(cap, loadFactor);
642 }
- 629行创建了一个Segment数组
- 640-641为Segment数组中的每一个Segment创建一个HashEntry数组
- 那么实际上初始化的时候是先创建一个Segemnt数组,然后每个Segment又创建一个HashEntry数组,可以类比二维数组

CurrentHashMap的put方法
public V put(K key, V value) {
908 if (value == null)
909 throw new NullPointerException();
910 int hash = hash(key.hashCode());
911 return segmentFor(hash).put(key, hash, value, false);
912 }
200 final Segment segmentFor(int hash) {
201 return segments[(hash >>> segmentShift) & segmentMask];
202 }
- put的时候通过segmentFor找到segments数组的下标,然后在该segemnt存放键值对,实际上就是找到一个HashEntry数组,然后添加到该数组其中一个链表中
Segment的put方法
444 V put(K key, int hash, V value, boolean onlyIfAbsent) {
445 lock();
446 try {
447 int c = count;
448 if (c++ > threshold) // ensure capacity
449 rehash();
450 HashEntry[] tab = table;
451 int index = hash & (tab.length - 1);
452 HashEntry first = tab[index];
453 HashEntry e = first;
454 while (e != null && (e.hash != hash || !key.equals(e.key)))
455 e = e.next;
456
457 V oldValue;
458 if (e != null) {
459 oldValue = e.value;
460 if (!onlyIfAbsent)
461 e.value = value;
462 }
463 else {
464 oldValue = null;
465 ++modCount;
466 tab[index] = new HashEntry(key, hash, first, value);
467 count = c; // write-volatile
468 }
469 return oldValue;
470 } finally {
471 unlock();
472 }
473 }
- 在前面已经知道Segment继承了显式锁,从445看出,代码会执行lock方法,也就是加锁,这是对于一个Segment的,那么也就是如果put的时候找到的Segemnt是不一样的,那么put的时候不是锁对象不同就不会产生竞争,这就是相对于HashTable来说的一个优点,不会任何时候都加锁
CurrentHashMap的get方法
795 public V get(Object key) {
796 int hash = hash(key.hashCode());
797 return segmentFor(hash).get(key, hash);
798 }
- 和put一样,先在segments数组中找到一个segment,然后执行他的get方法
Segment的get方法
362 V get(Object key, int hash) {
363 if (count != 0) { // read-volatile
364 HashEntry e = getFirst(hash);
365 while (e != null) {
366 if (e.hash == hash && key.equals(e.key)) {
367 V v = e.value;
368 if (v != null)
369 return v;
370 return readValueUnderLock(e); // recheck
371 }
372 e = e.next;
373 }
374 }
375 return null;
376 }
377
- getFirst方法找到在Entry数组中对应位置的链表的链头,然后对链表进行遍历
- 看下370行的readValueUnderLock方法,源码也注释了recheck,作用就是在找当找到对应的键后并且value为null的时候,再进行一次查找。
readValueUnderLock
351 V readValueUnderLock(HashEntry e) {
352 lock();
353 try {
354 return e.value;
355 } finally {
356 unlock();
357 }
358 }
- 这次查找会进行加锁,这个过程可能读到最近覆盖的一个非空的value,这是对比HashTable的第二个好处,hashtable是对get用synchronized修饰,CurrentHashMap不会在get的时候全程加锁,减小锁的粒度,甚至不加锁
我觉得分享是一种精神,分享是我的乐趣所在,不是说我觉得我讲得一定是对的,我讲得可能很多是不对的,但是我希望我讲的东西是我人生的体验和思考,是给很多人反思,也许给你一秒钟、半秒钟,哪怕说一句话有点道理,引发自己内心的感触,这就是我最大的价值。(这是我喜欢的一句话,也是我写博客的初衷)
作者:jiajun 个人博客: http://www.cnblogs.com/-new/