上一篇网贷平台Prosper2005~2014贷款数据分析(一)中,主要重要变量的介绍、几个重要变量的转换、数据的探索性分析。接下来,主要介绍数据缺失处理、模型分析和预测。
六、缺失值处理
主要变量的缺失值,只显示存在缺失的变量,获取其缺失数量,以及缺失率,代码实现如下:
missing=pd.concat([loanData.isnull().any(),loanData.count()],axis=1)
column=['是否缺失','数量']
missing=pd.DataFrame(list(missing.values),index=list(missing.index),columns=column)
max=missing['数量'].max()
missing['缺失数量']=max-missing['数量']
missing['缺失率']=missing['缺失数量']/max
miss=missing[missing['数量']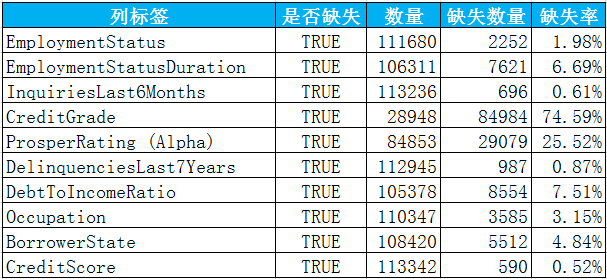
从上表中,可知代表信用等级的CreditGrade和ProsperRating (Alpha)变量缺失值较多,是因为平台是以2009年7月为分界点,使用不一样的评级方法而产生。
6.1 CreditScore缺失值处理
CreditScore缺失了590条,所占比例约为0.5%左右,所占比例不大,考虑模型的精确性,建议暂时用中位数进行替换。
#用中位数替换CreditScore的缺失值
loanData['CreditScore']=loanData['CreditScore'].fillna(loanData['CreditScore'].median())
6.2 BorrowerState缺失值处理
BorrowerState缺失值5512条,所占比例约5%,缺失比例较大,所以可以考虑将缺失值单独作为一项因子,暂时设置为“NOTA”。
#将缺失值单独作为一项因子,设置为“NOTA”
loanData['BorrowerState']=loanData['BorrowerState'].fillna('NOTA')
6.3 DebtToIncomeRatio缺失值处理
DebtToIncomeRatio缺失值为8554条,所占比例很大,且违约比例较大,依据常识债务比例数值越大违约的概率越大,所以根据数据集中债务比例分布情况将0.10~0.50随机赋值给缺失的DebtToIncomeRatio。设置随机赋值的定义函数:
#DebtToIncomeRatio缺失值添加随机数
def rand_missing(s):
if s>=0:
a=s
else:
a=random.uniform(0.1,0.5)
return a
对缺失值进行赋值:
#DebtToIncomeRatio的缺失值添加0.1~0.5的随机变量
loanData['DebtToIncomeRatio']=loanData['DebtToIncomeRatio'].apply(rand_missing)
6.3 DelinquenciesLast7Years缺失值处理
DelinquenciesLast7Years缺失值为987条,在平台借款违约比例较大,所以将DelinquenciesLast7Years缺失值全部置为1。
#将DelinquenciesLast7Years的缺失值赋值为1
loanData['DelinquenciesLast7Years'] = loanData['DelinquenciesLast7Years'].fillna(1)
6.4 EmploymentStatusDuration缺失值处理
EmploymentStatusDuration缺失值为7621条,所占比例很大,且违约比例很大。猜想,工作越稳定还款能力越强,故将EmploymentStatusDuration的缺失值置为48。
#EmploymentStatusDuration缺失值处理,设置为48
loanData['EmploymentStatusDuration'] = loanData['EmploymentStatusDuration'].fillna(48)
6.5 InquiriesLast6Months缺失值处理
InquiriesLast6Months缺失值为696条,所占比例不大,违约比例跟整体数据相近,故将InquiriesLast6Months的缺失值置为2。
#将InquiriesLast6Months的缺失值置为2
loanData['InquiriesLast6Months'] = loanData['InquiriesLast6Months'].fillna(2)
6.6 ProsperRating (Alpha)缺失处理
在2009年之后,大约有3万条,筛选出ProsperRating (Alpha)变量的缺失值,大约有144条,所占比例较小,所以采用直接删除的方式进行处理。
#2009之后,选出ProsperRating (Alpha)为空的行,然后对行进行删除
missIndex=loanData[(loanData['ProsperRating (Alpha)'].isnull()) & (loanData['DatePhase']=='After Jul.2009')]
loanData=loanData.drop(missIndex.index,axis=0)
七、建模分析
7.1 字符串变量转换成数字变量
数据中存在字符串变量,将其用数字变量进行替换。实现的函数如下:
#定性变量的赋值
def harmonize_data(df):
# 填充空数据 和 把string数据转成integer表示
#Status
df.loc[df['Status']=='Completed','Status']=1
df.loc[df['Status'] == 'Defaulted', 'Status'] = 0
df.loc[df['Status'] == 'Current', 'Status'] = 2
#IsBorrowerHomeowner
df.loc[df['IsBorrowerHomeowner'] == False, 'IsBorrowerHomeowner'] = 0
