- 前言
- 经典操作系统的虚拟内存
- 为什么要有虚拟内存?
- 寻址方式
- 地址空间
- 分页
- 缺页处理
- 虚拟内存带来的好处
- 地址翻译
- 如何索引
- 提高效率
- 减少内存
- 现代 OS 虚拟内存系统
- 内存映射 MMAP
- MMAP在iOS中的用处
- 动态内存分配
- 隐式内存分配器
- 显式内存分配器
- 如何实现一个自己的显式内存分配器
- 实现显式内存分配器的重点
- 显式内存分配器的实现方案
- 隐式空闲链表
- 显式空闲链表
- 显式内存分配器的实现
- iOS的虚拟内存
- iOS 内存的分页大小
- 页面的类型
- iOS内存的优化
- iOS 进程中的堆和栈
- iOS平台上的常见编程语言的内存管理方式
- 内存分类
- Virtual Memory分类
- PhySical Memory
- 内存测量工具
- 命令行工具
- Xcode 提供的工具
- 代码工具
- 线上检查工具
- 高性能使用内存
- 参考
- 写在最后
前言
仅以此文解答自己大学以来多年对内存管理的疑惑。
经典操作系统的虚拟内存
为什么要有虚拟内存?
随着计算机的发展,我们的计算机处理的任务也变得越来越繁多,但是对于某台固定的计算机,CPU 和 Memory 都是固定的,如果有些直接使用物理内存地址的话会带来很多问题, 首先编译器不能以一种抽象的角度来描绘内存,在执行的过程中如果某个进程占据的内存过大,这个进程可能就无法运行,即便运行了内存相对来说是非常不安全的,一个不小心操作到了别的进程的内存,可能导致进程的崩溃,如果写入了内核使用的内存可能导致操作系统的崩溃。
现代操作系统的内存管理是非常多计算机科学家智慧的结晶,这种管理方式就是 虚拟内存 (Virtual Memory/VM). VM是一些列技术的总称,包括硬件异常,物理之地翻译,主存,磁盘文件,操作系统内核软件的内存管理。
虚拟内存提供了三大重要的特性
- 它将主存看做在存储在磁盘上的地址空间的高速缓存,利用程序的局部性原理,只将活跃的内存加载到主存中,提高了主存的利用率。
- 为每个进程提高了一个抽象的统一的连续的私有的地址空间。简化了内存管理方式。
- 对内测进行分段(segment)提供权限能力,保护每个进程的地址空间不会被其他进程影响。
寻址方式
在一些早期的操作系统和一些嵌入式操作系统中,内存管理使用的地址是物理地址,
现代操作系统基本使用的是 虚拟地址(Virtual Addressing)的寻址方式,使用 虚拟地址时 CPU将 VA 送到MMU中去翻译为物理地址。
注: MMU (Memory Management Unit) 内存管理单元一般是一个CPU上的专用芯片,是一个硬件。
结合操作系统共同完成地址翻译工作。
地址空间
通常来说地址空间是线性的 假设我们有 {0, 1, 2, ..N-1 } 个内存地址,我们可以用n位二进制来表示内存地址,那么我们就叫这个地址空间为n位地址空间, 现代操作系统通常是 32 或者 64(但是很多操作系统只用了48位寻址)的 。
2^10 = 1k
2^20 = 1M
2^30 = 1G
2^40 = 1T
2^50 = 1P
2^60 = 1E
这么看来大家能理解为什么32位的操作系统最大只支持4G内存空间了。
分页
现代操作系统将内存划分为页,来简化内存管理,一个页其实就是一段连续的内存地址的集合,通常有4k和16k(iOS 64位是16K)的,成为 Virtual Page 虚拟页。与之对应的物理内存被称为Physical Page 物理页。
