C语言文件
1. 文件流
1.1. 文件流概念
C语言把文件看作是一个字符的序列,即文件是由一个一个字符组成的字符流,因此c语言将文件也称之为文件流。当读写一个文件时,可以不必关心文件的格式或结构
1.2. 文件类型
1.2.1. 文件分类
计算机的存储,物理上是二进制的。文本文件是基于字符编码的文件,常见的编码有ASCII编码,二进制文件是基于值编码的文件
文本文件:以ASCII码形式存放,一个字节存放一个字符存放每一个ASCII码。便于对字符串的逐个处理,但占用存储空间较多,而且花费时间转换
二进制文件:以值(补码)编码形式存放,把数据以二进制数的格式存放在文件中。占用存储空间较少,数据按其内存中的存储形式原样存放。
1.2.2. 图示代码展示
数据存入文件:short int a = 10000; // 0x2710

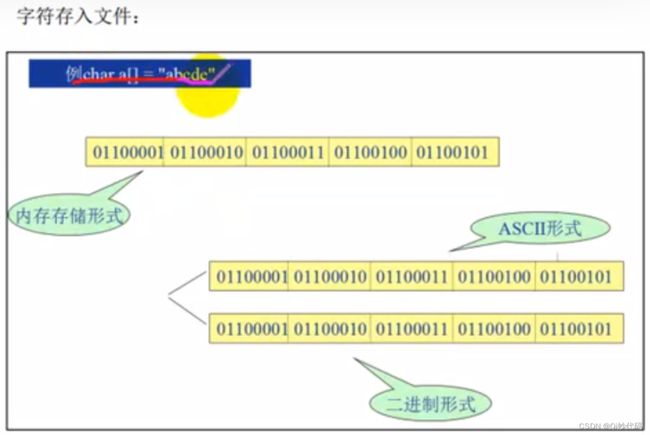
1.2.3. 乱码缘由
文本工具打开文件的过程:首先读取文件物理上对应的二进制比特流,然后按照所选的解码方式来解释这个流,将解释结果显示出来。一般的解码方式都是ASCII形式,接下来,每8个比特地来解释这个文件流
例如文件流01000000|01000001|01000010|01000011解码后就变成ABCD了
如果编码和解码不对应,就会乱码
1.3. 文件缓冲
要有缓冲区(buffer)的原因:
- 从内存中读取数据比从文件中读取数据要快很多
- 对文件的读写需要用到open、read、write等系统底层模块,而用户进程每调用一次,系统函数都要从用户态切换到内核态,等执行完毕后再返回用户态,这种切换要花费时间成本。
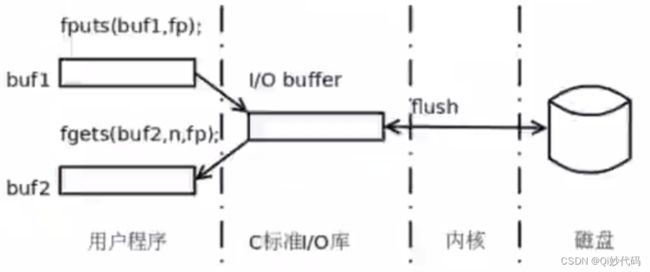
如果程序需要处理10k个整数,而这些整数事先存在某个文件中,如果程序每处理一个整数就要从文件中读取一个整数,那么每次都要进行硬件I/O、进程状态切换等操作,这样效率是非常低下的。如果每次从文件中读取1k个整数到内存,程序从内存中读取数据并处理,那么程序的性能就会提高,存储这1k个整数的内存区域就是一个缓冲区
int main()
{
while (1)
{
printf("abcdef"); // 缓冲区满,会写入文件
usleep(10000);
}
return 0; // 也可以通过fclose和fflush刷缓冲
}
2. 文件的打开和关闭
2.1. FILE结构体
FILE结构体是对缓冲区和文件读写状态的记录者,所有对文件的操作,都是通过FILE结构体完成的
typedef struct {
short level; // 缓冲区满/空程度
unsigned flags; // 文件状态标志
char fd; // 文件描述符
unsigned char hold; // 若无缓冲区不读取字符
short bsize; // 缓冲区大小
unsigned char *buffer; // 数据传送缓冲区位置
unsigned char *curp; // 当前读写位置
unsigned istemp; // 临时文件指示
short token; // 用作无效检测
}FILE;
在开始执行程序时,将自动打开3个文件和相关的流:标准输入流(stdin)、标准输出流(stdout)、标准错误(stderr),他们都是FILE *型的指针流提供了文件和程序的
// 通过fopen打开一个文件,返回一个FILE *指针
// 以后所有对于文件的操作,即操作FILE *指针pf
// 句柄
int main()
{
FILE *pf = fopen("test.txt", "r");
return 0;
}
2.2. fopen
函数声明:FILE *fopen(const char * filename, const char * mode);
所在文件:stdio.h
函数功能:以mode的方式,打开一个filename命名的文件,返回一个指向该文件缓冲的FILE结构体指针
参数:char * filename:要打开,或是创建文件的路径;char * mode:打开文件的方式
返回值:FILE *:返回指向文件缓冲区的指针,该指针式后续操作文件的句柄
| mode | 处理方式 | 当文件不存在时 | 当文件存在时 | 向文件输入 | 从文件输出 |
|---|---|---|---|---|---|
| “r” | 读取 | 出错 | 打开文件 | 不能 | 可以 |
| “w” | 写入 | 建立新文件 | 覆盖原有文件 | 可以 | 不能 |
| “a” | 追加 | 建立新文件 | 在原有文件后追加 | 可以 | 不能 |
| “r+” | 读取/写入 | 出错 | 打开文件 | 可以 | 可以 |
| “w+” | 写入/读取 | 建立新文件 | 覆盖原有文件 | 可以 | 可以 |
| “a+” | 读取/追加 | 建立新文件 | 在原有文件后追加 | 可以 | 可以 |
如果读写的是二进制文件,则还要加b,比如rb,r+b等,unix/linux不区分文本和二进制文件