df.loc[df['IsBorrowerHomeowner'] == True, 'IsBorrowerHomeowner'] = 1
#CreditGrade
df.loc[df['CreditGrade'] == 'NC', 'CreditGrade'] = 0
df.loc[df['CreditGrade'] == 'HR', 'CreditGrade'] = 1
df.loc[df['CreditGrade'] == 'E', 'CreditGrade'] = 2
df.loc[df['CreditGrade'] == 'D', 'CreditGrade'] = 3
df.loc[df['CreditGrade'] == 'C', 'CreditGrade'] = 4
df.loc[df['CreditGrade'] == 'B', 'CreditGrade'] = 5
df.loc[df['CreditGrade'] == 'A', 'CreditGrade'] = 6
df.loc[df['CreditGrade'] == 'AA', 'CreditGrade'] = 7
#ProsperRating (Alpha)
df.loc[df['ProsperRating (Alpha)'] == 'HR', 'ProsperRating (Alpha)'] = 1
df.loc[df['ProsperRating (Alpha)'] == 'E', 'ProsperRating (Alpha)'] = 2
df.loc[df['ProsperRating (Alpha)'] == 'D', 'ProsperRating (Alpha)'] = 3
df.loc[df['ProsperRating (Alpha)'] == 'C', 'ProsperRating (Alpha)'] = 4
df.loc[df['ProsperRating (Alpha)'] == 'B', 'ProsperRating (Alpha)'] = 5
df.loc[df['ProsperRating (Alpha)'] == 'A', 'ProsperRating (Alpha)'] = 6
df.loc[df['ProsperRating (Alpha)'] == 'AA', 'ProsperRating (Alpha)'] = 7
#IncomeRange
df.loc[df['IncomeRange'] == 'Not displayed', 'IncomeRange'] = 0
df.loc[df['IncomeRange'] == 'Not employed', 'IncomeRange'] = 1
df.loc[df['IncomeRange'] == '$0', 'IncomeRange'] = 2
df.loc[df['IncomeRange'] == '$1-24,999', 'IncomeRange'] = 3
df.loc[df['IncomeRange'] == '$25,000-49,999', 'IncomeRange'] = 4
df.loc[df['IncomeRange'] == '$50,000-74,999', 'IncomeRange'] = 5
df.loc[df['IncomeRange'] == '$75,000-99,999', 'IncomeRange'] = 6
df.loc[df['IncomeRange'] == '$100,000+', 'IncomeRange'] = 7
#BankCardUse
df.loc[df['BankCardUse'] == 'No Use', 'BankCardUse'] = 0
df.loc[df['BankCardUse'] == 'Mild Use', 'BankCardUse'] = 1
df.loc[df['BankCardUse'] == 'Medium Use', 'BankCardUse'] = 2
df.loc[df['BankCardUse'] == 'Heavy Use', 'BankCardUse'] = 3
df.loc[df['BankCardUse'] == 'Super Use', 'BankCardUse'] = 4
#CustomerClarify
df.loc[df['CustomerClarify'] == 'New Borrower', 'CustomerClarify'] = 0
df.loc[df['CustomerClarify'] == 'Previous Borrower', 'CustomerClarify'] = 1
return df
#字符串替换成整数
loanData=harmonize_data(loanData)
7.2 建模分析(2009.07.01之前)
7.2.1 数据建模
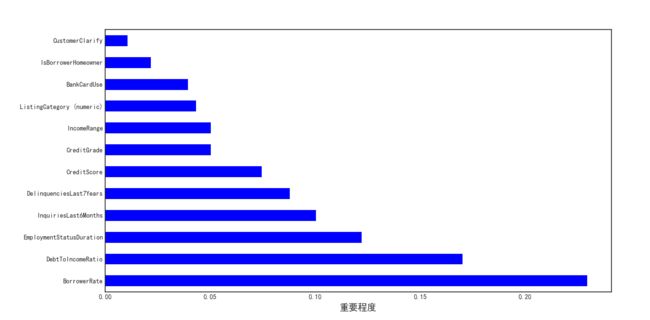
为了评估分类器的性能,将数据集分成训练集和测试集,为了获取各变量对违约情况的影响的重要程度,可以考虑用随机森林算法。
loanData = loanData[loanData['Status'] != 2]
before2009=loanData[loanData['DatePhase']=='Before Jul.2009']
Y=before2009['Status']
X=before2009[['CreditGrade','CustomerClarify','IncomeRange','DebtToIncomeRatio','DelinquenciesLast7Years','BorrowerRate','IsBorrowerHomeowner','ListingCategory (numeric)','EmploymentStatusDuration','InquiriesLast6Months','CreditScore','BankCardUse']]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
rfr=RandomForestClassifier()
rfr.fit(X_train,Y_train)