注意 虚拟页的个数可能和物理页个数不一样 比如说一个 64位操作系统中使用48位地址空间的 虚拟页大小为16K,那么其虚拟页可数可达到(248/214 = 16M个)假设物理内存只有 4G 那么物理页可能只有 (232/214 = 256k个)
操作系统将虚拟页和物理页的映射关系称为页表(Page Table),每个映射叫 页表条目(Page Table Entry/Item),操作系统为每个进程提供一个页表放在主存中,CPU在使用虚拟地址时交给MMU去翻译地址,MMU去查询在主存中的页表来翻译。
缺页处理
每个 Page Table Entry 都包含了一些描述信息,比如前页的状态{未分配, 缓存的,未缓存的}。
- 未分配的不用多说代表未使用的内存
- 缓存的代表已经加载进物理内存了
- 未缓存的代表还没放在物理内存。
当CPU要读取一个页时,检查标记发现当前的页是未缓存的,会触发一个(Page Falut)缺页中断,这时内核、、操作系统的缺页异常处理程序,去选择一个牺牲页(有时候内存够用不用置换别的界面),然后检查这个页面是否有修改,有修改先写会磁盘,然后将需要使用到的内存加载到物理内存中,然后更新PTE 随后操作系统重新把虚拟地址发送到地址翻译硬件去重新处理。
注: 有些操作系统无 虚拟虚拟内存置换逻辑,如iOS,取而代之的是内存压缩,和收到内存警告时杀死进程的行为。
虚拟内存带来的好处
- 简化链接过程,允许每个进程都提供统一的内存地址的抽象,独立与物理内存。
- 简化加载,操作系统加载可执行文件和共享文件时,只是创建了 页表,待访问到缺页时,操作系统再去加载。
- 简化共享,不同进程的PT中的PTE 可以执行相同的物理地址,如动态库的代码。
- 内存保护,PT中的PTE中描述了一个虚拟页的权限信息,(R, W, X)、指令如果违反了这些权限信息,就会造成(Segment Fault)
地址翻译
虚拟地址翻译到物理地址是软硬件结合实现的。我们通常几个方面来描述。
如何索引
现代操作系统将地址分为两部分,页号和片了(是不是很类型网络号和主机号),由于虚拟页和物理页的大小是相同的,页偏移可以看做虚拟页和物理页的页内地址,且相同,页号则做为PT的索引查找到对应的PTE,然后查找对应的物理页地址。
提高效率
是不是像前面所说的简单的划分位两部分就足够了呢?
举个例子:
- 我们假设一台电脑是 32 位的,分页大小位 4k 也就说页内地址占据了 12 位,页号地址位 20 位
- 我们假设一台电脑是 64 位的,地址空间 48 位,分页大小位 16k 也就说页内地址占据了 14 位,页号地址位 34 位
我们粗略估算一个PTE为4KB 对于 32位的操作系统每个进程的页表需要 2^20 = 4M 个页表项常驻内存尚可接受
但是对于寻址为48位的操作系统来说,每个进程的页表为需要 2^32 = 4G个页表项,这是无法接受的。
计算机的世界所有的难题都可以同加一次的办法来解决,所以现代操作系统通常都使用多级页表,减少页表项的个数。将虚拟地址分为多端,代表了一级 二级 多级页表。通过多级页表可以大大较少内存占用。
减少内存
众所周知CPU要比Memory快10^3个数量级,即便CPU中的L3Cache 也比Memory快很多,如果MMU美的地址翻译都要去查找多级PT,这个开销就会非常巨大,但是所幸 程序的局部性原理能够解救我们,MMU芯片内置一个 翻译后备缓冲器(Transalation Lookaside Buffer TLB )的硬件来充当缓存,加快地址翻译的效率.
