Transformer是Google团队在 2017 年提出的自然语言处理(NLP)框架,也是截至目前,最主流的NLP框架。BERT、GPT-2都是基于该模型的变形和扩展。
Transformer的具体算法在论文《Attention Is All You Need》中描述。论文中展示了该模型的训练准确性高于之前所有模型,训练时间明显低于之前的模型,在训练集内容较少时训练效果也很好。它使用8个P100的GPU训练12小时即可生成基本翻译模型,其参数规模6.5M。
Transformer的优势在于:避免了循环网络的前后依赖,可以并行计算,加快了训练速度;同时也解决了长序列中运算量大和长距离的衰减问题,使模型可以处理更长的序列;加入残差网络又让模型可以达到足够的深度,以实现不同层次的抽象。
Transformer框架最核心的改进是在序列处理问题中放弃了循环网络RNN和CNN模型,使用注意力Attention算法计算序列中各个元素之间的关系。Transformer的层次和组件较多,但由于不使用RNN和CNN,单个组件的复杂度低,反而更容易理解,它的主体是全连接网络和Attention算法的堆叠,并使用了Seq2Seq编解码、词向量、位置编码、多头注意力、残差网络、多层叠加子网络等技术。本篇介绍Transformer的具体实现。
引入
上篇介绍了Seq2Seq+Attention的原理及实现代码,相对于普通的循环神经网络,Seq2Seq使用两个循环网络,在翻译问题中,Encoder用于将源语言翻译成语义编码c,Decoder用于将语义编码c生成目标语言。下面是其结构图:其中Embedding用于将词转换成词向量,To vocab用于翻译之后的词向量转回词汇,并加入了Attention层,用于学习源语言与目标语言间词汇的对应关系。

下图是Transformer的结构图,看起来比Seq2Seq复杂很多,其中多头注意力Multi-head Attention和Pos Forward层还未展开。
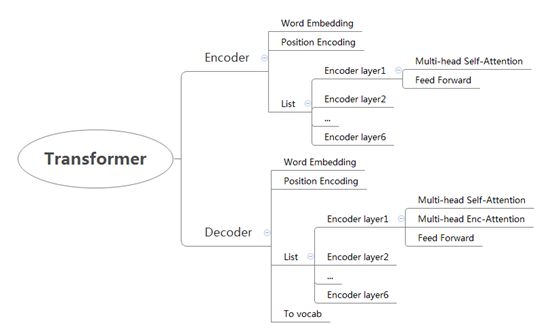
Transformer也用于实现翻译功能,和Seq2Seq一样,也分为Encoder和Decoder两部分,也包括自然语言处理中的词向量转换Embedding和To vocab。但有几点主要差别:
- 将循环神经网络RNN变为多个子网络叠加layer list。
- 用位置信息编码描述序列的前后关系。
- 引入自注意力Self-Attention,提取上下文中的相关性。
- 引入多头注意力Multi-head Attention算法,从多角度提取特征。
位置编码
从ConvS2S模型开始,位置编码被引入模型计算。这样不使用循环网络,也可以描述序列中元素的前后关系。自然语言处理以及任何序列问题都可以采用位置编码描述其位置信息。
位置编码将与词向量值相加,比如一个序列中有五个词,每个词用512维向量表示,词向量[1,5,512]加位置向量[1,5,512],得到大小为[1,5,512]的结果,这个值包含意义和位置两种信息,也可看成这个词在该位置的含义。
如果位置编码值过大,比如一段文字长度为2048,编码为0,1,...2047,则会削弱词向量的重要性,此时,可使用归一化转换成0,0.0005.....,1;另外,还需要保证不同长度的序列词间距离相等,比如“谁 知道”这两个词在三词序列间的距离需要与它在三百个词的序列中的距离相等。Transformer使用正余弦函数给位置编码,无需训练,直接使用公式算出,其编码如下(完整例程请见参考部分):
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx): # hid_idx为维度索引
return position / np.power(10000, 2 * (hid_idx // 2) / d_model) # //为整数除法
def get_posi_angle_vec(position): # position为序列中的位置
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # 2i为双数索引位
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # 2i+1为单数索引位
return torch.FloatTensor(sinusoid_table)
