----------------------------大纲--------------------------
1 原理
1.1 语言模型
1.2 ngram
1.3 神经网络语言模型
当前词wt 依赖于其前面的词w1:(t−1) ,估计P(Wt|W1:(t−1)) 转化为分类问题,降低语言模型困惑度
1.4 word2vec 不通过优化语言模型而直接学习词嵌入
训练目标是得到一组较好的词嵌入而不是降低语言模型的困惑度,word2vec,当前词wt 依赖于其前后的词
1.4.1 CBOW
1.4.2 Skip-Gram
2 tensorflow中两种使用方式
词向量使用预先训练好的,程序中不断迭代
time:20180108
by : lbda1
-------------------------------------------------------------
1 原理
1.1 语言模型
语言模型用于对特定序列的一系列词汇的出现概率进行计算。一个长度为m的词汇序列{w1,…,wm}的联合概率被表示为P(w1,…,wm)。由于在得到具体的词汇之前我们会先知道词汇的数量,词汇wi的属性变化会根据其在输入文档中的位置而定,而联合概率P(w1,…,wm)的计算通常只考虑包含n个前缀词的词窗口而非考虑全部的前缀词。
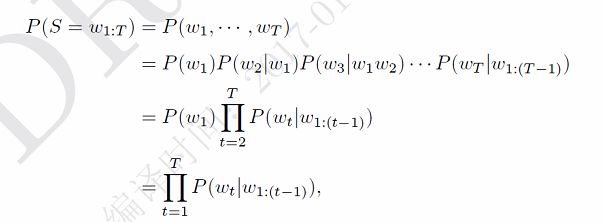
1.2 ngram
上式可以看出,我们需要估计句子中每个词wt 在给定前面词序列w1:(t−1) 时的条件概率。假如我们有一个很大的文档集合,就可以去估计这些概率。但是由于数据稀疏问题,我们很难估计所有的词序列。一个解决方法是马尔可夫性质。 我们假设一个词的概率只依赖于其前面的n − 1个词(n阶马尔可夫性质)。
这就是N元(N-gram)语言模型。当n = 1 时,称为一元(unigram)语言模型,当n = 2 时,称为二元(bigram)语言模型。2-gram的词频是通过统计当前词和其前面一个词。
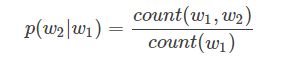
同理3-gram如下

1.3 神经网络语言模型
在统计语言模型中,一个关键的问题是估计P(Wt|W1:(t−1)),即在时刻(或位置)t,给定历史信息ht = w1:(t−1) 条件下,词汇表V 中的每个词vk出现的概率。这个问题可以转换为一个类别数为|V| 的多类分类问题.

其中,fk 为分类函数,估计的词汇表中第k 个词出现的后验概率,并满足如下条件
其中Θ为模型参数.这样,我们就可以使用机器学习中的不同分类器来估计语言模型的条件概率.
1.3.1 模型结构
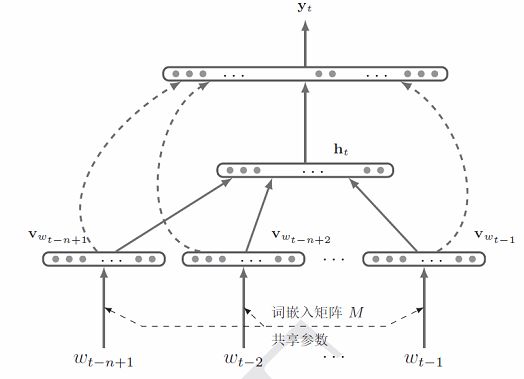
输入层
隐藏层
输出层: 输出层输出层为大小为|V|,其接受的输入为历史信息的向量表示ht,输出为词汇表V中每个词的概率。
1.3.2 train
给定一个训练文本序列w1, · · · ,wT ,神经网络语言模型的训练目标为找到一组参数Θ,使得负对数似然函数NLL最小。

1.3.3 大词汇表上softmax 计算的改进
为了使得神经网络语言模型的输出P(w|h) 为一个概率分布,得分函数会进行softmax 归一化。在语言模型中,词汇表V的规模一般都比较大,取值一般在1 万到10 万之间。在训练时,每个样本都要计算一次。这导致整个训练过程变得十分耗时。在实践中,经常采样一些近似估计的方法来加快训练速度。常用的加快神经网络语言模型训练速度的方法可以分为两类:
• 一类是层次化的softmax 计算,将标准softmax 函数的扁平结构转换为层次化结构;
• 另一类是基于采样的方法,通过采样来近似计算更新梯度
1.3.3.1 层次化softmax
一般对于词汇表大小|V|,我们将词平均分到√|V| 个分组中,每组√|V| 个词。这样通过一层的分组,我们可以将softmax 计算加速12√|V| 倍。比如,词汇表大小为40, 000,我们将词汇表中所有词分到200 组,每组200 个词。这样,只需要计算两次200 类的softmax,比直接计算40, 000 类的softmax 加快100 倍。

为了进一步降低softmax的计算复杂度,我们可以更深层的树结构来组织词汇表。假设用二叉树来组织词汇表中的所有词,二叉树的叶子节点代表词汇表中的词,非叶子节点表示不同层次上的类别。图中给出了平衡二叉树和Huffman二叉树的示例。
1.3.3.2基于采样
具体的不介绍了

1.4 不通过优化语言模型而直接学习词嵌入word2vec
通过神经网络语言模型,我们可以在大规模的无标注语料上进行训练,来得到一组好的词向量。这些词向量可以作为预训练的参数,再代入到特定任务中进行精调。但是使用神经网络语言模型来预训练词嵌入由两个不足。一是即使使用改进的神经网络语言模型,其训练也需要大量的计算资源训练,训练时间非常长。二是神经网络语言模型的优化目标是降低语言模型的困惑度,和词嵌入的好坏并不是强相关关系。虽然训练一个好的语言模型会得到一组好的词嵌入,但是一组好的词嵌入却不一定要使得语言模型的困惑度降低.
下面我们介绍几种不通过优化语言模型而直接学习词嵌入的方法.连续词袋模型和Skip-Gram 模型.这这两个模型是著名的词嵌入学习工具word2vec 中包含的两种模型。这两种模型虽然依然是基于语言模型,但训练目标是得到一组较好的词嵌入而不是降低语言模型的困惑度。为了提高训练效率,这两种模型都通过简化模型结构大幅降低复杂度,并提出两种高效的训练方法(负采样和层次化softmax)来加速训练。在标准的语言模型中,当前词wt 依赖于其前面的词w1:(t−1)。而在连续词袋模型CBOW和Skip-Gram 模型中,当前词wt 依赖于其前后的词。
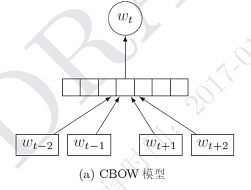
1.4.1 连续词袋模型CBOW
上下文几个词相加变成新的向量Ct

1.4.2 skip-gram(多个普通神经网络语言模型的加和,体现在目标函数内层的求和)

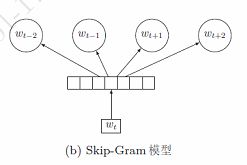
1.4.3 训练方法
在Word2Vec 中,连续词袋模型和Skip-Gram 模型都可以通过层次化softmax(huffman树) 和负采样来加速训练.