2.3. fclose
函数声明:int fclose(FILE * stream)
所在文件:stdio.h
函数功能:fclose()用来关闭先前fopen()打开的文件,此动作会让缓冲区内的数据写入文件中,并释放系统所提供的文件资源
参数:FILE * stream:指向文件缓冲的指针
返回值:int,成功返回0,失败返回EOF(-1)
int main()
{
FILE *fp = fopen("data.txt", "w");
fputc("china is great", fp);
fclose(fp); // fflush(fp) // 设置断点调试
return 0;
}
3. 一次读写一个字符(文本操作)
3.1. fputc
函数声明:int fputc(int ch, FILE * stream)
所在文件:stdio.h
函数功能:将ch字符,写入文件
参数:FILE * stream:指向文件缓冲的指针;int ch:需要写入的字符
返回值:int:写入成功,返回写入成功字符,如果失败,返回EOF
#define F_PRINT_ERR(e) \
do \
{ \
if (e == NULL) \
{ \
printf("open error\n"); \
exit(-1); \
} \
} while (0)
int main()
{
FILE *fp = fopen("xx.txt", "w+");
F_PRINT_ERR(fp);
for (int ch = 'a'; ch <= 'z'; ch++)
{
putchar(fputc(ch, fp));
}
fclose(fp);
return 0;
}
3.2. fgetc
函数声明:int fgetc(FILE * stream)
所在文件:stdio.h
函数功能:从文件流中读取一个字符并返回
参数:FILE * stream:指向文件缓冲的指针
返回值:int:正常,返回读取的字符;读到文件尾或出错时,为EOF
读取字符的结束条件,通常是依据返回值。
int main()
{
FILE *fp = fopen("main.c", "r");
F_PRINT_ERR(fp);
FILE *f = fopen("/Users/mingqi/Desktop/output.txt", "w+");
F_PRINT_ERR(f);
char ch;
while ((ch = fgetc(fp)) != EOF)
{
putchar(ch); // 打印字符到标准输出
fputc(ch, f); // 将字符写入 f 文件
}
fclose(f);
fclose(fp);
return 0;
}
3.3. feof
函数声明:int feof(FILE * stream)
所在文件:stdio.h
函数功能:判断文件是否读到文件结尾
参数:FILE * stream:指向文件缓冲的指针
返回值:int,0未读到文件结尾,非零读到文件结尾
feof这个函数,是去读标志位判断文件是否结束的。即在读到文件结尾时再读一次,标志位才会置位,此时再来作判断文件处理结束状态,文件到结尾。如果用于打印,则会出现多打印一次的现象。
int main()
{
FILE *fp = fopen("xx.txt", "w+");
F_PRINT_ERR(fp);
for (int ch = 'a'; ch <= 'z'; ch++)
{
putchar(fputc(ch, fp));
}
rewind(fp);
printf("====\n");
char ch;
// feof检测文件结束标志,1结束,0未结束
// 会导致多读一个字符,标志位检测置后
/* while (!feof(fp))
{
ch = fgetc(fp);
printf("%x -> %c\n", ch, ch);
} */
// 解决
// ch = fgetc(fp);
while ((ch = fgetc(fp)) && !feof(fp))
{
printf("%x -> %c\n", ch, ch);
ch = fgetc(fp);
}
fclose(fp);
return 0;
}
3.4. 练习
3.4.1. 实现linux中cp命令的功能
int main(int argc, char *argv[])
{
if (argc < 3)
{
printf("Usage: %s src dest\n", argv[0]);
return 0;
}
FILE *fp = fopen(argv[1], "r");
if (fp == NULL)
return -1;
FILE *fp2 = fopen(argv[2], "w");
if (fp2 == NULL)
{
fclose(fp2);
return -1;
}
char ch;
while ((ch = fgetc(fp)) != EOF)
{
fputc(ch, fp2);
ch = fgetc(fp);
}