位置编码函数的输入是序列长度n_position和维数d_model(一般是256或512),输出是大小为 (n_position, d_model) 的矩阵,其中每一行对应一个单词的位置,每个位置由d_model个值表示,类似于词向量用d_model个特征描述一个词的含义。
其公式如下:
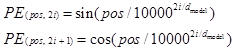
其中PE是位置编码Position Encoding矩阵,双数索引位2i使用sin函数计算,单数索引2i+1使用cos函数计算。
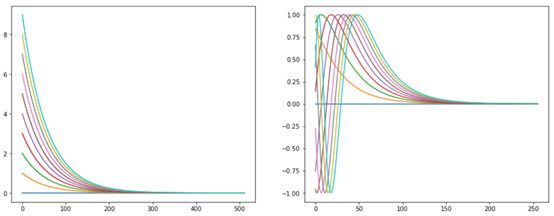
程序中cal_angle函数返回具体弧度值,2 * (hid_idx // 2) / d_model) 结果在 0-1 之间,np.power(10000, 2 * (hid_idx // 2) / d_model) 在 1-10000之间,cal_angle函数的返回结果在0-n_position之间,如序列长度为10时,返回[9,9,8.68...0]。下面左图将长度为10的序列扩展到512维,每个位置对应的弧度值(由cal_angle求得),右图为sin值。
sin和cos的关系公式如下:
代入PE可得:
当距离k固定时,PE(pos+k,2i)可表示成PE(pos,2i)和PE(pos,2i+1)的线性组合,PE(pos+k,2i+1)同理。这样即可计算两位置间的距离。
除了正余弦编码,也可以直接嵌入位置信息,二者的训练效果差不多。如BERT的训练集非常丰富庞大,模型就直接使用了嵌入位置信息,而Transformer的基本模型考虑在小训练集的情况下,测试集句子可能比训练集中句子更长的情况,正余弦编码是周期性函数,可以给更长的句子编码。
自注意力
上篇讲到Seq2Seq在解决翻译问题时,引入了注意力Attention机制,建立源序列和目标序列之间词汇的对应关系。
自注意力Self-Attention是一种特殊的注意力机制,它寻找的不是两个句子中词之间的关系,而是单词与本句中其它词之间的关系。如果把它当作黑盒,只关注输入和输出,输入的是包含多个词汇的序列X(x1,x2,x3...),输出可看做每个词在该句中更精确的含义Z(z1,z2,z3...)。比如单看文字“张无忌”是一个人名,如果看完《倚天屠龙记》,张无忌这个名字,则增加了很多特征。每个词的输出向量都包含了句中其它词的信息,词不再是孤立的。
注意力计算公式如下:
公式中Q为查询向量(当前位置),K为键向量(其它位置),V为值向量(其它位置的值),通过计算Q和K之间的相关性来调整V的贡献度。在自注意力模型中,计算方法如下:

自注意力模型中,输入都是同一词序列X,通过与不同的参数W相乘,分别得到Q,K,V矩阵,然后代入公式计算Z。
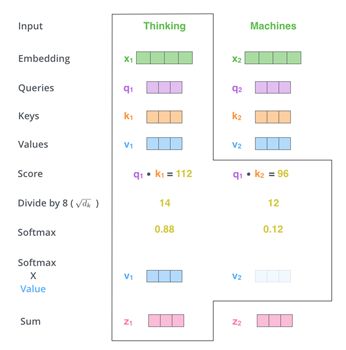
例如翻译“Thinking Machines”,将词转为词向量x1, x2,分别乘参数矩阵,得到q1,q2,k1,k2,v1,v2(基础模型将512维的x1转成64维的q1, 64维的k1和64维的v1);在计算第一个词“Thinking”时,用第一个查询向量q1分别点乘各个位置的键向量k1, k2得到112和96,然后除以k维度的开平方值(64开方得8,除该值的目的是避免结果过大,使得计算softmax后距离太小)得到14和12;做softmax归一化,得到两个位置的重要性分别是0.88和0.12,再分别用重要性乘以值向量v1,v2,最后通过累加sum得到描述“Thinking”的新向量z1。其中的各个参数矩阵W都通过训练获得。
以上是计算自注意力的方法,上述逻辑也可用于计算翻译中源序列与目标序列中词的关系(Enc-Attention),不同的是与Q,K,V相乘的不再是序列X,而是dec_outputs, enc_outputs, enc_outputs,计算当前解码信息dec_ouputs(Q)与编码信息各个位置enc_outputs(K)之间的关系,加权调整编码信息enc_outputs(V),这也是上一篇看Attention的原理。具体代码见多头注意力部分。
从论文题目可以看出,Transformer的核心是Attention算法,它用注意力模型取代了RNN和CNN,从而减少了计算量,尤其在处理长距离的关系中有明显优势。比如:“在张三盗刷信用卡三十天之后,警察逮捕了他”。这里的“他”指代“张三”,但其中间隔多个词,在RNN中要计算它们的关系需要回退很多步,CNN每次也只能计算相邻的几个元素,也需要多层抽象,才能建立两词间的关系。而Self-Attention计算“他”与句中每个词的关系,计算二者相关性只需要一步。
