搭建zookeeper集群(一主两从)
zk启动依赖java的JDK,所以要先安装JDK
不会安装JDK的可以看这https://www.jianshu.com/p/ea5c72b273d7教程,安装完成JDK后
下载zk的tar包并使用winSCP上传到3台linux服务器
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
开始搭建zookeeper集群(一主两从)
我启动了3台linux服务器,IP分别是
192.168.79.135、192.168.79.136、192.168.79.135
操作192.168.79.135服务器
执行linux命令解压zk
tar -zxvf zookeeper-3.4.14.tar.gz
解压后多了zookeeper-3.4.14文件夹,进行到zk的conf目录
cd zookeeper-3.4.14/conf/
可以查看到zoo_sample.cfg配置文件,把这个配置文件copy一份并重命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
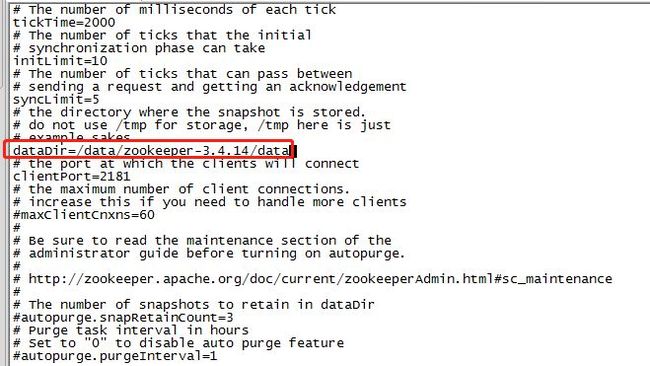
修改zoo.cfg配置文件的日志目录datadir(后面创建myid要在这个目录下)
vi zoo.cfg
启动看是否安装正常,在zookeeper-3.4.14目录执行
启动
bin/zkServer.sh start
查看是否启动成功
ps -ef|grep zookeeper或者netstat -nltp | grep 2181查看是否启动成功

检查启动成功
先关闭zk
bin/zkServer.sh stop
另外两台服务器也执行以上同样的操作↑
以上操作安装好单机的zk,现在开始搭建zk集群 一leader两follower
三台****服务器都修改配置文件
1.打开配置文件,
vi zoo.cfg
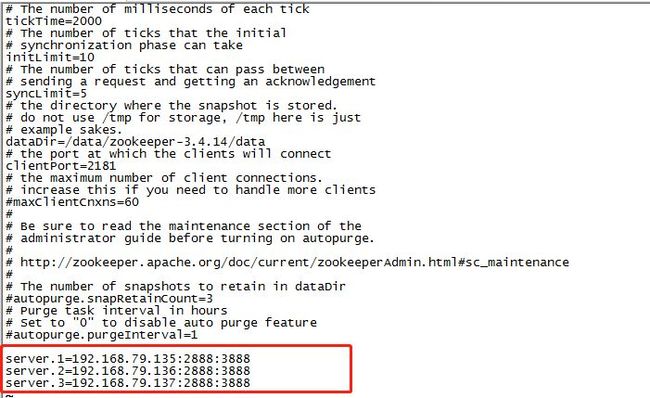
****2.在最后加上****
server.1=192.168.79.135:2888:3888
server.2=192.168.79.136:2888:3888
server.3=192.168.79.137:2888:3888
三台机器都修改完配置后
操作192.168.79.135服务器
在之前配置的dataDir目录(我配置在这个目录下/data/zookeeper-3.4.14/data),第一次zk就会创建这个目录(也可以手动创建),在这个目录下新建myid文本
vi myid
文本里面写上 **** 1

保存
wq!
操作192.168.79.136服务器
也是在dataDir(日志目录)下创建myid文本****
vi myid
文本里面写上 **** 2

操作192.168.79.137服务器
也是在dataDir(日志目录)下创建myid文本****
vi myid
文本里面写上 **** 3
配置完成后,关闭防火墙systemctl stop firewalld
启动3台服务器的zk,启动后
./zkServer.sh status查询zk节点
192.168.79.135节点信息Mode: leader

192.168.79.136节点信息Mode: follower

192.168.79.137节点信息Mode: follower

第一次启动,myid最小的选举为leader
下面操作看创建节点之后,其他zk就否会同步
bin/zkCli.sh ****启动zk客户端
ls /****查询zk根目录下的节点
在192.168.79.135创建一个node1节点,看其他zk节点是否能同步
create /node1 1
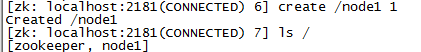
查询192.168.79.136的zk节点服务
查询192.168.79.137的zk节点服务
192.168.79.136的zk创建node2节点,发现followerzk也能创建节点,并且其他zk也都能同步数据。
**kill 192.168.79.135的zk后,192.168.79.137的zk选举成了leader
我们在192.168.79.137创建一个node3节点再重新启动192.168.79.135的zk