fclose(fp);
fclose(fp2);
}
3.4.2. 文件的加密与解密
#define CODE 10
// 加密
int main()
{
FILE *pfSrc = fopen("main.c", "r+");
F_PRINT_ERR(pfSrc);
FILE *pfDes = fopen("maincode.c", "w+");
F_PRINT_ERR(pfDes);
char ch;
while ((ch = fgetc(pfSrc)) != EOF)
{
ch += CODE;
fputc(ch, pfDes);
}
fclose(pfSrc);
fclose(pfDes);
return 0;
}
// 解密
int main()
{
FILE *pfSrc = fopen("maincode.c", "r+");
F_PRINT_ERR(pfSrc);
FILE *pfDes = fopen("maindecode.c", "w+");
F_PRINT_ERR(pfDes);
char ch;
while ((ch = fgetc(pfSrc)) != EOF)
{
ch -= CODE;
fputc(ch, pfDes);
}
fclose(pfSrc);
fclose(pfDes);
return 0;
}
4. 一次读写一行字符(文本操作)
行在不同平台是有差异的,window平台’\r\n’,linux平台是’\n’;linux读windows中的换行,会多读一个字符,windows读linux中的换行,没有问题
4.1. fputs
函数声明:int fputs(char *str, FILE *fp)
所在声明:stdio.h
函数功能:把str指向的字符串写入fp指向的文件中
参数:char * str:指向的字符串的指针;FILE * fp:指向文件流结构的指针
返回值:int:正常,返0,出错,返EOF
int main()
{
FILE *pf = fopen("xx.txt", "w");
F_PRINT_ERR(pf);
fputs("aaaaaa", pf);
fputs("bbbbbb", pf);
fputs("cccccc", pf);
fclose(pf);
return 0;
}
4.2. fgets
函数声明:char *fgets(char *str, int length, FILE *fp)
所在文件:stdio.h
函数功能:从fp所指向的文件中,至多读length-1个字符,送入字符数组str中,如果在读如length-1个字符结束前遇到\n或EPF,读入即结束,字符串读入后在最后加一个\0字符
fgets函数返回有三个条件:
- 读n-1个字符前遇到\n,读取结束(\n被读取)
- 读n-1个字符前遇到EOF,读取结束
- 读到n-1个字符
参数:char * str:指向需要读入数据的缓冲区;int length:每一次读数字符的字数;FILE * fp:文件流指针
返回值:char *:正常,返回str指针;出错或遇到文件结尾,返空指针NULL
按行读取,重点是判断结束条件,通常做法是依据返回值
// 在去读n-1个字符前遇到\n,连同\n一并读进来
// 在去读n-1个字符时,即没有遇到\n也没有EOF,此时就读到了n-1个字符,并在其后添加了\0
// 在去读n-1个字符时,即没有遇到\n,遇到EOF,并在其后添加了\0
int main()
{
FILE *pf = fopen("xx.txt", "r");
F_PRINT_ERR(pf);
char buf[1024];
fgets(buf, 2, pf);
printf("buf = %s", buf);
return 0;
}
4.3. feof
int main()
{
FILE *pf = fopen("xx.txt", "w+");
if (NULL == pf)
exit(-1);
fputs("aaaaaaaaa\n", pf);
fputs("bbbbbbbbb\n", pf);
fputs("ccccccccc\n", pf);
fputs("ddddddddd", pf);
rewind(pf);
char buf[1024];
// while (fgets(buf, 1024, pf) && !feof(pf))
// {
// printf("%s", buf);
// }
while (fgets(buf, 1024, pf) != NULL)
{
printf("%s", buf);
}
return 0;
}
4.4. 注意事项
读到buf内的字符串,可含有空白格式控制字符,比如’\n’,‘\r\n’,'\t’等,如果直接用作比较等用途,可能得不到正确的结果
int main11()
{
FILE *pf = fopen("xx.ini", "r+");
if (NULL == pf)
exit(-1);
char name[1024];
scanf("%s", name);
