abstract
与最近基于身体部件进行建模或对齐身体部件的方向相反,我们表明将获得的相机视图和/或检测到的关节位置直接地包含到卷积神经网络中就可以学到非常有效的表示。
introduction
不同视角的展示的是服装的不同方面(例如背包):

姿势的改变可能导致身体部位(手/腿)位于图像的不同位置:

由于人具有不同的视图和不同的姿势,图像的局部区域之间没有隐含的对应关系。这种对应关系可以通过明确地使用全身姿势信息进行比对[37]或通过匹配身体部位来定义[47,48]。 通过结合身体姿势或身体部位信息来使用这种global和local的描述可以极大地提升精度。
本文表明,结合人的粗粒度姿态(即视图)或细粒度的身体姿态(即关节位置)以及softmax loss就可以学习到非常好的特征。
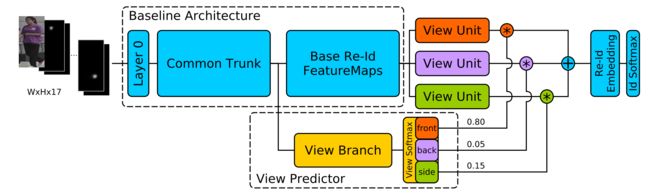
3. Pose-Sensitive Embedding
人的姿势和相机方向对成像影响很大。
3.1. View Information
我们使用人物相对于相机的位置['front','back','side']作为粗粒度的姿势信息,称之为view information。在主CNN网络上添加一个三元视图分类器作为侧分支。然后通过复制现有层将主CNN的尾部分成三个等效单元。视图分类器输出的三个预测分数用于三个单元进行加权。
这种方式调整了梯度的流动,例如, 对于具有强烈“前方”预测的训练样本,主要是由前方权重加权的单位将有助于最终嵌入,因此只有该单位将接收当前训练样本的强梯度更新。此过程使得每个单元学习三个视图之一的特征映射。与[32]相反,我们不对最终嵌入或预测向量进行加权和融合,而是将权重应用于完整feature map,然后将其组合到最终嵌入中,这更具有鲁棒性。
re-id数据集通常没有视图注释。因此我们在单独的RAP [20]行人数据集上预先训练了一个视图分类器,然后直接迁移到re-id模型中。
在我们的ResNet-50架构中,视图预测器分支在第三个降维步骤(即feature map 28x28x256)之后从主网络中分离出来。然后,我们应用步长为2,2和5的三个连续卷积,以进一步减小尺寸(缩小至1×1×1024)。生成的特征向量加上三向softmax可以用来预测视图。至于视图单元,我们使用ResNet Block-4的三个复制。这些单元融合之后输出的7×7×2048被送入FC层,产生1536维的特征。
3.2. Full Body Pose
作为人姿势的细粒度表示,我们使用14个关键点的位置。要获得此信息,我们使用现成的DeeperCut [15]模型。 与先前使用姿势信息进行重新识别相反,我们不使用此信息来明确地标准化输入图像。相反,我们通过为14个关键点中的每一个添加额外的输入通道来将信息包含在训练过程中。这些通道用于指导CNN的注意力,并为其提供充分的灵活性,以便自己学习如何最好地将联合信息应用到最终的嵌入中。为了进一步提高这种灵活性,我们不依赖于DeeperCut方法输出的关键点,而是为我们的CNN提供每个关键点的完整置信度映射。这可以防止基于硬关键点决策的任何错误输入,并使我们的模型有机会补偿或至少识别不可靠的姿势信息。
3.3. Training Details
我们使用在ImageNet上预训练好的权重初始化CNN。为了训练具有视图信息的模型,我们首先微调RAP数据集上的视图预测器分支。接下来,我们仅在目标re-id数据集上训练视图单元和最终人员身份分类层。视图预测器的权重和视图单元之前的所有层都是固定的。这允许随机初始化的视图单元和最终层适应早期层的现有权重。 最后,我们微调整个网络直到收敛。
在训练嵌入包括全身姿势信息时,由于额外的14个关键点通道,ImageNet权重与输入的大小不匹配。为了使网络适应17通道输入,我们通过仅微调第一层(Layer 0)来开始我们的训练,以及最终的人物身份分类层,它们都是随机初始化的。网络的其余部分仍然是固定的。 一旦这两个层适应网络的其余部分(即收敛),我们就微调整个网络。
对于我们的最终姿势敏感嵌入(PSE),我们将两种类型的姿势信息组合到一个网络中。我们使用全身姿势模型初始化我们的训练并添加视图预测器到它上面。 视图预测器在带有姿势注释的RAP数据集上进行微调,并且可以从额外的全身姿势信息中受益。 然后对目标数据集执行网络的重新标识的元素的进一步微调。
对于所有的CNN嵌入采用相同的训练方式。 输入图像归一化为通道方式零均值和标准变化1。通过将图像大小调整为105%宽度和110%高度并随机裁剪训练样本以及随机水平翻转(这是我们不区分左侧视图和右侧视图的主要原因)来执行数据增强。
re-ranking
重排序过程主要取决于计算排名列表的距离。为了防止false positives in the top neighborhood,通常会使用local query expansion。query expansion 过程指的是用一些近邻来扩展probe(如平均),然后再进行查询。根据原始的或扩展的probe距离能够得到两个排序列表,对它们之间进行比较得到最终的距离。以前所有的方法几乎都是这样。它们的不同点在于“如何获得k近邻”“怎么比较rank list”“怎么扩展probe”。
一般都是通过计算jaccard distance来对两个rank-list进行比较,但是这样计算复杂度很高。因此SCA把近邻集合编码成一个稀疏的向量,然后计算距离。为了减少原始rank list中的错误匹配,zhong等人基于互惠近邻形成新的排名列表来包括更多上下文。注意,尽管基于互惠近邻的列表比较方式效果很好,但是它需要额外的时间来重新计算互惠近邻集合。
本文提出了一个概念:Expanded Cross Neighborhood(ECN),它不需要严格的rank list比较。对于一个图片对(A,B),累加A的每个直接近邻跟B的距离即可。这里的距离既可以是欧式距离,也可以是基于rank-list重新计算的距离。
Formally,给定一个probe p和一个gallery 。p和G中每张图片的距离是。对距离进行升序排列可以得到一个初始的rank list 。
定义p的expanded neighbors,记作:
其中是p的t个直接近邻,是p的间接近邻。
M的大小为
同样计算G中每个图片的multiset 。最后,两张图片之间的距离为:
其中表示的第j个近邻,d可以是欧式距离,也可以是rank-list距离。之前的工作计算两个rank list的距离都是使用Jaccard Distance,本文使用一种简单的方法[16,33]。对于一个具有N张图片的gallery的rank list来说,设表示图片n在第i个rank list中的位置。仅考虑前K个近邻,两个rank-list的相似度为:
这里表示。这种度量保证了
代码:https://github.com/pse-ecn/expanded-cross-neighborhood
[16]R. A. Jarvis and E. A. Patrick. Clustering using a similarity measure based on shared near neighbors. IEEE Transactions on computers , 100(11):1025–1034, 1973.
[33]F. Schroff, T. Treibitz, D. Kriegman, and S. Belongie.Pose, illumination and expression invariant pairwise facesimilarity measure via doppelganger list comparison. In ¨ ICCV, IEEE International Conference on, pages 2494–2501. IEEE, 2011.