现代 OS 虚拟内存系统
操作系统为每个进程维护一个单独的虚拟地址空间,分为两部分。
- 内核虚拟内存,包含内核中的代码和数据结构,还有一些被映射到所有进程共享的内存页面。还有一些页表,内核在进程上下文中执行代码使用的栈。
- 进程虚拟内存。OS将内存组织为一些区域(Sement)的集合,代码端,数据端,共享库端,线程栈都是不同的区域,分段的原因是便于管理内存的权限,如果了解过Mach-O文件或者ELF文件的读者可以看到相同的Segment里面的内存权限是相同的,每个Segment再划分不同的内容为section。
在内核中描述一个进程的数据结构 概略为如下
pgb指向第一级页表的基址
进程虚拟地址
vm_area_struct |----------------|
---- ---- |----> vm_end------| | |
mm ---> pgb | vm_start ---|---| | |
---- mmap --- vm_prot | |->|----------------|
---- vm_flags | | 共享库 |
-- vm_next |----->|----------------|
| |
| |
|-> vm_end-----| |--> |----------------|
vm_start---|--| | 数据段 |
vm_prot |------>|----------------|
vm_flags |
每个区域的描述主要有一下几个
vm_start 指向这个区域的起始处
vm_end 指向这个区域的结束出
vm_prot 内存区域的读写权限
vm_flasg 一些标志位 私有的还是共享的
vm_next 指向下一个vm_area_struct的描述
内存映射 MMAP
类Unix操作系统可以荀彧映射一个普通磁盘上的文件的连续部分到一个固定的内存取区域。操作系统会会自动管理映射的内容。
内存映射允许不同的进程映射不同的虚拟内存到同一块物理内容上,他们可以是共享的也可以是私有的。
对于共享的,通常多个进程映射到相同的共享对象上,
对与私有的,不同进程初始映射的时候操作系统为了节省资源,并没有产生真的副本,知道某个进程修改了这个私有对象,操作系统运用copy on write技术在此时才发生真正的文件拷贝。
mmap在类unix操作系统上作为一个系统调用存在,函数签名如下
void *
mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
addr 代表要从那块虚拟地址开始映射,通常可以不用指定传递NULL让操作系统自己给我们选择
len 映射多少长度的内容
prot 映射文件的访问权限 读写可执行权限等
PROT_EXEFC 可执行权限
PROT_READ 可读权限
PROT_WRITE 可写权限
PROT_NONE 无法访问权限
flags 访问文件的标记
MAP_SHARED 共享的
MAP_PRIVATE私有的
MAP_ANON 私有的
举个例子将任意文件映射到stdout
#include
int main(int argc, const char * argv[]) {
struct stat stat;
int fd;
if (argc != 2) {
printf("must pass file path");
return 1;
}
fd = open(argv[1], O_RDONLY, 0);
fstat(fd, &stat);
char *buffer = mmap(NULL, stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
printf("%s", buffer);
return 0;
}
MMAP在iOS中的用处
- mmap让读写一个文件像操作一个内存地址一样简单方便,
- mmap效率极高,不用将一个内容从磁盘读入内核态再拷贝至用户态
- mmap映射的文件由操作系统接管,如果进程Crash 操作系统会保证文件刷新回磁盘
动态内存分配
虽然可以使用上面的低级API去映射内存,但是需要动态申请内存用来做变量处理的时候就需要动态内存分配器(Dunamic memory allocator)简单理解为 malloc calloc realloc free等函数来自的库就称为DMA.
动态内存分配器将一个内存的区域(Heao)分为不同的大小的块(block),这些块要不然就是分配的,要不然就是空闲的。
如何设计分配器又是一个大难题。 几乎所有的计算机语言都采用以下两种。
- 显式分配器(手动管理内容)
- 隐式分配器(GC)
隐式内存分配器
通常比较知名的语言 Java javaScript Ruby 等都使用GC,最早的GC只是使用标记清除算法来管理内容,通过几十年的迭代,早已更新出了数种算法共同参与的GC。这里就不再赘述了
显式内存分配器
C语言提供了一些列的方法来管理动态内存。如
- malloc 申请内容并返回初始化的内存首地址
- calloc 同malloc一致,并且会将申请到的内存全置为0、
- realloc,重新分配原本已经申请的内存空间。
- free 释放内容空间
- sbrk 扩展收缩堆
如何实现一个自己的显式内存分配器
首先我们要明确内存分配器的需求
- 处理任意顺序的申请内存和释放内存
- 立即响应,不应为了性能二重新排列或者缓存请求
- 所有内容都在heap里存放