char buf[1024];
fgets(buf, 1024, pf);
char *p = buf + strlen(buf) - 1; // 指向字符串的最后一个字符
while (p >= buf && (*p == '\t' || *p == '\n' || *p == '\r'))
{ // 去掉末尾的制表符和换行符
*p = '\0';
p--;
}
if (strcmp(name, buf) == 0)
printf("欢迎登录\n");
else
printf("登录失败\n");
return 0;
}
4.5. 练习
4.5.1. 读取配置文件,过滤掉#
int main()
{
FILE *pf = fopen("code.txt", "r+");
if (NULL == pf)
exit(-1);
char buf[1024];
FILE *pfbak = fopen("code.conf.bak", "w");
if (NULL == pfbak)
{
fclose(pf);
exit(-1);
}
while (fgets(buf, 1024, pf))
{
if (*buf == '#' || *buf == '\n' || *buf == ' ' || *buf == '\t')
continue;
printf("%s", buf);
fputs(buf, pfbak);
}
fclose(pf);
fclose(pfbak);
return 0;
}
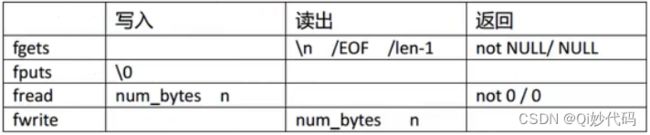
5. 一次读写一块字符(二进制操作)
所有的文件接口函数,都是以’\0’、‘\n’或EOF表示读取结束的。’\0’、'\n’都是文本文件的重要标识,而二进制文件,往往以块的形式写入或读出。而所有的二进制接口对于这些标识,是不敏感的
5.1. fwrite/fread
函数声明:int fwrite(void *buffer, int num_bytes, int count, FILE *fp)
int fread(void *buffer, int num_bytes, int count, FILE *fp)
所在文件:stdio.h
函数功能:把buffer指向的数据写入fp指向的文件中,或是把fp指向的文件中的数据读到buffer中
参数:char * buffer:指要输入/输出数据存储区的首地址的指针;int num_bytes:每个要读/写的字段的字节数;int count:要读/写的字段的个数;FILE *fp:要读/写的文件指针
返回值:int,成功,返回读/写的字段数;出错或文件结束,返回0
int main()
{
char buf[1024] = "a\nbc\0defd";
FILE *pfa = fopen("xx.txt", "w+");
fputs(buf, pfa);
char readArr[1024];
rewind(pfa);
fgets(readArr, 1024, pfa);
printf("%s", readArr);
fclose(pfa);
FILE *pfb = fopen("yy.txt", "wb");
fwrite((void *)buf, 1, 8, pfb);
rewind(pfb);
fread((void *)readArr, 1, 8, pfb);
for (int i = 0; i < 8; i++)
{
printf("%x -> %c\n", readArr[i], readArr[i]);
}
fclose(pfb);
return 0;
}
5.2. 试读文本文件
试图用fread读取文本文件的时候,发现文本中的格式已经没有意义了,只是一个普通的字符
5.2.1. 写特殊字符进文件
int main()
{
FILE *fpw = fopen("bin.txt", "wb");
if (fpw == NULL)
exit(-1);
char *p = "china \n is \0 great";
fwrite(p, 1, strlen(p) + 6, fpw);
fclose(fpw);
return 0;
}
5.2.2. 从文件中读特殊字符
int main()
{
FILE *fpr = fopen("bin.txt", "rb");
if (fpr == NULL)
exit(-1);
char buf[1024];
int n;
n = fread(buf, 1, 1024, fpr);
printf("n = %d\n", n);
for (int i = 0; i < n; i++)
{
printf("%#x\n", buf[i]);
}
fclose(fpr);
return 0;
}
5.2.3. 返回值陷阱
没有\n/EOF/len-1作为读出的结束标志,fread依靠读出块多少来标识读结果和文件结束标志。
以最小的单元格式进行读,或是以写入的最小单元进行读。
int main()
