之所以爬这个网站,是因为一位朋友也在爬,而且推荐了一下给我,说作为练手很不错,于是我就是爬了,于是这网站写了我差不多五天,写得我真是呕心沥血啊,好了,先看网站要提取哪些数据,这次要爬的是广告合同纠纷案件

Paste_Image.png
箭头是要爬取的内容,为案件的主要内容,以及每个案件的wensuhID类型,时候个post请求,需要上传的data是下面这个,可以在chrome上看到
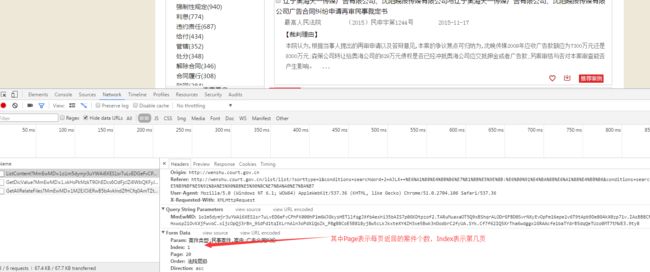
Paste_Image.png
好的开干,先看代码框架

Paste_Image.png
先看数据库mogo_data的代码,很多操作要用到这里的代码
from pymongo import MongoClient,errors
from _datetime import datetime,timedelta
class mogo_queue():
OUTSTANDING = 1 ##初始状态
PROCESSING = 2 ##正在爬取状态
COMPLETE = 3 #爬取完成的状态
def __init__(self,db,collection,timeout=60):
self.client = MongoClient()
self.database =self.client[db]#链接数据库
self.db = self.database[collection]#链接数据库里面这个表
self.timeout = timeout
def __bool__(self):
"""
这个函数,我的理解是如果下面的表达为真,则整个类为真
$ne的意思是不匹配
"""
record = self.db.find_one(
{'status': {'$ne': self.COMPLETE}}
)
return True if record else False
def find_proxy(self):
proxy_list=[]#用来接收从数据库查找到的所有代理
for i in self.db.find():
proxy = i['proxy']
proxy_list.append(proxy)
return proxy_list
def select_data(self):#一旦取走一个data,data的状态就要改变,防止多进程重复提取
record = self.db.find_and_modify(
query={'status': self.OUTSTANDING},
update={'$set': {'status': self.PROCESSING, 'timestamp': datetime.now()}}
)
if record:
return record['data']
else:
self.repair()
raise KeyError
def repair(self):#这个函数是把超时的没有爬取成功的data的
# 状态改变,跟之前爬宜搜的功能一样,防止漏抓
"""这个函数是重置状态$lt是比较"""
record = self.db.find_and_modify(
query={
'timestamp': {'$lt': datetime.now() - timedelta(seconds=self.timeout)},
'status': {'$ne': self.COMPLETE}
},
update={'$set': {'status': self.OUTSTANDING}}
)
if record:
print('重置data状态', record['data'])
def complete(self, id):
"""这个函数是更新已完成的URL完成"""
self.db.update({'_id': str(id)}, {'$set':{'status':self.COMPLETE}})
print('data的status状态转为完成')
def insert_data(self,data,id):
try:
self.db.insert({'_id':id,'data':data})
print(data,'插入成功')
except errors.DuplicateKeyError as e:#对于重复的ip不能插入
print(id,'已经存在队列中')
def push_data(self,page):#把需要提交的data装进数据库
for i in range(1, page):
data = {
'Param': '案件类型:民事案件,案由:广告合同纠纷',
'Index': str(i),
'Page': '20',
'Order': '法院层级',
'Direction': 'asc',
}
try :
self.db.insert({'_id':data['Index'],'data':data,'status':self.OUTSTANDING})
print(data,'插入成功')
except errors.DuplicateKeyError as e:
print(data, '已经存在队列中')
def status_setting(self):#这函数,如果data都抓取成功了一般不启用.....
record = self.db.find({'status': self.PROCESSING}) # 找到所有状态为2的代理,就是之前抓取过的
for i in record:
#print(i)
id = i["_id"]
self.db.update({'_id': id}, {'$set': {'status': self.OUTSTANDING}}) # 该状态为1,重新抓取
print(i['data'], '更改成功')
这是push_data的代码,很简单几行,就是把需要提取的data存进数据库
from mogo_data import mogo_queue
data_queue= mogo_queue('wenshu','data_index')
data_queue.push_data(357)#把需要爬取的data传进去
好了,到了爬虫主程序,这个真的写得我要死要死的
import re
import time
import requests
import threading#用于创建线程
import json
from bs4 import BeautifulSoup
from mogo_data import mogo_queue
import time
import random
import multiprocessing#用于创建多进程的
from pymongo import MongoClient
user_agent_list=['Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.9.2.1000 Chrome/39.0.2146.0 Safari/537.36',
#'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24',
'Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/532.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/532.3',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5',
#'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]#这些请求头都是我测试过非常高效的,
#而且这网站很奇葩,主要是IE的请求头访问都会出错
data_queue = mogo_queue('wenshu', 'data_index_two') # 实例化需要提交的data
url='http://wenshu.court.gov.cn/List/ListContent?'
def catch_wensuh_judge(max_threads=3):