- 对齐块,使之可以存放任意类型的数据
- 不修改已分配的内存块
鉴于对齐和处理任意顺序内存管理的需求,堆利用效率可能会降低,主要会产生内存碎片(Fragmentation) 内存碎片分为两种。
- 内部碎片,通常是指一个分配过的块数据并不是全部块的内容,通常有元信息,对齐的字节等。
- 外部碎片是指不连续的可用的块,通常外部碎片过多会产生,所有空白块相加可以满足申请的资源,但是他们不连续。需要整理碎片。
实现显式内存分配器的重点
- 空闲块组织
- 如何分配新申请的块
- 如果组织空闲快的剩余部分
- 如何合并刚释放的块
显式内存分配器的实现方案
隐式空闲链表
这种方式在malloc申请内存的时候,实际上申请的是实际所需内存加上部门元信息大小的块,然后返回指针是有效数据的首地址,元信息直接存在数据块中,所以称为隐式空闲链表。
隐式链表需要处理如何分割空闲库和合并空闲快
显式空闲链表
由于隐式空闲链表的搜索效率角度,其实是不适用通用的内存分配的。可以使用某种形式的数据结构去管理这些内存块。
基本分为 几种,
- 简单分离器存储
- 分离适配法
- 伙伴系统法
关于详细的设计需要读者查看更多算法知识的文档。
显式内存分配器的实现
显式内存分配器的需求已经很清晰,下面有个简单的例子可以参考,这时候对于 C 类语言的内存管理应该不会太过恐惧了,
C++实现一个简易的内存池分配器,
毕竟源码面前了无秘密。
iOS的虚拟内存
iOS 内存的分页大小
在arm64之后的芯片,操作系统通常使用16KB作为页大小,我们写的程序中的虚拟内存地址右移动14位则可得到页编号。MMU通过TLB和固定在内存进程虚拟区域的页表来翻译来物理地址。
下面一份代码可以获取页大小。
int main(int argc, char * argv[]) {
// 获取虚拟内存分页数据 14为页内地址
printf("page-size%ld mask:%ld, shift%d \n", vm_kernel_page_size, vm_kernel_page_mask, vm_kernel_page_shift);
printf("%ld\n", sysconf(_SC_PAGE_SIZE));
printf("%d\n", getpagesize());
printf("%d\n", PAGE_SIZE); // 编译时确定不建议使用
return 0;
}
在观察Crash日志的时候 有时候注意崩溃的页号可以帮助我们寻找崩溃的原因。
页面的类型
当操作系统分配一个页面时,内存被称为Clean的,以为这这个内存页面没有使用,是可以被释放或者重建的,但是一旦写入,操作系统会将其标记为Dirty,这意味着磁盘或者其他地方没有此内存页面的备份,无法恢复它。
由于iPhone设备为了减少闪存的寿命,并没有在闪存上使用交换分区,因此无论使用多少,在内存压力高紧时,操作系统不会将Dirty写好磁盘,而是释放Clean的页面如,可执行代码(Mach-O)的映射和内存映射文件,或者是kill掉进程。
因此使用dirty的内存越多,对我们的进程的稳定性越差。
iOS内存的优化
在其他常见的操作系统上,由于局部性原理,OS会将不常用的内存页面写会磁盘,但是iOS没有交换空间,取而代之的是内存压缩技术,iOS 将不常用到的dirty页面压缩以减少页面占用量,在再次访问到的时候重新解压缩。这些都在操作系统层面实现,对进程无感知,有趣的是如果当前进程收到了 memoryWarning, 进程这时候准备释放大量的误用内存,如果访问到过多的压缩内存,再解压缩内存的时候反而会导致内存压力更大,然后被OS kill掉。
iOS 进程中的堆和栈
需要注意的是通常操作系统书籍中描述的进程虚拟内存模型都是这样的
[图片上传失败...(image-a1d525-1538764389522)]
这实际是个用于解析给读者的简化模型,对于多线程程序来说,每个线程都有自己的线程栈,在iOS上通常主线程线程栈大小为1MB,子线程栈大小为 512KB,如果你有一台越狱机 可以试验 ulimt -a 命令观察栈大小的默认参数。
iOS平台上的常见编程语言的内存管理方式
iOS 上常用的Swift 和 Objective-C ,C , C++ 都使用显式的内存管理�策略,比如 malloc 和 free, new 和delete alloc 和 dealloc,在Objective-C和Swift通常使用一种叫做引用计数的简化模型来管理堆内存。现代Clang已经支持ARC的技术帮助程序员解脱内存管理的困扰,但是本质上还是显式内存管理。
建议读者可以读一下ARC的参考文档,
顺便提一下Xcode10 版本中的Clang已经支持在C结构体中对于Objective-C对象的ARC管理,请参看 whats_new_in_llvm
内存分类
要想合理的使用内存必须要掌握不同类型内存的区别,才能更合理的使用内存并且在内存资源匮乏的低端机器上写出“高内存性能”的应用。
首先在 Apple 的官方文档中内存主要分为以下几类。
- Free Memory 当前空闲的memory
- Used Mamory 当前正在使用的内存
我们最关心的当然是 Used Memory,它又分为以下几类。
- Wired Memory。 一般是内核占用的常驻内存,比如可执行文件的镜像 Image,内核所有的数据等,无法释放,在OS运行期间必须常驻内存。
- Active Memory 活跃的内存,当前正在使用的内存.