{
char buf[1024] = "12345678";
FILE *pf = fopen("bin.txt", "w+");
if (NULL == pf)
exit(-1);
// fwrite((void *)buf, 1, 8, pf);
fwrite((void *)buf, 8, 1, pf);
rewind(pf);
char read[10];
// 读到完整块的个数
int n;
// n = fread((void *)read, 1, 8, pf); // n = 8
// printf("n = %d\n", n);
// n = fread((void *)read, 1, 8, pf); // n = 0
// printf("n = %d\n", n);
// n = fread((void *)read, 8, 1, pf); // n = 1
// printf("n = %d\n", n);
// n = fread((void *)read, 8, 1, pf); // n = 0
// printf("n = %d\n", n);
// n = fread((void *)read, 7, 1, pf); // n = 1
// printf("n = %d\n", n);
// n = fread((void *)read, 7, 1, pf); // n = 0
// printf("n = %d\n", n);
// n = fread((void *)read, 3, 1, pf); // n = 1
// printf("n = %d\n", n);
// n = fread((void *)read, 3, 1, pf); // n = 1
// printf("n = %d\n", n);
// n = fread((void *)read, 3, 1, pf); // n = 1
// printf("n = %d\n", n);
// n = fread((void *)read, 1, 3, pf); // n = 3
// printf("n = %d\n", n);
// n = fread((void *)read, 1, 3, pf); // n = 3
// printf("n = %d\n", n);
// n = fread((void *)read, 1, 3, pf); // n = 2
// printf("n = %d\n", n);
// n = fread((void *)read, 1, 3, pf); // n = 0
// printf("n = %d\n", n);
while ((n = fread((void *)read, 1, 3, pf)) > 0)
{
for (int i = 0; i < n; i++)
{
printf("%c", read[i]);
}
}
fclose(pf);
return 0;
}
5.3. 二进制读写才是本质
当用UE打开一个二进制文件(图片,视频)时,发现文件中到处都是文本的标志性字符,但是对于fread和fwrite来说,都是一个普通的字节;所以二进制文件的读写就要用对文本标记不敏感的fread和fwrite来进行
int main()
{
int a[10] = {0xff, 0x0, 10, 2, 3, 4, 5, 6, 7, 8};
FILE *fp = fopen("xx.txt", "wb+"); // xx.txt文件打开是乱码
if (fp == NULL)
return -1;
fwrite(a, sizeof(int[10]), 1, fp);
rewind(fp);
int n = 0;
int data;
while ((n = fread(&data, sizeof(int), 1, fp)) > 0)
{
printf("n = %d data = %x \n", n, data);
}
fclose(fp);
return 0;
}
5.3.1. 文件的加密与解密
加密语法格式
file -d src.wmv sec.wmv
file -x sec.wmc anohtersrc.wmv
// xx.ext -c src dest
// xx.exe -d src dest
// argv[0] argv[1] argv[2] argv[3]
void encode(char *buf, int n)
{
for (int i = 0; i < n; i++)
{
buf[i]++;
}
}
void decode(char *buf, int n)
{
for (int i = 0; i < n; i++)
{
buf[i]--;
}
}
int main(int argc, char *argv[])
{
if (argc != 4)
{
printf("use xx.exe -d[-c] src dest\n");
exit(-1);
}
FILE *pfr = fopen(argv[2], "rb+");