当序列很长时,计算各词与句中其它成份的关系,运算量也不小,此时可以使用局部自注意力,即只计算某词与其前后N个词之间的关系。
多头注意力
Multi-head Attiotion是多头注意力模型,即对同一个词向量序列,同时做多次Attention,比如做8组Attention运算,每一组都有不同的WQ,WK,WV矩阵,各个W随机初始化,通过训练调整。多头的目的是形成多个子空间,让模型去关注不同方面的信息。其公式如下:

建立多组参数矩阵W,用每组W分别计算Attention,得到多个head输出,再用concat把多个输出连接到一起,最后乘输出参数Wo,得到MultiHead值。
多头注意力模型核心代码如下:
class ScaledDotProductAttention(nn.Module): # 点乘
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask): # 实现注意力公式
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
class MultiHeadAttention(nn.Module): # 多头注意力
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask):
residual, batch_size = Q, Q.size(0)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual), attn
程序中还加入了残差Residual和归一化处理LayerNorm。
在Encoder部分,自注意力将计算每个词与其它所有词的关系;在Decoder部分,尤其是在预测过程中,如要翻译出“我爱你”,翻译到“爱”时,“你”还没产生,因此,只能参考当前位置之前的词(已经生成的词)。attn_mask用于实现该功能,具体方法是使用上三角矩阵遮蔽部分数据。
前向传播网络
完成Attention之后,再使用Pos-wise Feed Forward做前向传播,Transformer论文中介绍前向传播可以使用两个卷积层,或者两个全连接层(卷积核大小为1时,卷积与全连接效果相同),两层之间加一个ReLU激活函数,将小于0的值都置为0,其公式为:
代码实现如下:
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return nn.LayerNorm(d_model)(output + residual)
除了两个卷积层,模型还加入了残差redidual和归一化处理LayerNorm。
多子层组合
Transformer分为Encoder和Decoder两部分, Encoder中又包含六个子模块Encoder Layer,每个Encoder Layer(图中左侧展开)中都包含多头自注意力模型Self Attention和前向传播Feed Forward两部分;Decoder中也包含六个子模块Decoder Layer,每个Decoder Layer(图中右侧展开)中又包含计算自身关系信息的自注意力模型Self Attention,计算Decoder与Encoder相关性的注意力模型Enc Attention,以及前向传播Feed Forward三部分。

训练时源语言序列通过词向量转换Word Embedding后,再加上位置信息Position Embedding,转入六层Encoder layer,编码后将中间状态,连同之前预测的目标序列传入六层解码Decoder layer,最终结果经过一个全连接层转换后,再做softmax生成词概率。
图中间的黑色箭头是编码输出的encode_output,它不仅作为隐藏层传入Decoder模型,还用于计算Encoder和Decoder之间的注意力关系。另外,在每一个Attention和Feed Forward后都加入了残差和归一化处理,这一操作保证了框架在多层堆叠后仍能正常工作。完整例程请见参考部分(代码共200多行)。
大量的论文表明,Transformer中下层更偏向于关注语法,上层更偏向于关注语义。
参考
Transformer论文:《Attention Is All You Need》
https://arxiv.org/abs/1706.03762完整例程
https://github.com/graykode/nlp-tutorial/blob/master/5-1.Transformer/Transformer-Torch.py