- Inactive Memory。不活跃的内存,最近用过,但是现在不怎么用了,按照局部性原则可以被置换出物理内存的内存。
- Purgeable Memory。可释放的内存,通常在Foundation中是
NSDiscardableContent的子类,或者是NSCache等。
等等。上面说的好像跟没说一样/(ㄒoㄒ)/~。我们换种方式从物理内存和虚拟内存的层面来解释。
首先我们的虚拟内存使用的是Page来描述的。 一个Page 有两种状态 Dirty 和 Clean。在iOS中Clean是可以被回收的。
Virtual Memory分类
- Clean Memory 主要包括 system framework、binary executable 、memory mapped files
- Dirty Memory 括Heap allocation、caches、decompressed images等。
(每个进程拥有一份独立的 Virtual memory pace)Virtual Memory = clean Memory
PhySical Memory
物理内存是指真正加载在主存中的内存,所以实际了解上真正的物理内存占用才对我们内存管理帮助更大。
- DirtyMemory
- Clean Memory but loaded。
- Page Table
- ComPressed memory
- IOKit Used
- Purgeable
内存测量工具
了解到前面说的内存分类之后我们应该怎么测量我们的内存分布呢。主要有几种工具,命令行工具,Xcode工具,代码工具等。
命令行工具
如果你开发的是 Mac 程序,Mac OS 自带的有一下几种。
- top 程序
- heap 程序
- leaks 程序
- vmmap 程序
这些工具读者查看 Man Page 即可。
需要注意的是。以上工具分析的大多是虚拟内存,也就是说对于 桌面级程序更适合,但是对于iOS中没有交换空间,且拥有Jetsam监控程序的设备,可能还需要更精准的测量工具。
顺便提一句。一个堆区上malloc的程序如果并没有使用,虽然它是Clean的,但是也会被程序统计到,理论上 malloc 可以申请到的虚拟内存大小非常接近 virtual Memory Space 的大小(这么说的原因是 前文也提到了 malloc 实际上是动态分配器程序提供的一些列函数,为了性能,大多数动态分配器都讲堆分为好几块用来做不同大小虚拟内存的管理,因此malloc可以申请到的虚拟内存大小实际决定于动分配器代码的实现。有兴趣的读者可以读一下。)
Xcode 提供的工具
- Xcode Debug Area
- Instruments
- DebugMemoryGraph
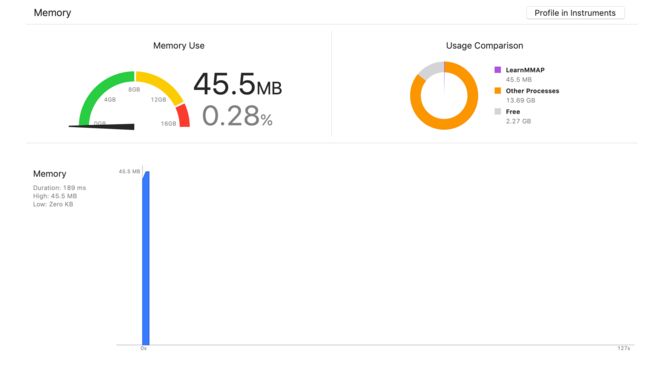
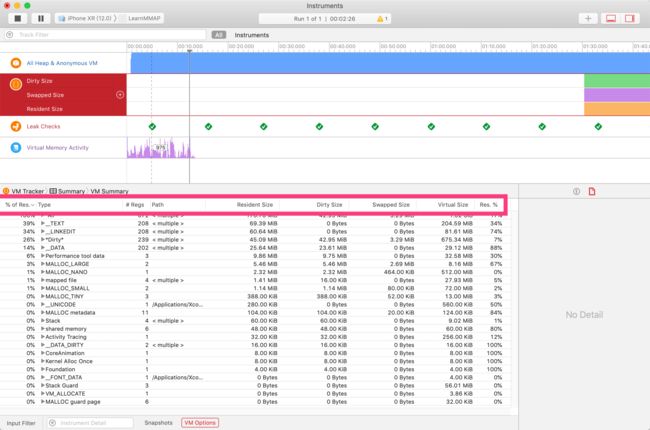

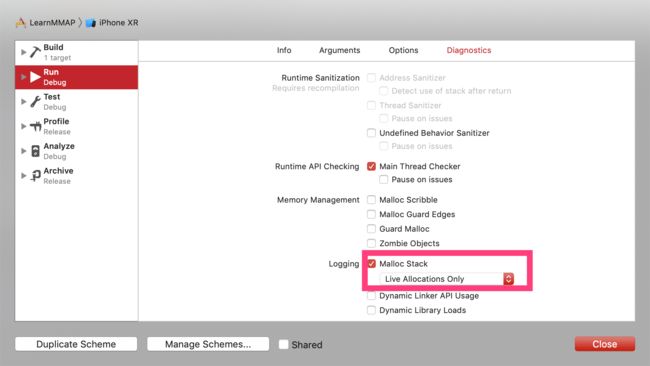
Tips 配置了 MallocStackLogging 的话甚至可以追踪每个 虚拟内存中的对象申请堆栈,便于我们更好的发现问题。
注意点:所有Xcode提供的工具必须使用真机测试才能最难接近用户的使用环境
代码工具
我们通过开发工具可以用来测量我们的内存,但是到了线上这些都用不了,能精准的测量APP用到的物理内存才比较重要。
大部分的代码测量内存是通过拿到Mach内核提供的 task_info 来测量的,但是这个信息更多的是虚拟内存层面的信息不能正确的衡量物理内存。
#include
#include
#include
int main(int argc, char * argv[]) {
@autoreleasepool {
// method 1
struct mstats currentStat = mstats();