if (pfr == NULL)
exit(-1);
FILE *pfw = fopen(argv[3], "wb+");
if (pfw == NULL)
{
fclose(pfr);
exit(-1);
}
int buf[1024];
int n;
// 加密
if (strcmp(argv[1], "-c") == 0)
{
while ((n = fread((void *)buf, 1, 1024, pfr)) > 0)
{
encode(buf, n);
fwrite((void *)buf, 1, n, pfw);
}
}
// 解密
else if (strcmp(argv[1], "-d") == 0)
{
while ((n = fread((void *)buf, 1, 1024, pfr)) > 0)
{
decode(buf, n);
fwrite((void *)buf, 1, n, pfw);
}
}
else
{
printf("arg error\n");
}
fclose(pfr);
fclose(pfw);
return 0;
}
5.4. 读写结构是长项
结构体中的数据类型不统一,此时最时候用二进制的方式进行读写。二进制的接口可以读文本,而文本的接口不可以读二进制
// 结构体会采用fread/fwrite来写
// 1. 类型不同意
// 2. 可以将二进制转化为文本,使其统一,降低效率,占用多余的存储空间
typedef struct student
{
int num;
char name[30];
char sex;
float math;
float english;
float chinese;
} Stu;
// 写
int main22()
{
Stu s[3] = {
{1001, "wukong", 'x', 99, 99, 99},
{1002, "songjiang", 'x', 66, 44, 88},
{1003, "baoyu", 'x', 22, 66, 88},
};
FILE *pfs = fopen("stu.data", "w+");
if (pfs == NULL)
exit(-1);
for (int i = 0; i < 3; i++)
{
fwrite((void *)&s[i], sizeof(Stu), 1, pfs);
}
fclose(pfs);
return 0;
}
int main()
{
FILE *pfw = fopen("stu.data", "r+");
if (pfw == NULL)
exit(-1);
Stu s[3];
int n;
while (n = fread((void *)s, sizeof(Stu), 1, pfw) > 0) // 3 2 0
{
for (int i = 0; i < n; i++)
{
printf("num = %d\n", s[i].num);
printf("name = %s\n", s[i].name);
printf("sex = %c\n", s[i].sex);
printf("math = %.2f\n", s[i].math);
printf("english = %.2f\n", s[i].english);
printf("chinese = %.2f\n", s[i].chinese);
printf("======\n");
}
}
return 0;
}
5.5. 练习-管理系统
将链表作为内存数据模型,将文件作为数据库,将终端作为交互界面,读文件生成链表,修改链表写入文件。
5.5.1. 初始化数据库
typedef struct student
{
char name[30];
char sex;
int age;
float score;
} Stu;
typedef struct _StuNode
{
Stu data;
struct _StuNode *next;
} StuNode;
void initData2File() {
Stu s[4] = {
{"liudehua", 'x', 50, 100},
{"zhangxueyou", 'x', 60, 90},
{"liming", 'x', 40, 80},
{"guofucheng", 'x', 60, 95},
};
FILE *pf = fopen("stu.data", "w+");
if (NULL == pf)
exit(-1);
fwrite((void *)s, sizeof(s), 1, pf);
fclose(pf);
return;
}
这个函数将初始化一个学生数据的数组,并将其写入一个名为 stu.data 的文件中。如果文件打开失败,程序将退出。
5.5.2. 读数据库,生成内存数据模型,链表
StuNode *createListFromFile(char *filePath) {
FILE *pf = fopen(filePath, "r+");