7.2.2 模型评估
将分配的30%的测试集,对训练出的模型进行评估。
#测试集进行预测
result=rfr.predict(X_test)
对预测的准确率进行计算:
def accuracy_statistics(rd,prd):
count=len(prd)
sum=0
for i in range(1,count):
if rd[i]==prd[i]:
sum += 1
pecent=round(sum/count,4)
return pecent
pecent=accuracy_statistics(list(Y_test.values),list(result))
该模型预测结果的准确率为(1498+4520)/8385=71.77%。
7.2.3 变量的重要性
对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值,可以获取变量的重要程度。
featureImp=pd.Series(rfr.feature_importances_,index=list(X_train.columns)).sort_values(ascending=False)
fig2 = plt.figure(2)
ax2 = fig2.add_subplot(1, 1, 1)
featureImp.plot(kind='barh',ax=ax2)
ax2.set_xlabel('重要程度',fontsize=14)
plt.show()
7.3 建模分析(2009.07.01之后)
7.3.1 数据建模
2009年7月后数据集的分配,代码实现如下:
afterData = loanData[loanData['Status'] != 2]
after2009=afterData[afterData['DatePhase']=='After Jul.2009']
Y=after2009['Status']
X=after2009[['ProsperRating (Alpha)','CustomerClarify','IncomeRange','DebtToIncomeRatio','DelinquenciesLast7Years','BorrowerRate','IsBorrowerHomeowner','ListingCategory (numeric)','EmploymentStatusDuration','InquiriesLast6Months','CreditScore','BankCardUse']]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
rfr=RandomForestClassifier()
rfr.fit(X_train,Y_train)
7.3.2 模型评估
将分配的30%的测试集,对训练出的模型进行评估。
#测试集进行预测
result=rfr.predict(X_test)
对预测的准确率进行计算:
def accuracy_statistics(rd,prd):
count=len(prd)
sum=0
for i in range(1,count):
if rd[i]==prd[i]:
sum += 1
pecent=round(sum/count,4)
return pecent
pecent=accuracy_statistics(list(Y_test.values),list(result))
该模型预测结果的准确率为(161+6382)/8484=77.12%。
7.3.3 变量的重要性
如图7-2所示,对模型预测结果的准确率影响最大的前三个变量为EmploymentStatusDuration,BorrowerRate,DebtToIncomeRatio。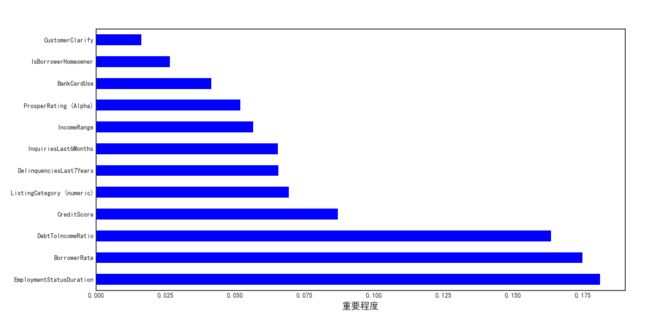
7.4 小结
2009.07.01前后的模型变量重要性相比,EmploymentStatusDuration由第三位变为第一位,说明在2009.07.01之后的模型更加强调雇佣状态持续时间的重要性,从模型预测的准确率来看,这种模型的调整是有效的,使得准确率由71.77%增加到77.12%。
八、数据预判
根据2009年后的模型,对正在贷款状态的客户可能违约情况进行预测。
#正在贷款的人还款预测
currentData=loanData[loanData['Status']==2]
current=currentData[['ProsperRating (Alpha)','CustomerClarify','IncomeRange','DebtToIncomeRatio','DelinquenciesLast7Years','BorrowerRate','IsBorrowerHomeowner','ListingCategory (numeric)','EmploymentStatusDuration','InquiriesLast6Months','CreditScore','BankCardUse']]
currentPredict=rfr.predict(current)
currentData.loc[(currentData.Status.notnull()),'Status'] = currentPredict
currentData.to_csv('PredictData.csv',index=False)
可以计算56576条正在贷款的客户,整体的违约率,实现代码如下:
defaultedRate=1-(currentPredict.sum()/len(currentPredict))
正在贷款的客户整体的违约率1-(53037/56576)=6.3%。
九、总结
本文详述了如何通过数据预览,基本数据分析、探索式数据分析,缺失数据填补等方法,实现对kaggle上Prosper借贷平台贷款者还款与否这一分类问题如何进行数据分析的具体探索式实践。分别对2009.07.01前后的模型进行建模分析对比,得出两个模型的预测准确率和变量对模型的重要性对比分析,明确看出2009.07.01前后平台的模型明显有很大的不同。在基于2009年后模型,对正在贷款状态的客户的违约可能性进行预测。