printf("Freed Bytes:%ld, Used Bytes:%ld Total Bytes:%ld", currentStat.bytes_free, currentStat.bytes_used, currentStat.bytes_total);
// method 2
vm_statistics_data_t vmStats;
mach_msg_type_number_t infoCount = HOST_VM_INFO_COUNT;
kern_return_t kernReturn = host_statistics(mach_host_self(), HOST_VM_INFO, (host_info_t)&vmStats, &infoCount);
printf("free: %lu\nactive: %lu\ninactive: %lu\nwire: %lu\nzero fill: %lu\nreactivations: %lu\npageins: %lu\npageouts: %lu\nfaults: %u\ncow_faults: %u\nlookups: %u\nhits: %u",
vmStats.free_count * vm_page_size,
vmStats.active_count * vm_page_size,
vmStats.inactive_count * vm_page_size,
vmStats.wire_count * vm_page_size,
vmStats.zero_fill_count * vm_page_size,
vmStats.reactivations * vm_page_size,
vmStats.pageins * vm_page_size,
vmStats.pageouts * vm_page_size,
vmStats.faults,
vmStats.cow_faults,
vmStats.lookups,
vmStats.hits
);
// method3
task_basic_info_data_t taskInfo;
infoCount = TASK_BASIC_INFO_COUNT;
kernReturn = task_info(mach_task_self(),
TASK_BASIC_INFO,
(task_info_t)&taskInfo,
&infoCount);
if (kernReturn == KERN_SUCCESS) {
printf("resdientSize is :%ld", taskInfo.resident_size);
}
return 0;
}
}
其中尤其是和Xcode Debug Area的差距较大有时候可能会偏差 50M-100M ,于是有大佬拔出了Xcode 的 DebugServer 和 WebKit 中的的物理内存计算方式(2018WWDC 苹果也说了 footPrint才是真正的物理内存使用ios_memory_deep_dive)
代码如下
std::optional memoryFootprint()
{
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t result = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count);
if (result != KERN_SUCCESS)
return std::nullopt;
return static_cast(vmInfo.phys_footprint);
}
线上检查工具
线上检查内存通常会检查内存泄漏,一般有开源的工具
- MLeaksFinder
- FBRetainCycleDetector
高性能使用内存
了解完那么多原理和分析的工具,那么在日常使用中有没有什么指导原则可以帮助我们来写出更快,内存占用更低的代码呢?