if (NULL == pf)
exit(-1);
StuNode *head = (StuNode *)malloc(sizeof(StuNode));
head->next = NULL;
StuNode *cur = (StuNode *)malloc(sizeof(StuNode));
while (fread((void *)&cur->data, sizeof(Stu), 1, pf)) {
cur->next = head->next;
head->next = cur;
cur = (StuNode *)malloc(sizeof(StuNode));
}
free(cur);
return head;
}
指定文件中读取学生数据,并将其转换为链表形式。读取每个学生数据时,创建一个新的链表节点并插入到链表头部
5.5.3. 遍历链表
void traverseStuList(StuNode *head) {
printf("\t\t\t Student Management System\n\n");
printf("\tname\t\t\tsex\t\tage\t\tscore\n");
head = head->next;
while (head) {
printf("\t%-10s\t\t%c\t\t%d\t\t%.2f\t\t\n", head->data.name, head->data.sex, head->data.age, head->data.score);
head = head->next;
}
putchar(10);
}
5.5.4. 添加学生节点
void addListStu(StuNode *head) {
StuNode *cur = (StuNode *)malloc(sizeof(StuNode));
printf("name:");
scanf("%s", cur->data.name);
getchar();
printf("sex:");
scanf("%c", &cur->data.sex);
getchar();
printf("age:");
scanf("%d", &cur->data.age);
getchar();
printf("score:");
scanf("%f", &cur->data.score);
cur->next = head->next;
head->next = cur;
}
创建一个新的学生节点并将其插入到链表头部。
5.5.5. 查找学生
StuNode *searchListStu(StuNode *head) {
char name[30];
printf("pls input your search name:");
scanf("%s", name);
head = head->next;
while (head) {
if (strcmp(head->data.name, name) == 0)
break;
head = head->next;
}
return head;
}
根据学生姓名在链表中查找学生并返回对应的节点。
5.5.6. 删除学生节点
void deleteListStu(StuNode *head) {
StuNode *pfind = searchListStu(head);
if (pfind == NULL) {
printf("删除的不存在");
getchar();
getchar();
return;
}
while (head->next != pfind)
head = head->next;
head->next = pfind->next;
free(pfind);
return;
}
首先查找要删除的学生节点,然后从链表中删除该节点并释放其内存。
5.5.7. 链表长度
int lenListStu(StuNode *head) {
int len = 0;
head = head->next;
while (head) {
len++;
head = head->next;
}
return len;
}
5.5.8. 排序链表
void sortListStu(StuNode *head) {
int len = lenListStu(head);
StuNode *prep, *p, *q;
for (int i = 0; i < len - 1; i++) {
prep = head;
p = prep->next;
q = p->next;
for (int j = 0; j < len - 1 - i; j++) {
if (strcmp(p->data.name, q->data.name) > 0) {
prep->next = q;
p->next = q->next;
q->next = p;
prep = q;
q = p->next;
continue;
}
prep = prep->next;
p = p->next;
q = p->next;
}
}
}