重启后变成了follower节点
******在zk重启之前创建的node3节点也能同步过来******
******3台zk如果挂掉一台还能正常使用,如果挂掉2台,正常的那台zk也不能使用了,要等其中至少1台zk启动后才能恢复正常(必须要一半或以上的zk服务正常才能运行)。******
测试:
将两台follower关闭
./zkServer.sh stop
查询没有关闭的zk(leader)的status状态,发现not running,不能正常使用
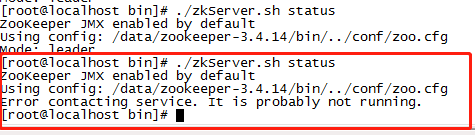
现在恢复启动一台刚刚关闭的zk
再查询没有关闭的zk(leader)的status状态
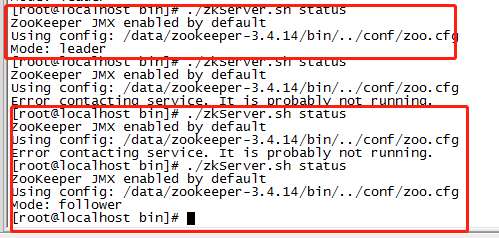
发现从leader变成了follower
**测试完成。结论:集群必须要一半或以上的zk服务正常才能运行集群,并且最后一台没有挂掉的如果是leader,集群恢复正常后,可能就不是leader了
测试集群搭建成功
下面说说集合的配置作用:
server.1=192.168.79.135:2888:3888的意思
****server.id=host:port1:port2****
id 是一个数字,表示这个是第几号服务器(与myid的值相同)。
****host ****是这个服务器的 ip 地址。**
****port1 ******表示这个服务器与集群中的Leader服务器交换信息的端口。**
****port2******表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。**
****myid文件******该文件创建在zoo.cfg里dataDir指定的目录下,只有一行内容,对应每台机器的Server ID 数字;比如server.1 的myid 文件内容就是1【必须确保每个服务器的myid 文件中的数字不同,并且****和自己所在机器的zoo.cfg 中server.id 的id 值一致,id 的范围是1~255】
集群角色
**Leader 角色 **
Leader 服务器是整个 zookeeper 集群的核心,主要的工作 任务有两项 1. 事物请求的唯一调度和处理者,保证集群事物处理的顺 序性
2. 集群内部各服务器的调度者
**Follower 角色 **
Follower 角色的主要职责是
1. 处理客户端非事物请求、转发事物请求给 leader 服务器
2. 参与事物请求 Proposal 的投票(需要半数以上服务器 通过才能通知 leader commit 数据; Leader 发起的提案, 要求 Follower 投票)
3. 参与 Leader 选举的投票
**Observer 角色 **
Observer 是 zookeeper3.3 开始引入的一个全新的服务器 角色,从字面来理解,该角色充当了观察者的角色。 观察 zookeeper 集群中的最新状态变化并将这些状态变化 同步到 observer 服务器上。Observer 的工作原理与 follower 角色基本一致,而它和 follower 角色唯一的不同 在于 observer 不参与任何形式的投票,包括事物请求 Proposal的投票和leader选举的投票。简单来说,observer 服务器只提供非事物请求服务,通常在于不影响集群事物 处理能力的前提下提升集群非事物处理的能力 。
*集群组成 **
通常 zookeeper是由2n+1台server组成,每个server都知道彼此的存在。对于2n+1台server,只要有n+1台(大多数server可用,整个系统保持可用。我们已经了解到,一个 zookeeper 集群如果要对外提供可用的服务,那么集 群中必须要有过半的机器正常工作并且彼此之间能够正常 通信,基于这个特性,如果搭建一个能够允许F台机器down掉的集群,那么就要部署2F+1台服务器构成的 zookeeper 集群。因此3台机器构成的 zookeeper 集群,能够在挂掉一台机器后依然正常工作。一个5 台机器集群 的服务,能够对2台机器挂掉的情况下进行容灾。如果一台由6台服务构成的集群,同样只能挂掉2台机器。因此,5台和6台在容灾能力上并没有明显优势,反而增加了网络通信负担。系统启动时,集群中的server 会选举出一台server为Leader,其它的就作为follower(这里先不考虑 observer角色)。
之所以要满足这样一个等式,是因为一个节点要成为集群中的leader,需要有超过及群众过半数的节点支持,这个涉及到leader选举算法。同时也涉及到事务请求的提交投票
zookeeper的集群工作
在zookeeper中,客户端会随机连接到zookeeper集群中的一个节点,****如果是读请求,就直接从当前节点中读取数据,如果是写请求,那么请求会被转发给 leader 提交事务,然后 leader 会广播事务,只要有超过半数节点写入成功,那么写请求就会被提交(类 2PC 事务)所有事务请求必须由一个全局唯一的服务器来协调处理****,这个服务器就是Leader服务器,其他的服务器就是follower。
leader服务器把客户端的失去请求转化成一个事务Proposal(提议),并把这个Proposal分发给集群中的所有 Follower 服务器。之后Leader服务器需要等待所有Follower 服务器的反馈,****一旦超过半数的 Follower 服务器 进行了正确的反馈,那么 Leader 就会再次向所有的 Follower 服务器发送 Commit 消息****,要求各个 follower 节点对前面的一个 Proposal 进行提交;**
即刻关注,掂过柱碌

