前言
很多程序员对字符编码不太理解,当然平时接触的也不是很多。可能只是大概知道 ASCII、UTF8、GBK、Unicode 等概念。字符串无法直接通过网络被传输(也不能直接被存储),需要先转换成二进制格式,再被还原。所以凡是涉及到网络传输字符的地方,通常都容易遇到编码问题。在 Java 中最常见的是乱码,而 Python 开发中遇到最多的是编码错误,如:UnicodeDecodeError, UnicodeEncodeError,几乎每个 Python 开发者都会碰到这种问题,对此都是一筹莫展。如果你正打算入门 Python 那么字符串编码毫无疑问是你入门 Python 前的必备知识。Python 中的ord()、chr()、len()、encode()、decode()等基本函数都和字符编码有这内在联系。
一、基本概念
- 什么是编码?
编码(encode)是把数据从一种形式转换为另外一种形式的过程,它是一套算法,比如这里的字符 A 转换成 01000001 就是一次编码的过程,解码(decode)就是编码的逆过程。今天我们讨论的是关于字符的编码,是字符和二进制数据之间转换的算法。密码学中的加密解密有时也称为编码与解码 - 什么是字符集?
字符集是一个系统支持的所有抽象字符的集合。它是各种文字和符号的总称,常见的字符集种类包括 ASCII 字符集、GBK 字符集、Unicode字符集等。不同的字符集规定了有限个字符,比如:ASCII 字符集只含有拉丁文字字母,GBK 包含了汉字,而 Unicode 字符集包含了世界上所有的文字符号。
二、ASCII 字符集和字符编码
ASCII 全称 American Standard Code for Information Interchange,美国信息交换标准代码。
- ASCII 字符集是字母、数字、标点符号以及控制符(回车、换行、退格)等组成的 128 个字符。
- ASCII 字符编码是将这128个字符转换为计算机可识别的二进制数据的一套规则(算法)。通常来说,字符集同时定义了一套同名的字符编码规则,例如 ASCII 就定义了字符集以及字符编码,当然这不是绝对的,比如 Unicode 就只定义了字符集,而对应的字符编码是
UTF-8编码,UTF-16编码。
三、EASCII (扩展的ASCII)
首先要知道所谓的 EASCII 是在 ASCII 的基础上扩展而来的。 ASCII 最初是有美国人创造的,但随着计算机的不断普及,西欧语言中还有很多字符不在 ASCII 字符集中,这给他们使用计算机造成了很大的限制。于是他们想尽办法把 ASCII 字符集进行扩充,认为 ASCII 只使用了字节的前 7 位,如果把第八位也利用起来,那么可表示的字符个数就是 256。这就是后来的 EASCII(Extended ASCII,延伸美国标准信息交换码)EASCII 码比 ASCII 码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。
然后 EASCII 并没有形成统一的标准,各国各商家都有自己的小算盘,都想在字节的高位做文章,比如 MS-DOS, IBM PC上使用了各自定义的编码字符集。为了结束这种混乱的局面,国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位元字符集的标准,叫 ISO 8859,全称ISO/IEC 8859,它在 ASCII 基础之上扩展而来,所以完全 ASCII,ISO 8859 字符编码方案所扩展的这128个编码中,只有 0xA0 ~ 0xFF(十进制为160~255)被使用,其实 ISO 8859 是一组字符集的总称,旗下共包含了 15 个字符集,包含了 ISO 8859-1 ~ ISO 8859-15,其中 ISO 8859-1 又称之为 Latin-1,它是西欧语言,其它的分别代表中欧、南欧、北欧等字符集。
四、GB2312 字符集和字符编码
再后来计算机就开始在中国普及,但是汉字博大精深,ASCII 字符集所能表示的字符太有限。多以要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了 GB2312 编码,用来把中文编进去。每个汉字符号由两个字节组成,理论上它可以表示65536个字符,不过它只收录了7445个字符,6763个汉字和682个其他字符,同时它能够兼容 ASCII,ASCII 中定义的字符只占用一个字节的空间。
GB2312 几乎收录已经覆盖中国大陆绝大多数汉字,但是对一些罕见的字和繁体字还有很多少数民族使用的字符都没法处理,于是后来就在 GB2312 的基础上创建了一种叫 GBK 的字符编码,GBK 不仅收录了27484 个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。GBK 是利用了 GB2312 中未被使用的编码空间上进行扩充,所以它能完全兼容 GB2312和 ASCII。
GB 18030 是现时最新的字符集,完全兼容 GB 2312-1980 和 GBK, 每个字符可以有 1、2、4 个字节组成。包含繁体汉字以及日韩汉字。单字节与 ASCII 兼容,双字节与 GBK 标准兼容。