5.5.9. 将链表保存到文件
void saveList2File(StuNode *head, char *filePath) {
FILE *pf = fopen(filePath, "w+");
if (pf == NULL)
exit(-1);
head = head->next;
while (head) {
fwrite((void *)&head->data, sizeof(Stu), 1, pf);
head = head->next;
}
fclose(pf);
}
5.5.10. 销毁链表
void destroyListStu(StuNode *head) {
StuNode *t;
while (head) {
t = head;
head = head->next;
free(t);
}
}
5.5.11. 主函数
void main() {
// initData2File();
StuNode *head = createListFromFile("stu.data");
while (1) {
system("cls");
traverseStuList(head);
printf("1->add\t 2->search\t 3->delete\t 4->exit\n");
int choice;
StuNode *pfind;
scanf("%d", &choice);
switch (choice) {
case 1:
addListStu(head);
break;
case 2:
if (pfind = searchListStu(head)) {
printf("能找到");
printf("\t%-10s\t\t%c\t\t%d\t\t%.2f\t\t\n", pfind->data.name, pfind->data.sex, pfind->data.age, pfind->data.score);
} else {
printf("找不到");
}
getchar();
getchar();
break;
case 3:
deleteListStu(head);
break;
case 4:
sortListStu(head);
break;
case 5:
saveList2File(head, "stu.data");
destroyListStu(head);
return;
default:
printf("输入有误");
}
}
}
6. 文件指针偏移
6.1. rewind
函数声明:void rewind(FILE * stream)
所在文件:stdio.h
函数功能:将文件指针重新指向一个流的开头
参数:FILE *:流文件句柄
返回值:void:无返回值
如果一个文件具有读写属性,当写完文件需要读的时候,会遇到文件结尾的现象,此时就需要rewind
6.2. ftell
函数声明:long ftell(FILE * stream)
所在文件:stdio.h
函数功能:得到流式文件的当前读写位置,其返回值是当前读写位置偏离文件头部的字节数
参数:FILE *:流文件句柄
返回值:int:成功,返回当前读写位置偏离文件头部的字节数。失败,返回-1
6.3. fseek
函数声明:int fseek(FILE * stream, long offset, int where);
所在文件:stdio.h
函数功能:偏移文件指针
参数:FILE * stream:文件句柄;long offset:偏移量;int where:偏移起始位置
返回值:int:成功返回0,失败返回-1
常见的起始位置有宏定义:
#define SEEK_CUR 1 当前位置
#define SEEK_END 2 文件结尾
#define SEEK_SET 0 文件开头
fseek(fp, 100L, 0); // 把fp指针移动到离文件开头100字节处
fseek(fp, 100L, 1); // 把fp指针移动到离文件当前位置100字节处
fseek(fp, 100L, 2); // 把fp指针退回到离文件结尾100字节处
int main()
{
FILE *pf = fopen("xx.txt", "w+");
fputs("abcdefg", pf);
int n = ftell(pf);
printf("n = %d\n", n); // n = 7
rewind(pf);
n = ftell(pf);
printf("n = %d\n", n); // n = 0
fseek(pf, 0, SEEK_END);
n = ftell(pf);
printf("n = %d\n", n); // n = 7
fseek(pf, 0, SEEK_SET);
n = ftell(pf);
printf("n = %d\n", n); // n = 0
fseek(pf, 1, SEEK_CUR);
n = ftell(pf);
printf("n = %d\n", n); // n = 1
return 0;
}