writ_data = mogo_queue('China_judge_writ', 'advertisement_writ') # 实例化,储存文书数据的数据库
ip_queue = mogo_queue('ip_database', 'proxy_collection') # 实例化代理池
def wenshu_crawler():
while True:
try:
data=data_queue.select_data()#选择data
print(data)
except KeyError:
print('队列没有数据')
break
else:
Agent = random.choice(user_agent_list)
proxie_list = ip_queue.find_proxy()#提取代理
proxy = random.choice(proxie_list)
headers = {
'User-Agent': Agent,
'Referer': 'http://wenshu.court.gov.cn/List/List?sorttype=1&conditions=searchWord+2+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E6%B0%91%E4%BA%8B%E6%A1%88%E4%BB%B6',
#'Referer': 'http://wenshu.court.gov.cn/List/List?sorttype=1&conditions=searchWord+2+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E6%B0%91%E4%BA%8B%E6%A1%88%E4%BB%B6'
}
proxie = {
'http': proxy.strip(),
'https': proxy.strip()
}
time.sleep(5)
try:
html = requests.post(url, data=data, proxies=proxie, headers=headers, timeout=10) # headers=headers
status_number = re.findall(r'\d\d\d', str(html))[0]#提取网页返回
length = len(html.text)
print(proxie,headers)
print(html.text)
if status_number==str(200):#判断网页是否正常返回
if int(length) >=int(1000):#判断网页返回的是否是正常内容
try:
content = BeautifulSoup(html.text, 'lxml')
we_data = re.findall(r'\[(.*)\]', str(content), re.S)
all_data = re.sub(r'\\', '', str(we_data))
all_case = all_data.split('}')[1:-1]
for i in all_case:
info = i + '}'
the_case = info.replace(',', '', 1) # 清理数据里面的符号,然后转化成字典
one_case = json.loads(the_case) # 转化成字典
wensuh_data = {
'案号': one_case['案号'] if one_case['案号'] else '该文书没有此项数据',
'案件类型': one_case['案件类型'] if one_case['案件类型'] else '该文书没有此项数据',
'法院名称': one_case['法院名称'] if one_case['法院名称'] else '该文书没有此项数据',
'审判程序': one_case['审判程序'] if one_case['审判程序'] else '该文书没有此项数据',
'案件名称': one_case['案件名称'] if one_case['案件名称'] else '该文书没有此项数据',
'裁判日期': one_case['裁判日期'] if one_case['裁判日期'] else '该文书没有此项数据',
'裁判要旨段原文': one_case['裁判要旨段原文'] if one_case['裁判要旨段原文'] else '该文书没有此项数据',
#'文书ID': one_case['文书ID'] if one_case['文书ID'] else '该文书没有此项数据',
} # 有些文书不一样,所以要在字典里面添加判断语句
id=one_case['文书ID']
writ_data.insert_data(wensuh_data,id)
data_queue.complete(data['Index'])#数据插入成功调用这个函数
except:
continue#失败了再来
else:
time.sleep(2)
continue#失败了再来
else:
time.sleep(2)
continue#失败了再来
except:
time.sleep(1)
continue#失败了再来
threads = []
while threads or data_queue:
"""
这儿crawl_queue用上了,就是我们__bool__函数的作用,为真则
代表我们MongoDB队列里面还有data没有提交进行抓取或者
threads 为真,都代表我们还没下载完成,程序就会继续执行
"""
for thread in threads:
if not thread.is_alive(): ##is_alive是判断是否为空,不是空则在队列中删掉
threads.remove(thread)
while len(threads) < max_threads: ##线程池中的线程少于max_threads
thread = threading.Thread(target=wenshu_crawler) ##创建线程
thread.setDaemon(True) ##设置守护线程
thread.start() ##启动线程
threads.append(thread) ##添加进线程队列
time.sleep(10)
def process_crawler():
process = []
num_cpus = multiprocessing.cpu_count()
print('将会启动进程数为:', int(num_cpus)-6)
for i in range(int(num_cpus)-6):
p = multiprocessing.Process(target=catch_wensuh_judge) ##创建进程
p.start() ##启动进程
process.append(p) ##添加进进程队列
for p in process:
p.join() ##等待进程队列里面的进程结束
if __name__ == "__main__":
data_queue.status_setting()#启用了这个函数将data状态由2改为1,
# 是因为我之前抓取失败了,要重新改了再来.....
process_crawler()
最后说一下,成功抓取的案件只有2000左右,但是我看他网页上的介绍,说广告合同纠纷是有7000个案件的,于是傻乎乎的构造了300多个data,只有100个抓取成功了,于是我又调节了很久我的爬虫,是不是代理问题啊,是不是主程序问题啊,用了很多可信的IP和请求头测试,最后发现这网站能抓取的本来就只有100个data,超出之后的,从101页开始,返回的都是空集,是None,真是日了狗....可是我不服啊,不可能啊明明写着7000个案件啊,于是我想手点到101页,结果在30多页的时候就提醒你,精确度不够,没有数据返回,提醒我进行精确查找...........于是我深深怀疑这方式能提取到的数据真的就只有这么多了,最后上两者效果图

Paste_Image.png
数据库图

Paste_Image.png
写得我见到这个网站都恶心了