五、Unicode 字符集和编码
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode 字符集应运而生。它把所有语言都统一到一套字符编码系统中里,这样就不会再有乱码问题了。
Unicode 是一种通用字符集,从字符到 Unicode 字符集中码位的转换也可以叫做 Unicode 编码,除此 Unicode 字符可以通过 UTF-8、UTF-16、甚至用 GBK 进行编码。如下代码是 Python 中的 ASCII编解码 和 UTF-8 编解码的代码范例。虽然下面是很基础的 Python 代码,但是对于没有接触的 Python 的开发者而言,我有必要简单的解释一下。由于Python的字符串类型是str,在内存中以 Unicode 表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。Python对bytes类型的数据用带b前缀的单引号或双引号表示。要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。另外还要知道下面代码快的6、7、8行代码是错误提示,这里笔者是故意写出一个错误范例,想让读者更好的理解代码中b的作用。
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "", line 1, in
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
六、UTF-8编码
6.1 UTF-8编码更节省空间
ASCII编码是 1 个字节,而Unicode编码通常是 2 个字节。
- 字母
A用ASCII编码是十进制的65,二进制的01000001; - 字符
0用 ASCII 编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的; - 汉字
”中“已经超出了 ASCII 编码的范围,用 Unicode 编码是十进制的20013,二进制的01001110 00101101。
虽然统一成Unicode编码,可以消除乱码问题但是对于英文文本而言,用 Unicode 编码比 ASCII 编码需要多一倍的存储空间,十分消耗额外的空间。
所以之后又出现了可变长编码的UTF-8编码。 UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 1001110 00101101 | 11100100 10111000 10101101 |
6.2 UTF-8编码无需考虑大小端问题
6.2.1 大小端是什么?
- 大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
- 小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
下面以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value。
Big-Endian: 低地址存放高位,如下:
高地址
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
低地址
Little-Endian: 低地址存放低位,如下:
高地址
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
低地址
6.2.2 为何会有大小端之分?
于 16 位或者 32 位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节排放的问题,因为不同操作系统读取多字节的顺序不一样,x86和一般的OS(如windows,FreeBSD,Linux)使用的是小端模式。但比如Mac OS是大端模式。因此就导致了大端存储模式和小端存储模式的存在。但是实际中,大端和小端并不涉及到优劣的区分。
6.2.3 UTF-8 为何无需考虑大小端问题?
因为UTF-8 的编码单元是1个字节,再结合大小端的定义来看,所以就不用考虑字节序问题。但是对于 UTF-16 ,它是用 2 个字节来编码 Unicode 字符,编码单位是两个字节,2 个字节需要确定哪个放于高位,哪个放于低位, 因此会涉及大小端问题。
六、现代计算机系统通用的字符编码工作方式
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
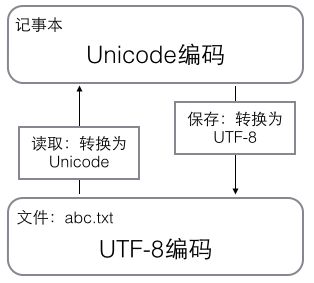
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。如下图:
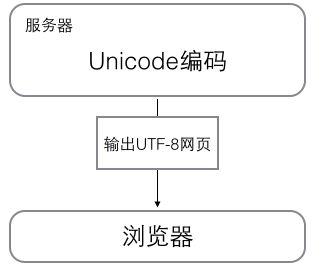
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。