- 首先熟读 ARCMenual ,大部分iOS开发者其实是完全不清楚ARC是怎么实现的,还有相对于的原则,尤其是Autorelease 修饰的指针,还有在多线程情况下的原则。
- 用weak修饰替换unsafe_unretain
- 使用weak strong dance 来解决block中的循环引用问题。需要注意的是大部分人都以为使用了weak指针就可以了。其实不然,在block内必须使用 strong 重新绑定变量,避免在多线程情况下weak变量为空导致Crash,使用strong指针前判断是否为空
例:
- (void)test {
weak __typeof(self) weakSelf = self;
[xxobjc onCompleate:^(){
strong __typeof(self) self = weakSelf;
if (!self) { return; }
[xx moreCompleate:&(){
strong __typeof(self) self = weakSelf;
if (!self) { return; }
// do something
}];
}];
}
- 小心方法中的self,在Objective-C的方法中 隐含的 self 是 __unsafed_unretain的。
- 使用Autoreleasepool来降低循环中的内存峰值,避免OOM。
- 要处理 Memory Warning
- C/C++ new 出来的要delete malloc 的要 free。
- UITableView/UICollectionView 的重用(不单单是cell重用 cell 使用的子view也要重用。
- [UIImage imageNamed:] 适合于UI界面中的贴图的读取,较大的资源文件应该尽量避免使用。
- WKWebView是跨进程通信的,不会占用我们的APP使用的物理内存量。
- try_catch_finally 一定要清理资源
- 尽量少引用
performaSelector:会对ARC的内存管理产生错误,导致内存泄漏。 - lazy load 那些大的内存对象, 尤其是需要保证线程安全,可以参考 java中的懒汉式Double Check 写法。
- 需要在收到内存警告的时候释放的Cache 用 NSCache 代替 NSDictionary, 使用 NSPurgableData代替NSData.
前文中我们说到iOS的没有交换分区的概念,取而代之的是压缩内存的办法,倘若在使用NSDictionary的时候收到内存警告,然后去释放这个NSDictionary,如果占据的内存过大,很可能在解压的过程中就被JetSem Kill 掉,如果你的内存只是误用的缓存或者是可重建的数据,就把NSCache当初NSDictionary用吧。同理 NSPurableData也是。
- 不要使用像素过大的图片文件,即便一个图片在磁盘中很小,但是因为图片像素宽高很大也会占据更多的内存,这里有个公式可以计算
widthPx * HeightPx * 4Bytes per pixel(alpha red green blue).即便在iOS12中已经可以优化单色图的内存占用,可毕竟是iOS12,现在好多公司还在支持iOS8 ~~ - 使用 NSData和UIImage 的 mmap加载选型来加载那些可以被重建的数据。
- 在子线程手动申请(maloc)大内存的的时候ping一下主线程,因为子线程无法收到内存警告的传递
- (void)test {
// current on sub Thread
// if main thread is memory warning it will blocked
dispatch_sync(dispatch_get_main_queue(), ^{
[some description]
});
malloc(huge memory);
}
参考
- 深入理解计算机系统
- 高性能iOS应用开发
- iOS和macOS性能优化:Cocoa、Cocoa Touch、Objective-C和Swift
- WWDC iOS Memory Deep Dive
- C++实现一个简易的内存池分配器
- ARC的参考文档
- whats_new_in_llvm
- 先弄清楚这里的学问,再来谈 iOS 内存管理与优化(一)
- 先弄清楚这里的学问,再来谈 iOS 内存管理与优化(二)
- 让人懵逼的 iOS 系统内存分配问题
- 探索iOS内存分配
- iOS内存深入探索之VM Tracker
- iOS内存深入探索之Leaks
- iOS内存深入探索之内存用量
- iOS笔记-记录一次内存泄漏发现过程
- iOS 内存管理及优化
- Memory Usage Performance Guidelines
- Performance Overview
- Debugging with Xcode
- Threading Programming Guide
- LLDB Quick Start Guide
- LLDB Debugging Guide
- Instruments Help Topics
- Advanced Memory Management Programming Guide
- Exception Programming Topics
- 小试Xcode逆向:app内存监控原理初探
- osfmk/kern/task.c
- MacOSX/MachTask.mm
- No pressure, Mon!
写在最后
现在做 iOS 开发太难了